Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-augmented Attention Modelling for Videos
Paper and Code
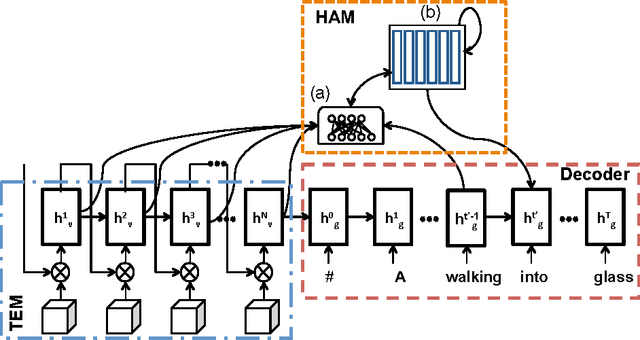
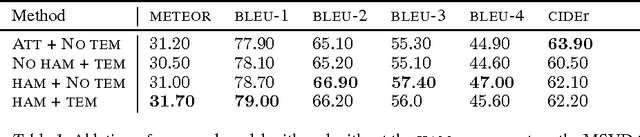


We present a method to improve video description generation by modeling higher-order interactions between video frames and described concepts. By storing past visual attention in the video associated to previously generated words, the system is able to decide what to look at and describe in light of what it has already looked at and described. This enables not only more effective local attention, but tractable consideration of the video sequence while generating each word. Evaluation on the challenging and popular MSVD and Charades datasets demonstrates that the proposed architecture outperforms previous video description approaches without requiring external temporal video features.
* Revised version, minor changes, add the link for the source codes
View paper on
 OpenReview
OpenReview