 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecRM-Bench: Benchmarking Multidimensional Reward Modeling for Agentic Recommender Systems
May 12, 2026The integration of Large Language Model (LLM) agents is transforming recommender systems from simple query-item matching towards deeply personalized and interactive recommendations. Reinforcement Learning (RL) provides an essential framework for the optimization of these agents in recommendation tasks. However, current methodologies remain limited by a reliance on single dimensional outcome-based rewards that focus exclusively on final user interactions, overlooking critical intermediate capabilities, such as instruction following and complex intent understanding. Despite the necessity for designing multi-dimensional reward, the field lacks a standardized benchmark to facilitate this development. To bridge this gap, we introduce RecRM-Bench, the largest and most comprehensive benchmark to date for agentic recommender systems. It comprises over 1 million structured entries across four core evaluation dimensions: instruction following, factual consistency, query-item relevance, and fine-grained user behavior prediction. By supporting comprehensive assessment from syntactic compliance to complex intent grounding and preference modeling, RecRM-Bench provides a foundational dataset for training sophisticated reward models. Furthermore, we propose a systematic framework for the construction of multi-dimensional reward models and the integration of a hybrid reward function, establishing a robust foundation for developing reliable and highly capable agentic recommender systems. The complete RecRM-Bench dataset is publicly available at https://huggingface.co/datasets/wwzeng/RecRM-Bench.
Learning Implicit Neural Degradation Representation for Unpaired Image Dehazing
Nov 17, 2025
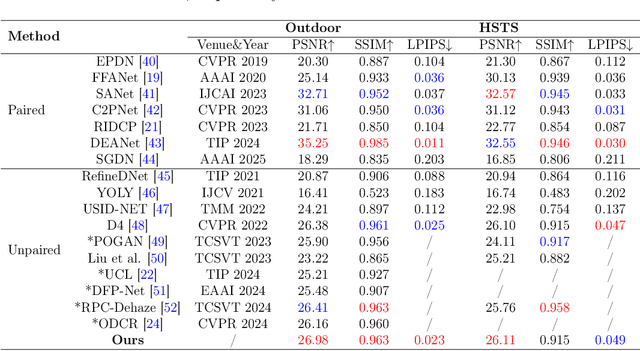
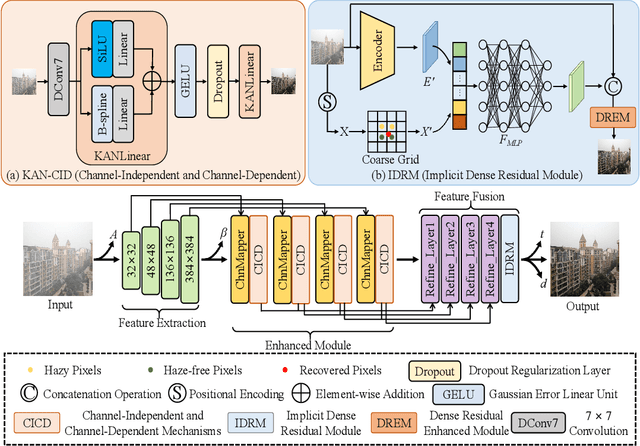
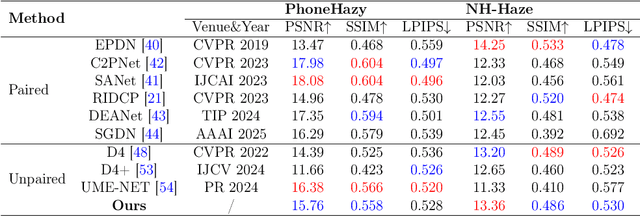
Image dehazing is an important task in the field of computer vision, aiming at restoring clear and detail-rich visual content from haze-affected images. However, when dealing with complex scenes, existing methods often struggle to strike a balance between fine-grained feature representation of inhomogeneous haze distribution and global consistency modeling. Furthermore, to better learn the common degenerate representation of haze in spatial variations, we propose an unsupervised dehaze method for implicit neural degradation representation. Firstly, inspired by the Kolmogorov-Arnold representation theorem, we propose a mechanism combining the channel-independent and channel-dependent mechanisms, which efficiently enhances the ability to learn from nonlinear dependencies. which in turn achieves good visual perception in complex scenes. Moreover, we design an implicit neural representation to model haze degradation as a continuous function to eliminate redundant information and the dependence on explicit feature extraction and physical models. To further learn the implicit representation of the haze features, we also designed a dense residual enhancement module from it to eliminate redundant information. This achieves high-quality image restoration. Experimental results show that our method achieves competitive dehaze performance on various public and real-world datasets. This project code will be available at https://github.com/Fan-pixel/NeDR-Dehaze.
