 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Revise References for Faithful Summarization
Paper and Code

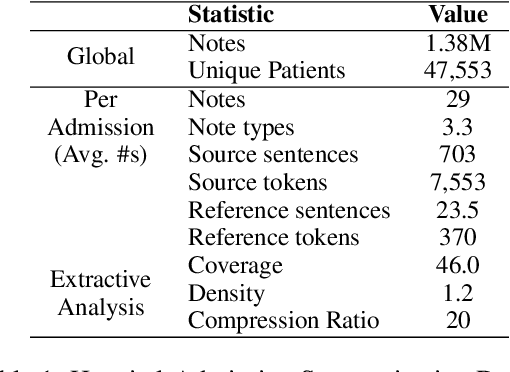
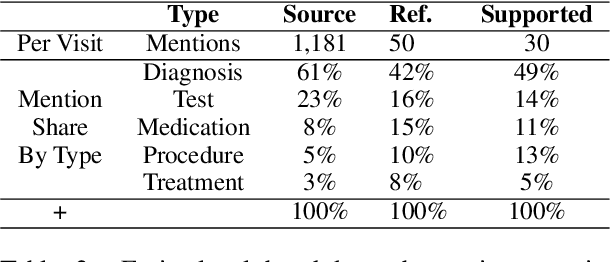

In many real-world scenarios with naturally occurring datasets, reference summaries are noisy and contain information that cannot be inferred from the source text. On large news corpora, removing low quality samples has been shown to reduce model hallucinations. Yet, this method is largely untested for smaller, noisier corpora. To improve reference quality while retaining all data, we propose a new approach: to revise--not remove--unsupported reference content. Without ground-truth supervision, we construct synthetic unsupported alternatives to supported sentences and use contrastive learning to discourage/encourage (un)faithful revisions. At inference, we vary style codes to over-generate revisions of unsupported reference sentences and select a final revision which balances faithfulness and abstraction. We extract a small corpus from a noisy source--the Electronic Health Record (EHR)--for the task of summarizing a hospital admission from multiple notes. Training models on original, filtered, and revised references, we find (1) learning from revised references reduces the hallucination rate substantially more than filtering (18.4\% vs 3.8\%), (2) learning from abstractive (vs extractive) revisions improves coherence, relevance, and faithfulness, (3) beyond redress of noisy data, the revision task has standalone value for the task: as a pre-training objective and as a post-hoc editor.