 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-training Quantization with Multiple Points: Mixed Precision without Mixed Precision
Feb 24, 2020


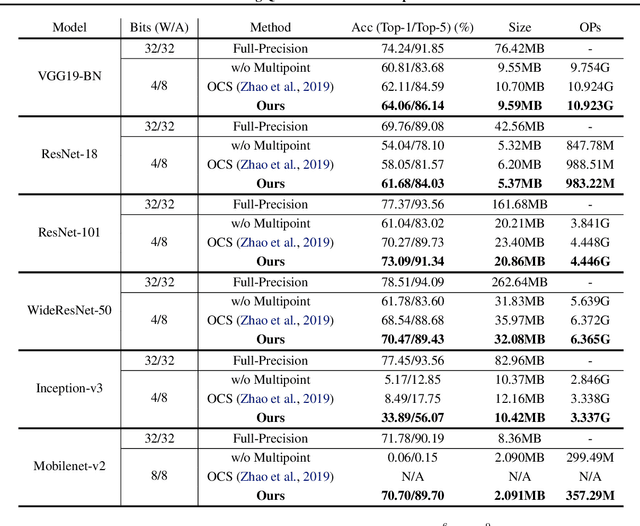
We consider the post-training quantization problem, which discretizes the weights of pre-trained deep neural networks without re-training the model. We propose multipoint quantization, a quantization method that approximates a full-precision weight vector using a linear combination of multiple vectors of low-bit numbers; this is in contrast to typical quantization methods that approximate each weight using a single low precision number. Computationally, we construct the multipoint quantization with an efficient greedy selection procedure, and adaptively decides the number of low precision points on each quantized weight vector based on the error of its output. This allows us to achieve higher precision levels for important weights that greatly influence the outputs, yielding an 'effect of mixed precision' but without physical mixed precision implementations (which requires specialized hardware accelerators). Empirically, our method can be implemented by common operands, bringing almost no memory and computation overhead. We show that our method outperforms a range of state-of-the-art methods on ImageNet classification and it can be generalized to more challenging tasks like PASCAL VOC object detection.
Doubly Robust Bias Reduction in Infinite Horizon Off-Policy Estimation
Oct 16, 2019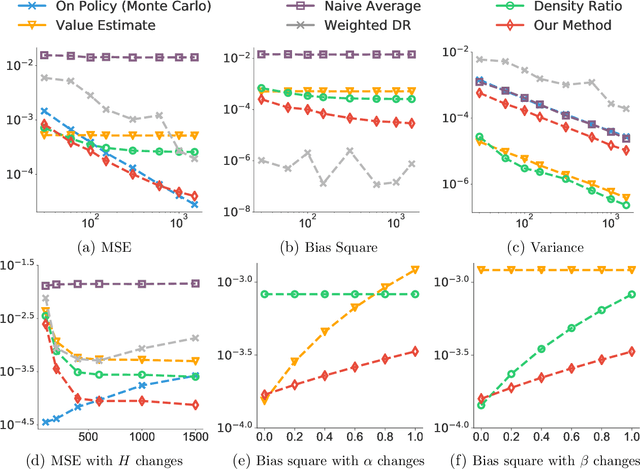
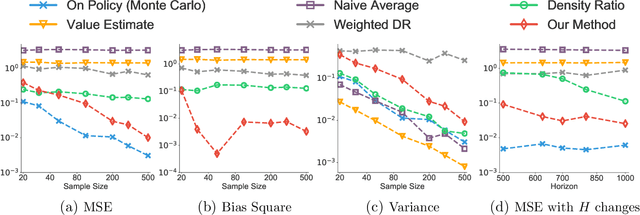
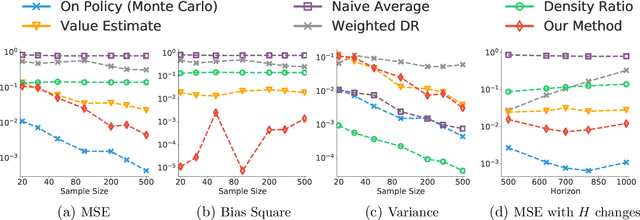
Infinite horizon off-policy policy evaluation is a highly challenging task due to the excessively large variance of typical importance sampling (IS) estimators. Recently, Liu et al. (2018a) proposed an approach that significantly reduces the variance of infinite-horizon off-policy evaluation by estimating the stationary density ratio, but at the cost of introducing potentially high biases due to the error in density ratio estimation. In this paper, we develop a bias-reduced augmentation of their method, which can take advantage of a learned value function to obtain higher accuracy. Our method is doubly robust in that the bias vanishes when either the density ratio or the value function estimation is perfect. In general, when either of them is accurate, the bias can also be reduced. Both theoretical and empirical results show that our method yields significant advantages over previous methods.
Neural Phrase-to-Phrase Machine Translation
Nov 06, 2018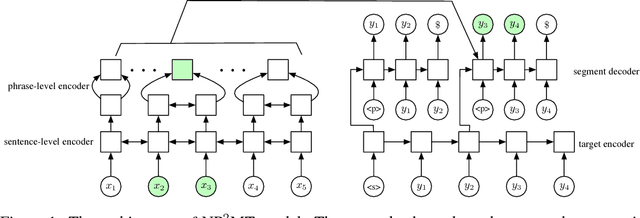


