 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPEER: Sentence-Level Planning of Long Clinical Summaries via Embedded Entity Retrieval
Jan 04, 2024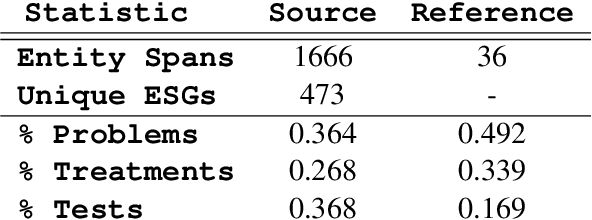

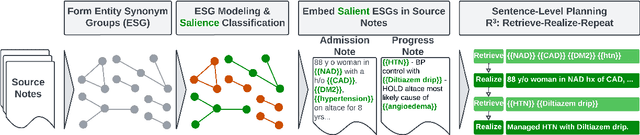

Clinician must write a lengthy summary each time a patient is discharged from the hospital. This task is time-consuming due to the sheer number of unique clinical concepts covered in the admission. Identifying and covering salient entities is vital for the summary to be clinically useful. We fine-tune open-source LLMs (Mistral-7B-Instruct and Zephyr-7B-\b{eta}) on the task and find that they generate incomplete and unfaithful summaries. To increase entity coverage, we train a smaller, encoder-only model to predict salient entities, which are treated as content-plans to guide the LLM. To encourage the LLM to focus on specific mentions in the source notes, we propose SPEER: Sentence-level Planning via Embedded Entity Retrieval. Specifically, we mark each salient entity span with special "{{ }}" boundary tags and instruct the LLM to retrieve marked spans before generating each sentence. Sentence-level planning acts as a form of state tracking in that the model is explicitly recording the entities it uses. We fine-tune Mistral and Zephyr variants on a large-scale, diverse dataset of ~167k in-patient hospital admissions and evaluate on 3 datasets. SPEER shows gains in both coverage and faithfulness metrics over non-guided and guided baselines.
A Meta-Evaluation of Faithfulness Metrics for Long-Form Hospital-Course Summarization
Mar 07, 2023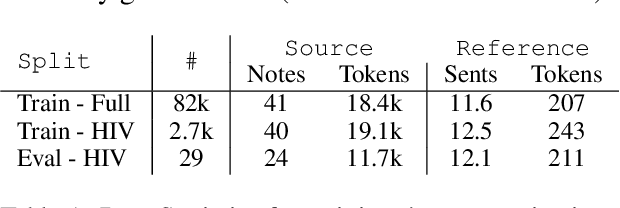
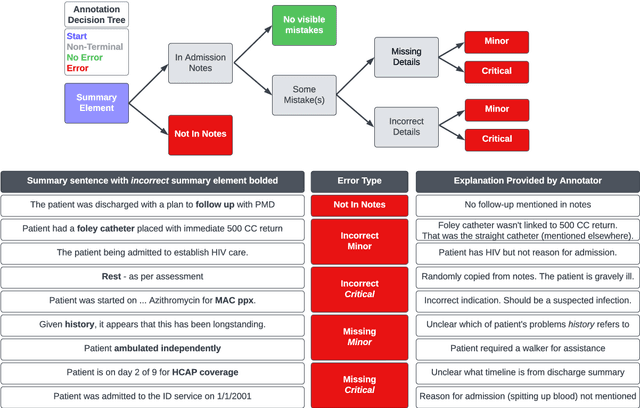
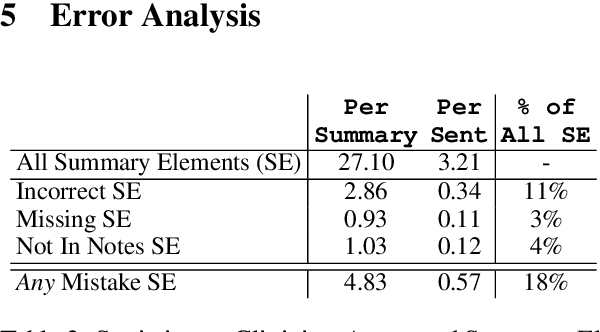
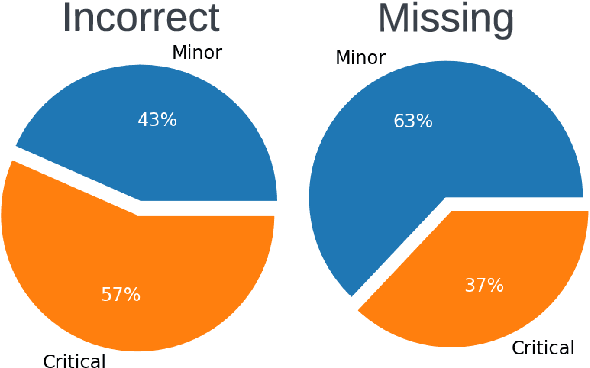
