 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Patient Record Summarization Through Joint Phenotype Learning in HIV Patients
Mar 09, 2020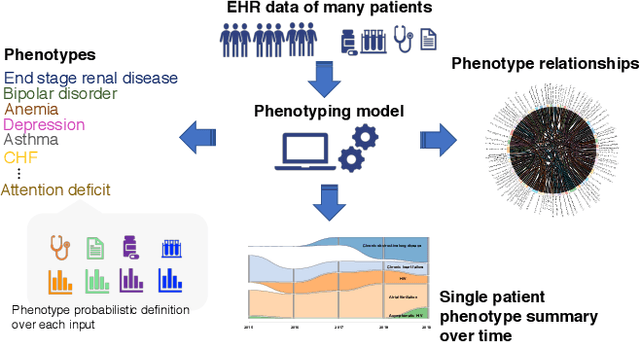


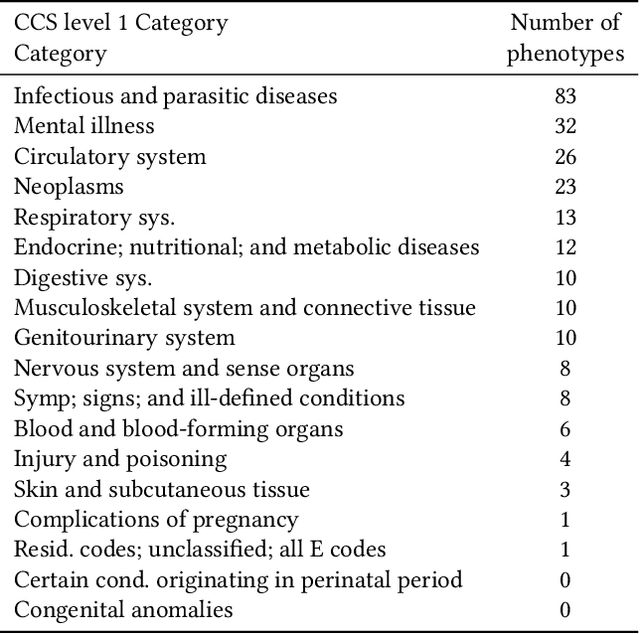
Identifying a patient's key problems over time is a common task for providers at the point care, yet a complex and time-consuming activity given current electric health records. To enable a problem-oriented summarizer to identify a patient's comprehensive list of problems and their salience, we propose an unsupervised phenotyping approach that jointly learns a large number of phenotypes/problems across structured and unstructured data. To identify the appropriate granularity of the learned phenotypes, the model is trained on a target patient population of the same clinic. To enable the content organization of a problem-oriented summarizer, the model identifies phenotype relatedness as well. The model leverages a correlated-mixed membership approach with variational inference applied to heterogenous clinical data. In this paper, we focus our experiments on assessing the learned phenotypes and their relatedness as learned from a specific patient population. We ground our experiments in phenotyping patients from an HIV clinic in a large urban care institution (n=7,523), where patients have voluminous, longitudinal documentation, and where providers would benefit from summaries of these patient's medical histories, whether about their HIV or any comorbidities. We find that the learned phenotypes and their relatedness are clinically valid when assessed qualitatively by clinical experts, and that the model surpasses baseline in inferring phenotype-relatedness when comparing to existing expert-curated condition groupings.
Machine Learning and Visualization in Clinical Decision Support: Current State and Future Directions
Jun 06, 2019
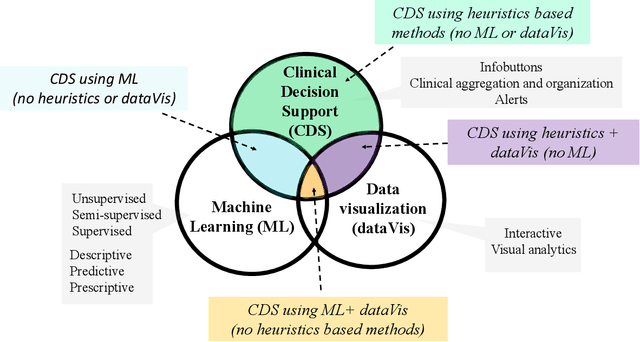
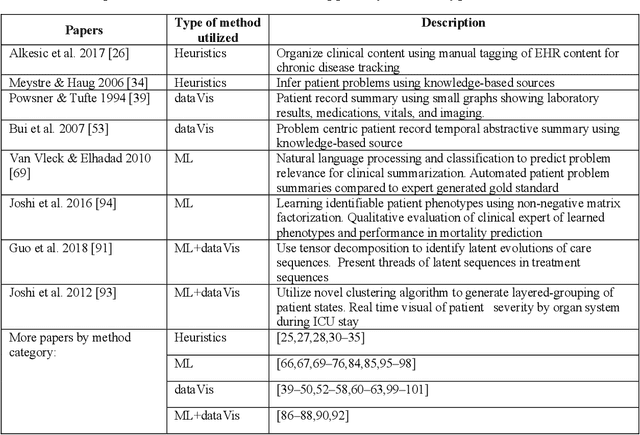
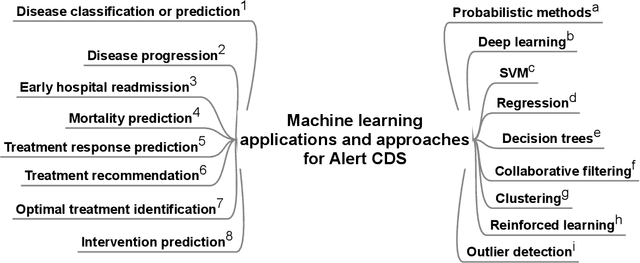
Deep learning, an area of machine learning, is set to revolutionize patient care. But it is not yet part of standard of care, especially when it comes to individual patient care. In fact, it is unclear to what extent data-driven techniques are being used to support clinical decision making (CDS). Heretofore, there has not been a review of ways in which research in machine learning and other types of data-driven techniques can contribute effectively to clinical care and the types of support they can bring to clinicians. In this paper, we consider ways in which two data driven domains - machine learning and data visualizations - can contribute to the next generation of clinical decision support systems. We review the literature regarding the ways heuristic knowledge, machine learning, and visualization are - and can be - applied to three types of CDS. There has been substantial research into the use of predictive modeling for alerts, however current CDS systems are not utilizing these methods. Approaches that leverage interactive visualizations and machine-learning inferences to organize and review patient data are gaining popularity but are still at the prototype stage and are not yet in use. CDS systems that could benefit from prescriptive machine learning (e.g., treatment recommendations for specific patients) have not yet been developed. We discuss potential reasons for the lack of deployment of data-driven methods in CDS and directions for future research.