DFDNet: Dynamic Frequency-Guided De-Flare Network
Jul 23, 2025
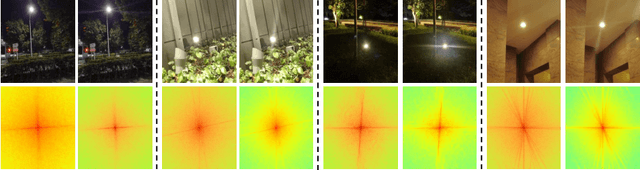
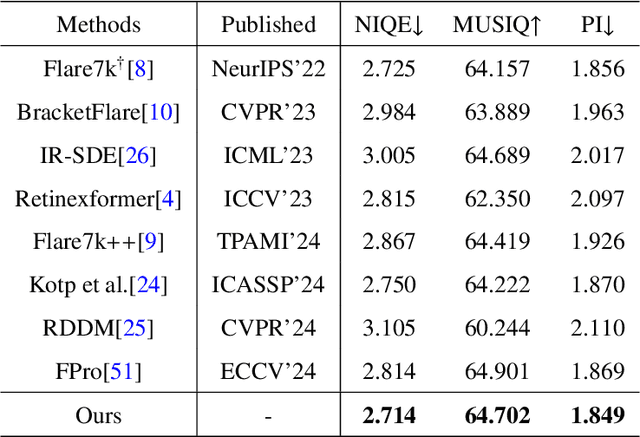
Strong light sources in nighttime photography frequently produce flares in images, significantly degrading visual quality and impacting the performance of downstream tasks. While some progress has been made, existing methods continue to struggle with removing large-scale flare artifacts and repairing structural damage in regions near the light source. We observe that these challenging flare artifacts exhibit more significant discrepancies from the reference images in the frequency domain compared to the spatial domain. Therefore, this paper presents a novel dynamic frequency-guided deflare network (DFDNet) that decouples content information from flare artifacts in the frequency domain, effectively removing large-scale flare artifacts. Specifically, DFDNet consists mainly of a global dynamic frequency-domain guidance (GDFG) module and a local detail guidance module (LDGM). The GDFG module guides the network to perceive the frequency characteristics of flare artifacts by dynamically optimizing global frequency domain features, effectively separating flare information from content information. Additionally, we design an LDGM via a contrastive learning strategy that aligns the local features of the light source with the reference image, reduces local detail damage from flare removal, and improves fine-grained image restoration. The experimental results demonstrate that the proposed method outperforms existing state-of-the-art methods in terms of performance. The code is available at \href{https://github.com/AXNing/DFDNet}{https://github.com/AXNing/DFDNet}.