In this paper, we propose Neural Phrase-to-Phrase Machine Translation (NP$^2$MT). Our model uses a phrase attention mechanism to discover relevant input (source) segments that are used by a decoder to generate output (target) phrases. We also design an efficient dynamic programming algorithm to decode segments that allows the model to be trained faster than the existing neural phrase-based machine translation method by Huang et al. (2018). Furthermore, our method can naturally integrate with external phrase dictionaries during decoding. Empirical experiments show that our method achieves comparable performance with the state-of-the art methods on benchmark datasets. However, when the training and testing data are from different distributions or domains, our method performs better.
Breaking the Curse of Horizon: Infinite-Horizon Off-Policy Estimation
Oct 29, 2018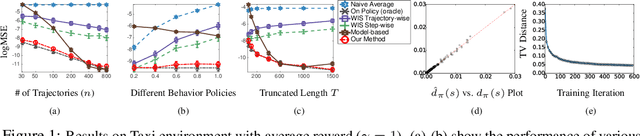
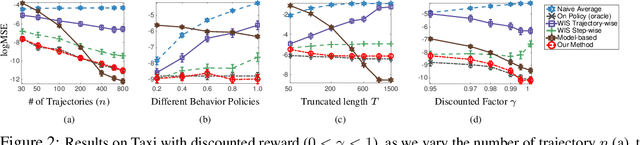
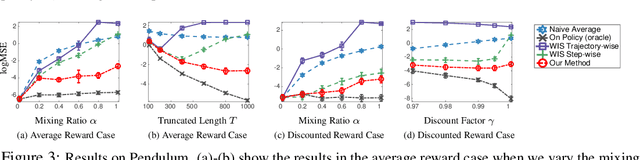

We consider the off-policy estimation problem of estimating the expected reward of a target policy using samples collected by a different behavior policy. Importance sampling (IS) has been a key technique to derive (nearly) unbiased estimators, but is known to suffer from an excessively high variance in long-horizon problems. In the extreme case of in infinite-horizon problems, the variance of an IS-based estimator may even be unbounded. In this paper, we propose a new off-policy estimation method that applies IS directly on the stationary state-visitation distributions to avoid the exploding variance issue faced by existing estimators.Our key contribution is a novel approach to estimating the density ratio of two stationary distributions, with trajectories sampled from only the behavior distribution. We develop a mini-max loss function for the estimation problem, and derive a closed-form solution for the case of RKHS. We support our method with both theoretical and empirical analyses.
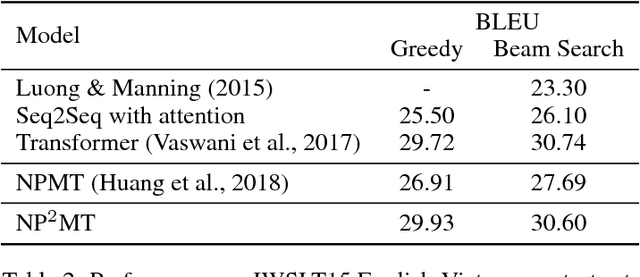
Towards Neural Phrase-based Machine Translation
Sep 24, 2018

