 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential choice in ordered bundles
Oct 29, 2024



Experience goods such as sporting and artistic events, songs, videos, news stories, podcasts, and television series, are often packaged and consumed in bundles. Many such bundles are ordered in the sense that the individual items are consumed sequentially, one at a time. We examine if an individual's decision to consume the next item in an ordered bundle can be predicted based on his/her consumption pattern for the preceding items. We evaluate several predictive models, including two custom Transformers using decoder-only and encoder-decoder architectures, fine-tuned GPT-3, a custom LSTM model, a reinforcement learning model, two Markov models, and a zero-order model. Using data from Spotify, we find that the custom Transformer with a decoder-only architecture provides the most accurate predictions, both for individual choices and aggregate demand. This model captures a general form of state dependence. Analysis of Transformer attention weights suggests that the consumption of the next item in a bundle is based on approximately equal weighting of all preceding choices. Our results indicate that the Transformer can assist in queuing the next item that an individual is likely to consume from an ordered bundle, predicting the demand for individual items, and personalizing promotions to increase demand.
CauESC: A Causal Aware Model for Emotional Support Conversation
Jan 31, 2024Emotional Support Conversation aims at reducing the seeker's emotional distress through supportive response. Existing approaches have two limitations: (1) They ignore the emotion causes of the distress, which is important for fine-grained emotion understanding; (2) They focus on the seeker's own mental state rather than the emotional dynamics during interaction between speakers. To address these issues, we propose a novel framework CauESC, which firstly recognizes the emotion causes of the distress, as well as the emotion effects triggered by the causes, and then understands each strategy of verbal grooming independently and integrates them skillfully. Experimental results on the benchmark dataset demonstrate the effectiveness of our approach and show the benefits of emotion understanding from cause to effect and independent-integrated strategy modeling.
Deep Risk Model: A Deep Learning Solution for Mining Latent Risk Factors to Improve Covariance Matrix Estimation
Jul 12, 2021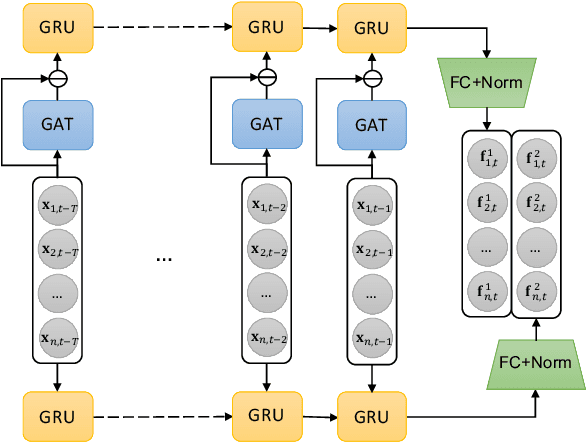
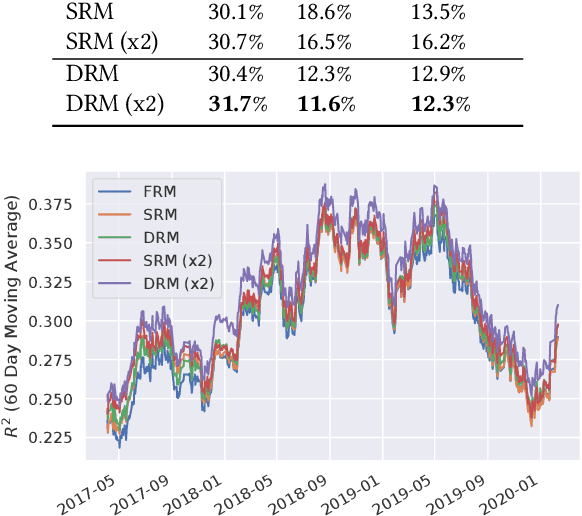
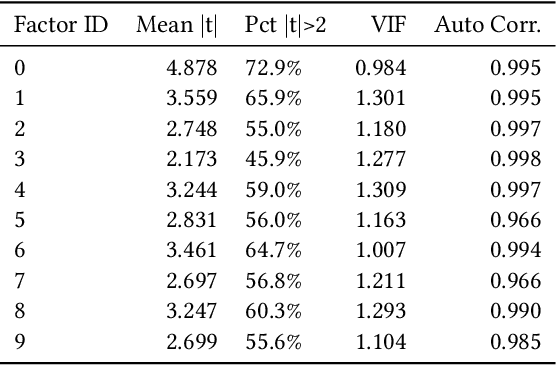
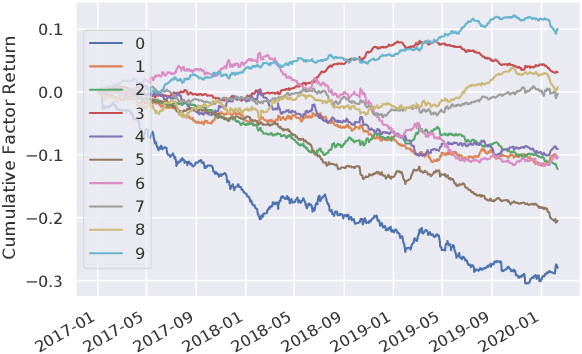
