 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquation Embeddings
Paper and Code

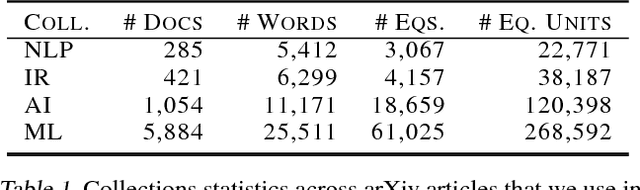
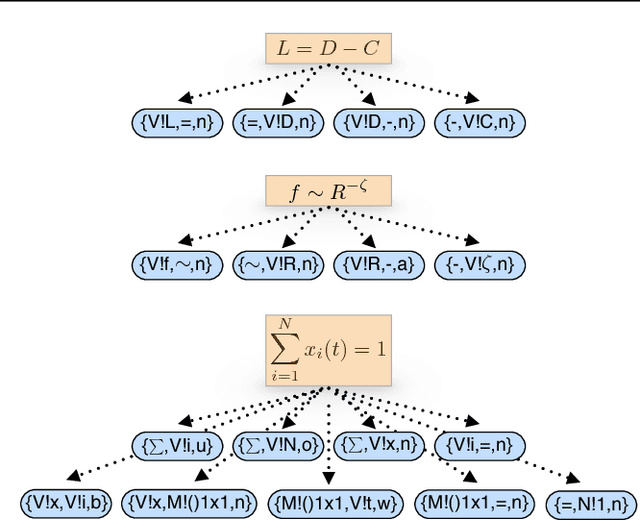
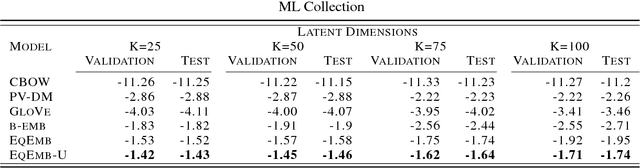
We present an unsupervised approach for discovering semantic representations of mathematical equations. Equations are challenging to analyze because each is unique, or nearly unique. Our method, which we call equation embeddings, finds good representations of equations by using the representations of their surrounding words. We used equation embeddings to analyze four collections of scientific articles from the arXiv, covering four computer science domains (NLP, IR, AI, and ML) and $\sim$98.5k equations. Quantitatively, we found that equation embeddings provide better models when compared to existing word embedding approaches. Qualitatively, we found that equation embeddings provide coherent semantic representations of equations and can capture semantic similarity to other equations and to words.