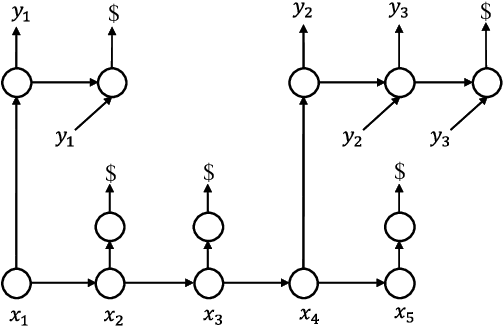

In this paper, we present Neural Phrase-based Machine Translation (NPMT). Our method explicitly models the phrase structures in output sequences using Sleep-WAke Networks (SWAN), a recently proposed segmentation-based sequence modeling method. To mitigate the monotonic alignment requirement of SWAN, we introduce a new layer to perform (soft) local reordering of input sequences. Different from existing neural machine translation (NMT) approaches, NPMT does not use attention-based decoding mechanisms. Instead, it directly outputs phrases in a sequential order and can decode in linear time. Our experiments show that NPMT achieves superior performances on IWSLT 2014 German-English/English-German and IWSLT 2015 English-Vietnamese machine translation tasks compared with strong NMT baselines. We also observe that our method produces meaningful phrases in output languages.
Sequence Modeling via Segmentations
Jul 18, 2018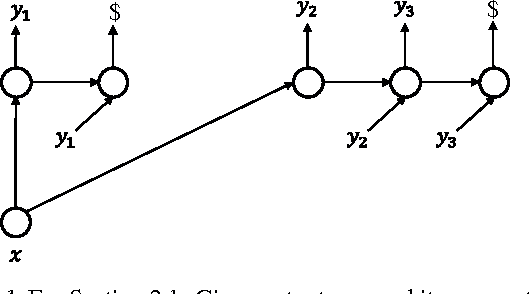
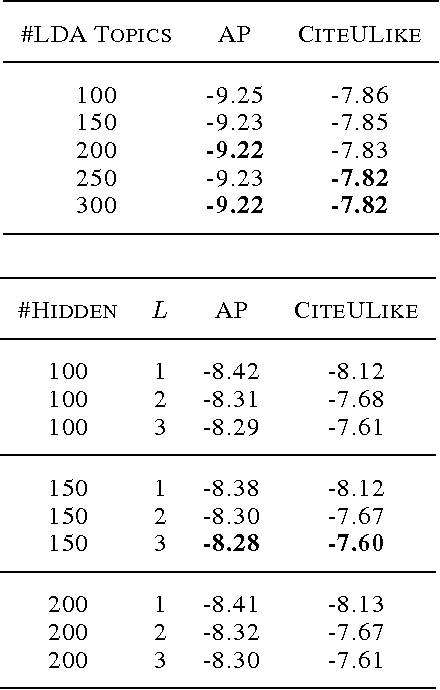
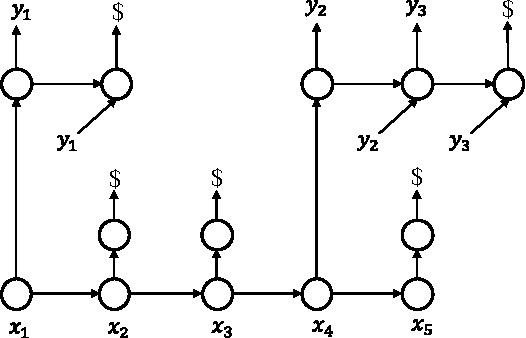

Segmental structure is a common pattern in many types of sequences such as phrases in human languages. In this paper, we present a probabilistic model for sequences via their segmentations. The probability of a segmented sequence is calculated as the product of the probabilities of all its segments, where each segment is modeled using existing tools such as recurrent neural networks. Since the segmentation of a sequence is usually unknown in advance, we sum over all valid segmentations to obtain the final probability for the sequence. An efficient dynamic programming algorithm is developed for forward and backward computations without resorting to any approximation. We demonstrate our approach on text segmentation and speech recognition tasks. In addition to quantitative results, we also show that our approach can discover meaningful segments in their respective application contexts.
On the Discrimination-Generalization Tradeoff in GANs
Feb 23, 2018

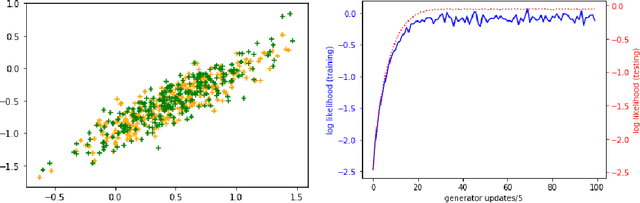

Generative adversarial training can be generally understood as minimizing certain moment matching loss defined by a set of discriminator functions, typically neural networks. The discriminator set should be large enough to be able to uniquely identify the true distribution (discriminative), and also be small enough to go beyond memorizing samples (generalizable). In this paper, we show that a discriminator set is guaranteed to be discriminative whenever its linear span is dense in the set of bounded continuous functions. This is a very mild condition satisfied even by neural networks with a single neuron. Further, we develop generalization bounds between the learned distribution and true distribution under different evaluation metrics. When evaluated with neural distance, our bounds show that generalization is guaranteed as long as the discriminator set is small enough, regardless of the size of the generator or hypothesis set. When evaluated with KL divergence, our bound provides an explanation on the counter-intuitive behaviors of testing likelihood in GAN training. Our analysis sheds lights on understanding the practical performance of GANs.
Action-depedent Control Variates for Policy Optimization via Stein's Identity
Feb 23, 2018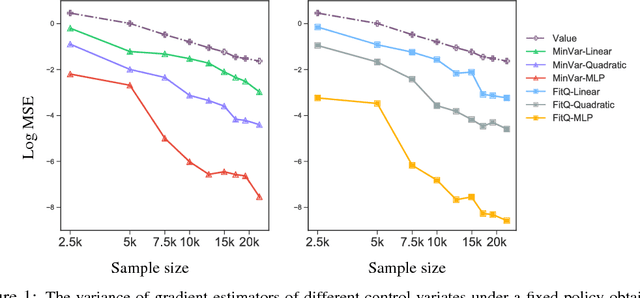