UR2P-Dehaze: Learning a Simple Image Dehaze Enhancer via Unpaired Rich Physical Prior
Jan 12, 2025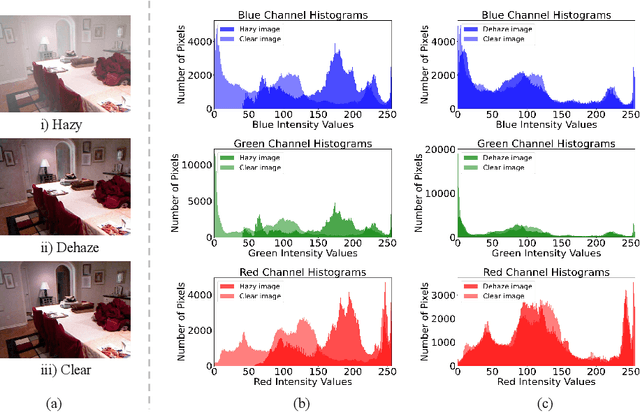
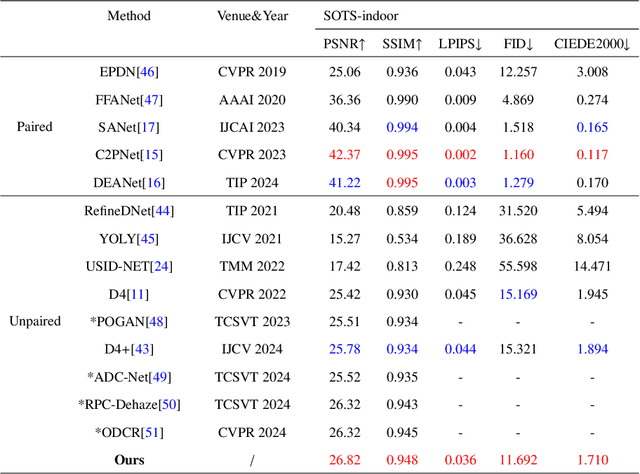
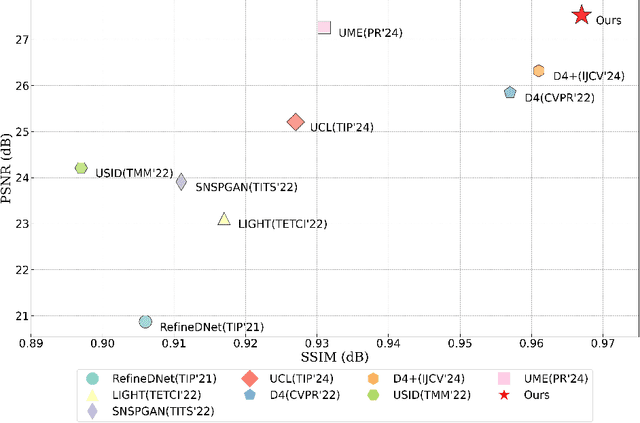
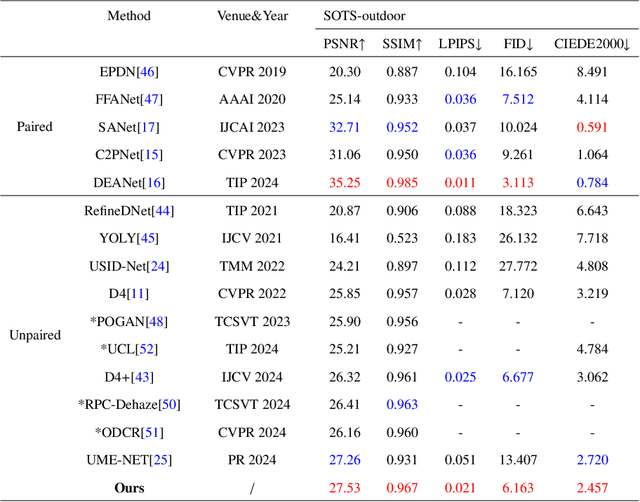
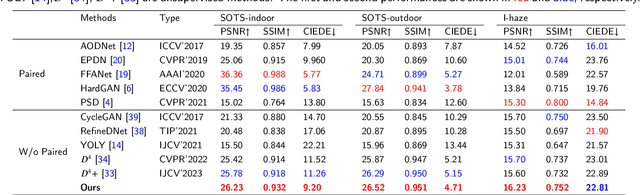
Image dehazing techniques aim to enhance contrast and restore details, which are essential for preserving visual information and improving image processing accuracy. Existing methods rely on a single manual prior, which cannot effectively reveal image details. To overcome this limitation, we propose an unpaired image dehazing network, called the Simple Image Dehaze Enhancer via Unpaired Rich Physical Prior (UR2P-Dehaze). First, to accurately estimate the illumination, reflectance, and color information of the hazy image, we design a shared prior estimator (SPE) that is iteratively trained to ensure the consistency of illumination and reflectance, generating clear, high-quality images. Additionally, a self-monitoring mechanism is introduced to eliminate undesirable features, providing reliable priors for image reconstruction. Next, we propose Dynamic Wavelet Separable Convolution (DWSC), which effectively integrates key features across both low and high frequencies, significantly enhancing the preservation of image details and ensuring global consistency. Finally, to effectively restore the color information of the image, we propose an Adaptive Color Corrector that addresses the problem of unclear colors. The PSNR, SSIM, LPIPS, FID and CIEDE2000 metrics on the benchmark dataset show that our method achieves state-of-the-art performance. It also contributes to the performance improvement of downstream tasks. The project code will be available at https://github.com/Fan-pixel/UR2P-Dehaze. \end{abstract}
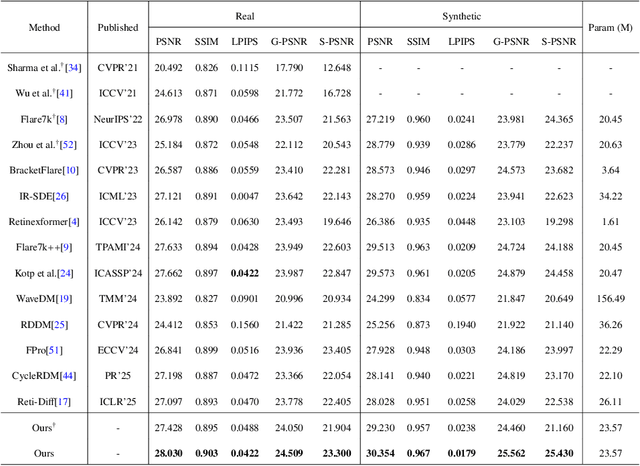