Long-form clinical summarization of hospital admissions has real-world significance because of its potential to help both clinicians and patients. The faithfulness of summaries is critical to their safe usage in clinical settings. To better understand the limitations of abstractive systems, as well as the suitability of existing evaluation metrics, we benchmark faithfulness metrics against fine-grained human annotations for model-generated summaries of a patient's Brief Hospital Course. We create a corpus of patient hospital admissions and summaries for a cohort of HIV patients, each with complex medical histories. Annotators are presented with summaries and source notes, and asked to categorize manually highlighted summary elements (clinical entities like conditions and medications as well as actions like "following up") into one of three categories: ``Incorrect,'' ``Missing,'' and ``Not in Notes.'' We meta-evaluate a broad set of proposed faithfulness metrics and, across metrics, explore the importance of domain adaptation (e.g. the impact of in-domain pre-training and metric fine-tuning), the use of source-summary alignments, and the effects of distilling a single metric from an ensemble of pre-existing metrics. Off-the-shelf metrics with no exposure to clinical text correlate well yet overly rely on summary extractiveness. As a practical guide to long-form clinical narrative summarization, we find that most metrics correlate best to human judgments when provided with one summary sentence at a time and a minimal set of relevant source context.
What's in a Summary? Laying the Groundwork for Advances in Hospital-Course Summarization
Apr 12, 2021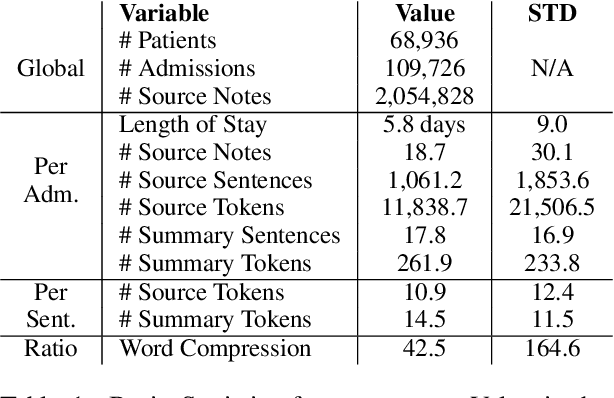
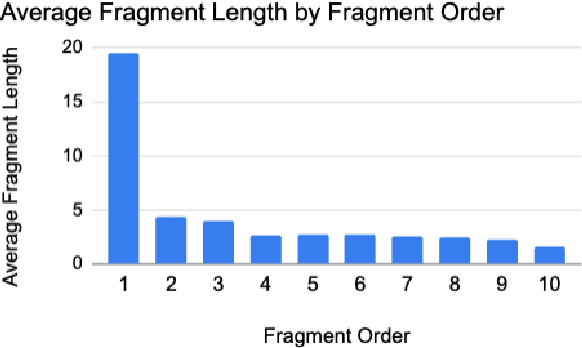
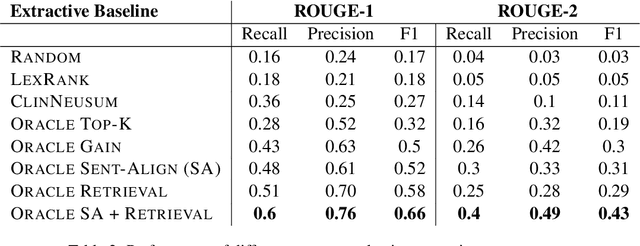
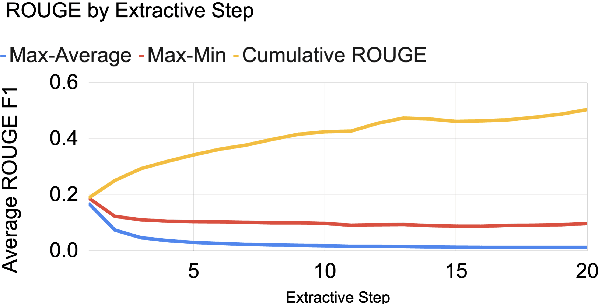
Summarization of clinical narratives is a long-standing research problem. Here, we introduce the task of hospital-course summarization. Given the documentation authored throughout a patient's hospitalization, generate a paragraph that tells the story of the patient admission. We construct an English, text-to-text dataset of 109,000 hospitalizations (2M source notes) and their corresponding summary proxy: the clinician-authored "Brief Hospital Course" paragraph written as part of a discharge note. Exploratory