 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntity Anchored ICD Coding
Paper and Code
Aug 15, 2022
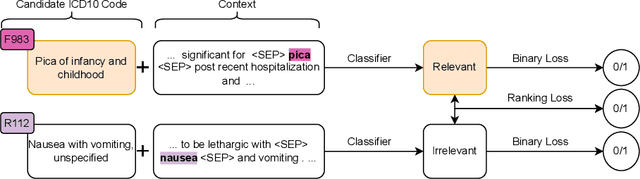
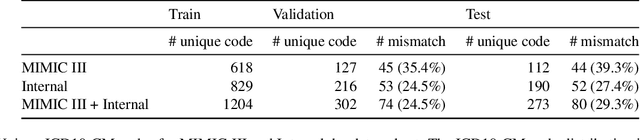

Medical coding is a complex task, requiring assignment of a subset of over 72,000 ICD codes to a patient's notes. Modern natural language processing approaches to these tasks have been challenged by the length of the input and size of the output space. We limit our model inputs to a small window around medical entities found in our documents. From those local contexts, we build contextualized representations of both ICD codes and entities, and aggregate over these representations to form document-level predictions. In contrast to existing methods which use a representation fixed either in size or by codes seen in training, we represent ICD codes by encoding the code description with local context. We discuss metrics appropriate to deploying coding systems in practice. We show that our approach is superior to existing methods in both standard and deployable measures, including performance on rare and unseen codes.