 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinTral: A Family of GPT-4 Level Multimodal Financial Large Language Models
Feb 16, 2024



We introduce FinTral, a suite of state-of-the-art multimodal large language models (LLMs) built upon the Mistral-7b model and tailored for financial analysis. FinTral integrates textual, numerical, tabular, and image data. We enhance FinTral with domain-specific pretraining, instruction fine-tuning, and RLAIF training by exploiting a large collection of textual and visual datasets we curate for this work. We also introduce an extensive benchmark featuring nine tasks and 25 datasets for evaluation, including hallucinations in the financial domain. Our FinTral model trained with direct preference optimization employing advanced Tools and Retrieval methods, dubbed FinTral-DPO-T&R, demonstrates an exceptional zero-shot performance. It outperforms ChatGPT-3.5 in all tasks and surpasses GPT-4 in five out of nine tasks, marking a significant advancement in AI-driven financial technology. We also demonstrate that FinTral has the potential to excel in real-time analysis and decision-making in diverse financial contexts.
Machine Generation and Detection of Arabic Manipulated and Fake News
Nov 05, 2020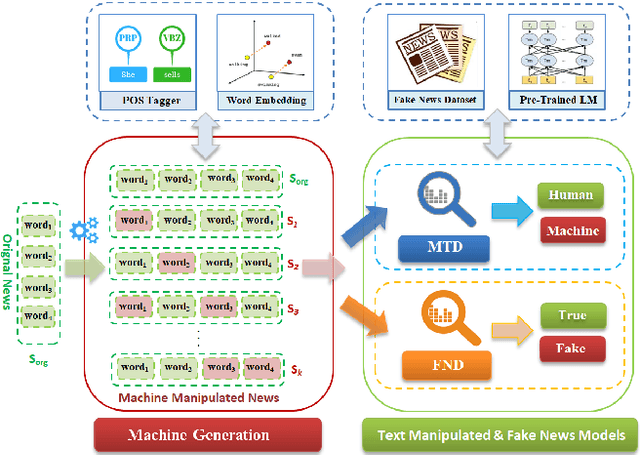
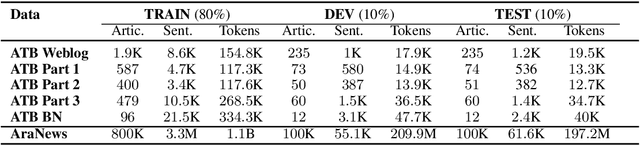
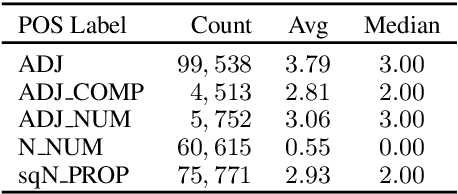
Fake news and deceptive machine-generated text are serious problems threatening modern societies, including in the Arab world. This motivates work on detecting false and manipulated stories online. However, a bottleneck for this research is lack of sufficient data to train detection models. We present a novel method for automatically generating Arabic manipulated (and potentially fake) news stories. Our method is simple and only depends on availability of true stories, which are abundant online, and a part of speech tagger (POS). To facilitate future work, we dispense with both of these requirements altogether by providing AraNews, a novel and large POS-tagged news dataset that can be used off-the-shelf. Using stories generated based on AraNews, we carry out a human annotation study that casts light on the effects of machine manipulation on text veracity. The study also measures human ability to detect Arabic machine manipulated text generated by our method. Finally, we develop the first models for detecting manipulated Arabic news and achieve state-of-the-art results on Arabic fake news detection (macro F1=70.06). Our models and data are publicly available.
Growing Together: Modeling Human Language Learning With n-Best Multi-Checkpoint Machine Translation
Jun 07, 2020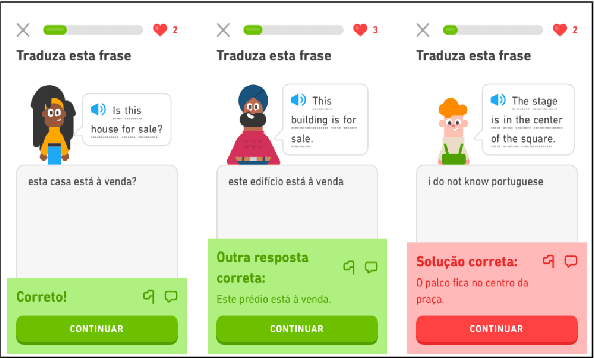


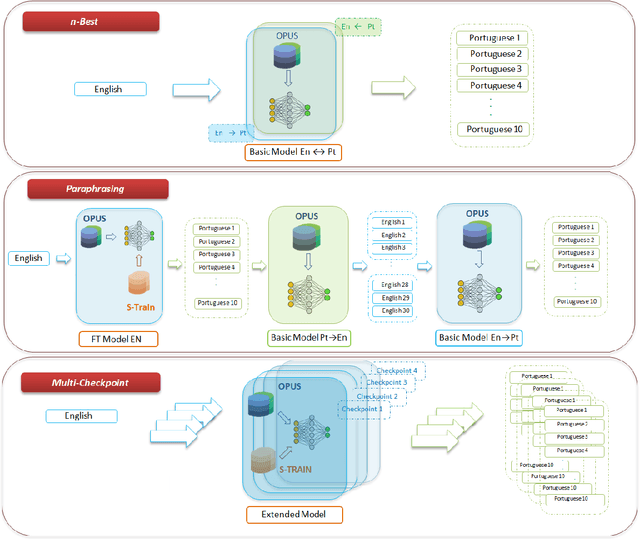
We describe our submission to the 2020 Duolingo Shared Task on Simultaneous Translation And Paraphrase for Language Education (STAPLE) (Mayhew et al., 2020). We view MT models at various training stages (i.e., checkpoints) as human learners at different levels. Hence, we employ an ensemble of multi-checkpoints from the same model to generate translation sequences with various levels of fluency. From each checkpoint, for our best model, we sample n-Best sequences (n=10) with a beam width =100. We achieve 37.57 macro F1 with a 6 checkpoint model ensemble on the official English to Portuguese shared task test data, outperforming a baseline Amazon translation system of 21.30 macro F1 and ultimately demonstrating the utility of our intuitive method.