analyses reveal that the BHC paragraphs are highly abstractive with some long extracted fragments; are concise yet comprehensive; differ in style and content organization from the source notes; exhibit minimal lexical cohesion; and represent silver-standard references. Our analysis identifies multiple implications for modeling this complex, multi-document summarization task.
Towards Patient Record Summarization Through Joint Phenotype Learning in HIV Patients
Mar 09, 2020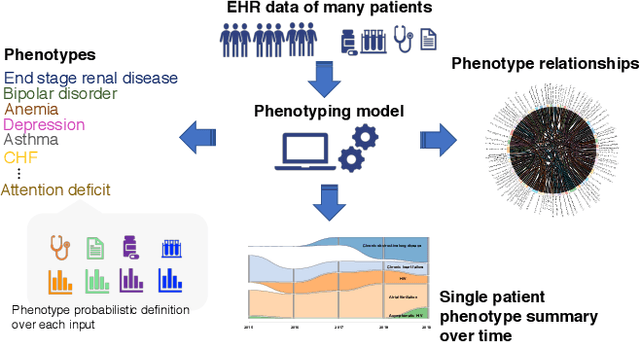


Identifying a patient's key problems over time is a common task for providers at the point care, yet a complex and time-consuming activity given current electric health records. To enable a problem-oriented summarizer to identify a patient's comprehensive list of problems and their salience, we propose an unsupervised phenotyping approach that jointly learns a large number of phenotypes/problems across structured and unstructured data. To identify the appropriate granularity of the learned phenotypes, the model is trained on a target patient population of the same clinic. To enable the content organization of a problem-oriented summarizer, the model identifies phenotype relatedness as well. The model leverages a correlated-mixed membership approach with variational inference applied to heterogenous clinical data. In this paper, we focus our experiments on assessing the learned phenotypes and their relatedness as learned from a specific patient population. We ground our experiments in phenotyping patients from an HIV clinic in a large urban care institution (n=7,523), where patients have voluminous, longitudinal documentation, and where providers would benefit from summaries of these patient's medical histories, whether about their HIV or any comorbidities. We find that the learned phenotypes and their relatedness are clinically valid when assessed qualitatively by clinical experts, and that the model surpasses baseline in inferring phenotype-relatedness when comparing to existing expert-curated condition groupings.