 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Improved Finite-time Analysis of Temporal Difference Learning with Deep Neural Networks
May 07, 2024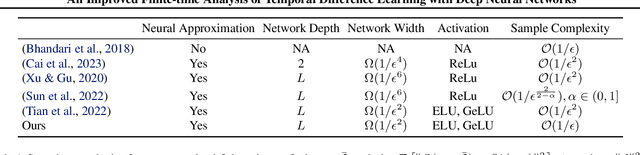

Temporal difference (TD) learning algorithms with neural network function parameterization have well-established empirical success in many practical large-scale reinforcement learning tasks. However, theoretical understanding of these algorithms remains challenging due to the nonlinearity of the action-value approximation. In this paper, we develop an improved non-asymptotic analysis of the neural TD method with a general $L$-layer neural network. New proof techniques are developed and an improved new $\tilde{\mathcal{O}}(\epsilon^{-1})$ sample complexity is derived. To our best knowledge, this is the first finite-time analysis of neural TD that achieves an $\tilde{\mathcal{O}}(\epsilon^{-1})$ complexity under the Markovian sampling, as opposed to the best known $\tilde{\mathcal{O}}(\epsilon^{-2})$ complexity in the existing literature.
Provably Efficient Gauss-Newton Temporal Difference Learning Method with Function Approximation
Feb 25, 2023



In this paper, based on the spirit of Fitted Q-Iteration (FQI), we propose a Gauss-Newton Temporal Difference (GNTD) method to solve the Q-value estimation problem with function approximation. In each iteration, unlike the original FQI that solves a nonlinear least square subproblem to fit the Q-iteration, the GNTD method can be viewed as an \emph{inexact} FQI that takes only one Gauss-Newton step to optimize this subproblem, which is much cheaper in computation. Compared to the popular Temporal Difference (TD) learning, which can be viewed as taking a single gradient descent step to FQI's subproblem per iteration, the Gauss-Newton step of GNTD better retains the structure of FQI and hence leads to better convergence. In our work, we derive the finite-sample non-asymptotic convergence of GNTD under linear, neural network, and general smooth function approximations. In particular, recent works on neural TD only guarantee a suboptimal $\mathcal{\mathcal{O}}(\epsilon^{-4})$ sample complexity, while GNTD obtains an improved complexity of $\tilde{\mathcal{O}}(\epsilon^{-2})$. Finally, we validate our method via extensive experiments in both online and offline RL problems. Our method exhibits both higher rewards and faster convergence than TD-type methods, including DQN.