 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Variance Reduction Methods for Policy Evaluation
Paper and Code
Jun 09, 2017
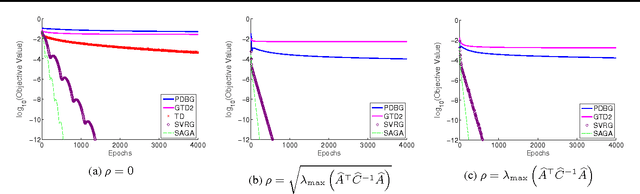
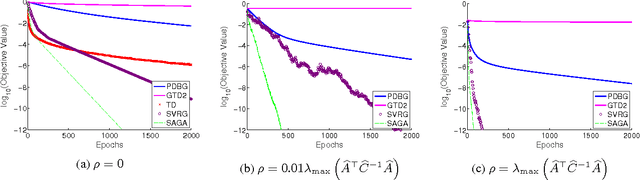
Policy evaluation is a crucial step in many reinforcement-learning procedures, which estimates a value function that predicts states' long-term value under a given policy. In this paper, we focus on policy evaluation with linear function approximation over a fixed dataset. We first transform the empirical policy evaluation problem into a (quadratic) convex-concave saddle point problem, and then present a primal-dual batch gradient method, as well as two stochastic variance reduction methods for solving the problem. These algorithms scale linearly in both sample size and feature dimension. Moreover, they achieve linear convergence even when the saddle-point problem has only strong concavity in the dual variables but no strong convexity in the primal variables. Numerical experiments on benchmark problems demonstrate the effectiveness of our methods.