 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Unlearning via Class-Discriminative Pruning
Paper and Code
Oct 22, 2021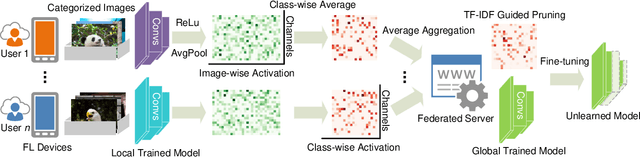



We explore the problem of selectively forgetting categories from trained CNN classification models in the federated learning (FL). Given that the data used for training cannot be accessed globally in FL, our insights probe deep into the internal influence of each channel. Through the visualization of feature maps activated by different channels, we observe that different channels have a varying contribution to different categories in image classification. Inspired by this, we propose a method for scrubbing the model clean of information about particular categories. The method does not require retraining from scratch, nor global access to the data used for training. Instead, we introduce the concept of Term Frequency Inverse Document Frequency (TF-IDF) to quantize the class discrimination of channels. Channels with high TF-IDF scores have more discrimination on the target categories and thus need to be pruned to unlearn. The channel pruning is followed by a fine-tuning process to recover the performance of the pruned model. Evaluated on CIFAR10 dataset, our method accelerates the speed of unlearning by 8.9x for the ResNet model, and 7.9x for the VGG model under no degradation in accuracy, compared to retraining from scratch. For CIFAR100 dataset, the speedups are 9.9x and 8.4x, respectively. We envision this work as a complementary block for FL towards compliance with legal and ethical criteria.