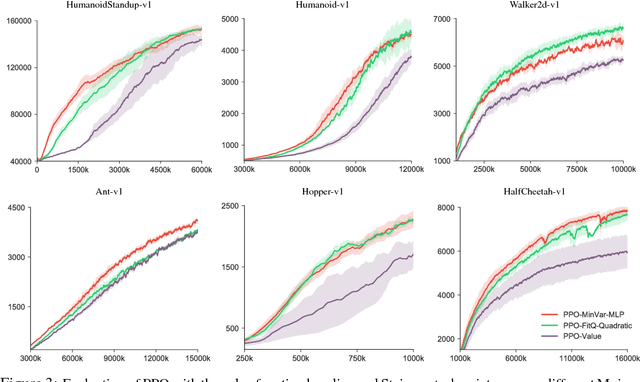
Policy gradient methods have achieved remarkable successes in solving challenging reinforcement learning problems. However, it still often suffers from the large variance issue on policy gradient estimation, which leads to poor sample efficiency during training. In this work, we propose a control variate method to effectively reduce variance for policy gradient methods. Motivated by the Stein's identity, our method extends the previous control variate methods used in REINFORCE and advantage actor-critic by introducing more general action-dependent baseline functions. Empirical studies show that our method significantly improves the sample efficiency of the state-of-the-art policy gradient approaches.
Provably Optimal Algorithms for Generalized Linear Contextual Bandits
Jun 18, 2017Contextual bandits are widely used in Internet services from news recommendation to advertising, and to Web search. Generalized linear models (logistical regression in particular) have demonstrated stronger performance than linear models in many applications where rewards are binary. However, most theoretical analyses on contextual bandits so far are on linear bandits. In this work, we propose an upper confidence bound based algorithm for generalized linear contextual bandits, which achieves an $\tilde{O}(\sqrt{dT})$ regret over $T$ rounds with $d$ dimensional feature vectors. This regret matches the minimax lower bound, up to logarithmic terms, and improves on the best previous result by a $\sqrt{d}$ factor, assuming the number of arms is fixed. A key component in our analysis is to establish a new, sharp finite-sample confidence bound for maximum-likelihood estimates in generalized linear models, which may be of independent interest. We also analyze a simpler upper confidence bound algorithm, which is useful in practice, and prove it to have optimal regret for certain cases.
Stochastic Variance Reduction Methods for Policy Evaluation
Jun 09, 2017
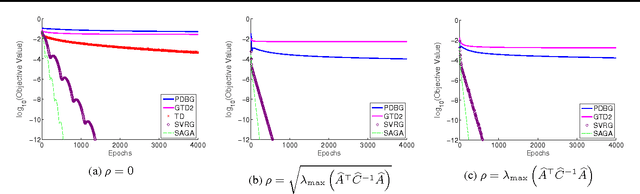
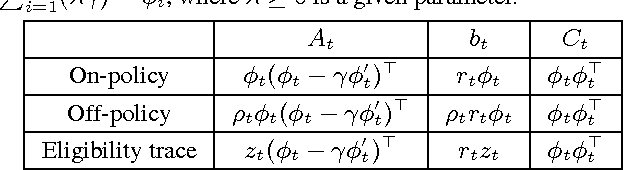
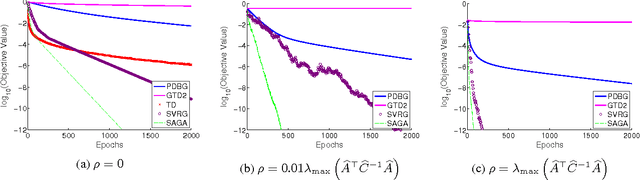
Policy evaluation is a crucial step in many reinforcement-learning procedures, which estimates a value function that predicts states' long-term value under a given policy. In this paper, we focus on policy evaluation with linear function approximation over a fixed dataset. We first transform the empirical policy evaluation problem into a (quadratic) convex-concave saddle point problem, and then present a primal-dual batch gradient method, as well as two stochastic variance reduction methods for solving the problem. These algorithms scale linearly in both sample size and feature dimension. Moreover, they achieve linear convergence even when the saddle-point problem has only strong concavity in the dual variables but no strong convexity in the primal variables. Numerical experiments on benchmark problems demonstrate the effectiveness of our methods.