 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan AI writing be salvaged? Mitigating Idiosyncrasies and Improving Human-AI Alignment in the Writing Process through Edits
Paper and Code
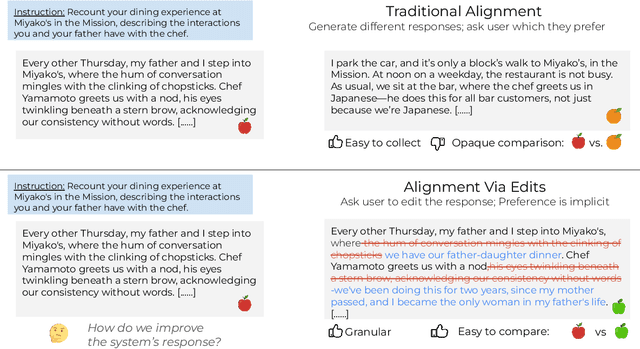
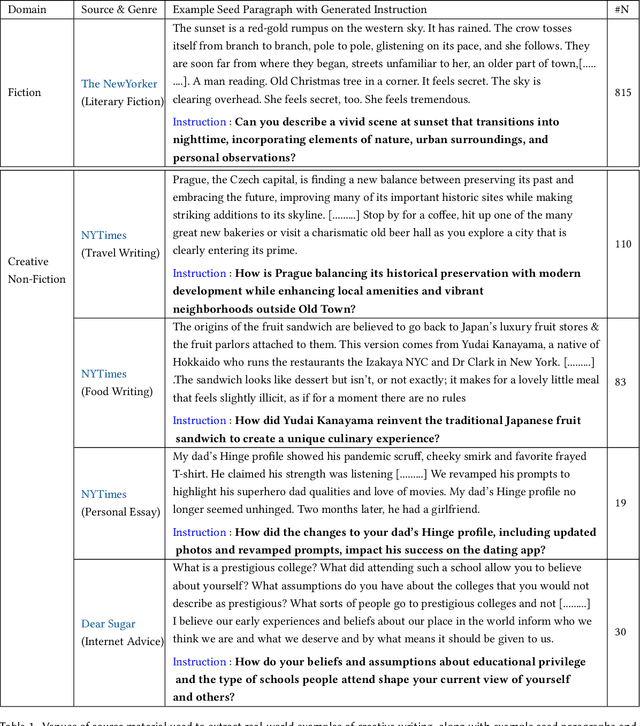
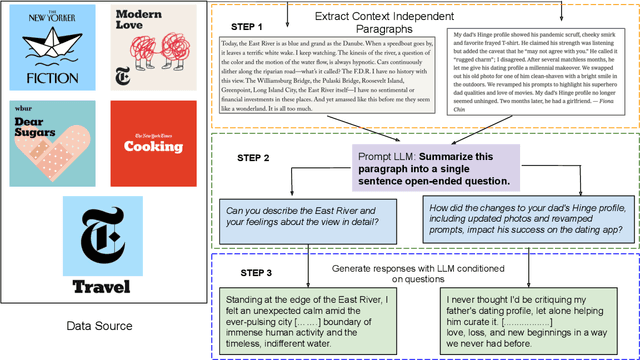
LLM-based applications are helping people write, and LLM-generated text is making its way into social media, journalism, and our classrooms. However, the differences between LLM-generated and human-written text remain unclear. To explore this, we hired professional writers to edit paragraphs in several creative domains. We first found these writers agree on undesirable idiosyncrasies in LLM-generated text, formalizing it into a seven-category taxonomy (e.g. cliches, unnecessary exposition). Second, we curated the LAMP corpus: 1,057 LLM-generated paragraphs edited by professional writers according to our taxonomy. Analysis of LAMP reveals that none of the LLMs used in our study (GPT4o, Claude-3.5-Sonnet, Llama-3.1-70b) outperform each other in terms of writing quality, revealing common limitations across model families. Third, we explored automatic editing methods to improve LLM-generated text. A large-scale preference annotation confirms that although experts largely prefer text edited by other experts, automatic editing methods show promise in improving alignment between LLM-generated and human-written text.