Modeling and managing portfolio risk is perhaps the most important step to achieve growing and preserving investment performance. Within the modern portfolio construction framework that built on Markowitz's theory, the covariance matrix of stock returns is required to model the portfolio risk. Traditional approaches to estimate the covariance matrix are based on human designed risk factors, which often requires tremendous time and effort to design better risk factors to improve the covariance estimation. In this work, we formulate the quest of mining risk factors as a learning problem and propose a deep learning solution to effectively "design" risk factors with neural networks. The learning objective is carefully set to ensure the learned risk factors are effective in explaining stock returns as well as have desired orthogonality and stability. Our experiments on the stock market data demonstrate the effectiveness of the proposed method: our method can obtain $1.9\%$ higher explained variance measured by $R^2$ and also reduce the risk of a global minimum variance portfolio. Incremental analysis further supports our design of both the architecture and the learning objective.
Learning Multiple Stock Trading Patterns with Temporal Routing Adaptor and Optimal Transport
Jun 25, 2021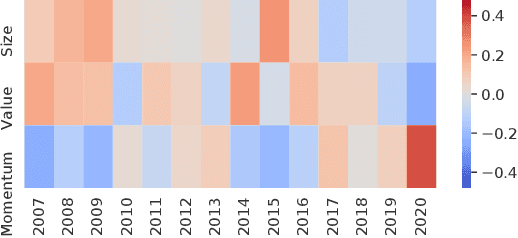
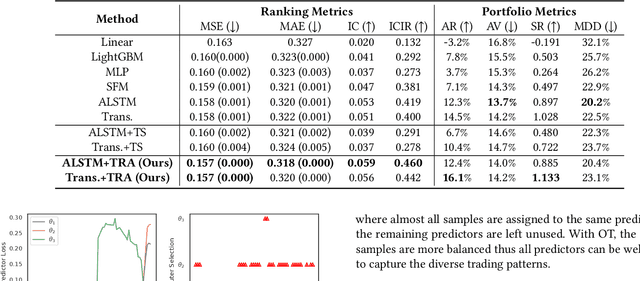
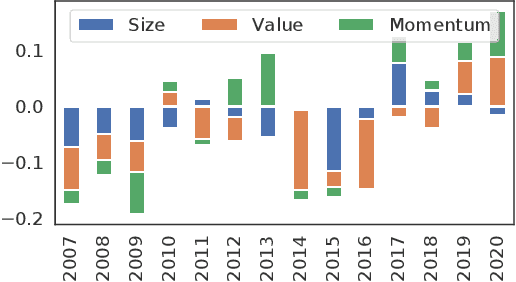

Successful quantitative investment usually relies on precise predictions of the future movement of the stock price. Recently, machine learning based solutions have shown their capacity to give more accurate stock prediction and become indispensable components in modern quantitative investment systems. However, the i.i.d. assumption behind existing methods is inconsistent with the existence of diverse trading patterns in the stock market, which inevitably limits their ability to achieve better stock prediction performance. In this paper, we propose a novel architecture, Temporal Routing Adaptor (TRA), to empower existing stock prediction models with the ability to model multiple stock trading patterns. Essentially, TRA is a lightweight module that consists of a set of independent predictors for learning multiple patterns as well as a router to dispatch samples to different predictors. Nevertheless, the lack of explicit pattern identifiers makes it quite challenging to train an effective TRA-based model. To tackle this challenge, we further design a learning algorithm based on Optimal Transport (OT) to obtain the optimal sample to predictor assignment and effectively optimize the router with such assignment through an auxiliary loss term. Experiments on the real-world stock ranking task show that compared to the state-of-the-art baselines, e.g., Attention LSTM and Transformer, the proposed method can improve information coefficient (IC) from 0.053 to 0.059 and 0.051 to 0.056 respectively. Our dataset and code used in this work are publicly available: https://github.com/microsoft/qlib/tree/main/examples/benchmarks/TRA.