Unified Image Restoration and Enhancement: Degradation Calibrated Cycle Reconstruction Diffusion Model
Dec 19, 2024Image restoration and enhancement are pivotal for numerous computer vision applications, yet unifying these tasks efficiently remains a significant challenge. Inspired by the iterative refinement capabilities of diffusion models, we propose CycleRDM, a novel framework designed to unify restoration and enhancement tasks while achieving high-quality mapping. Specifically, CycleRDM first learns the mapping relationships among the degraded domain, the rough normal domain, and the normal domain through a two-stage diffusion inference process. Subsequently, we transfer the final calibration process to the wavelet low-frequency domain using discrete wavelet transform, performing fine-grained calibration from a frequency domain perspective by leveraging task-specific frequency spaces. To improve restoration quality, we design a feature gain module for the decomposed wavelet high-frequency domain to eliminate redundant features. Additionally, we employ multimodal textual prompts and Fourier transform to drive stable denoising and reduce randomness during the inference process. After extensive validation, CycleRDM can be effectively generalized to a wide range of image restoration and enhancement tasks while requiring only a small number of training samples to be significantly superior on various benchmarks of reconstruction quality and perceptual quality. The source code will be available at https://github.com/hejh8/CycleRDM.
Zero-Shot Low-Light Image Enhancement via Joint Frequency Domain Priors Guided Diffusion
Nov 21, 2024
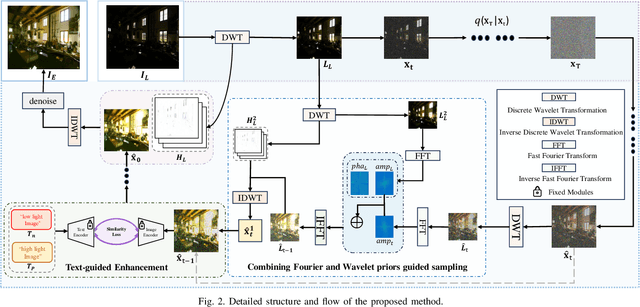

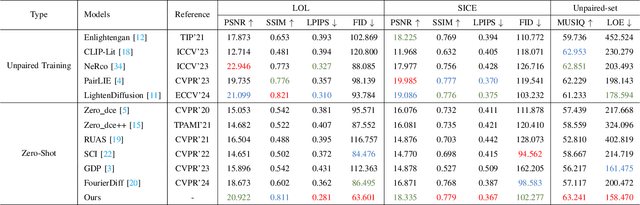
Due to the singularity of real-world paired datasets and the complexity of low-light environments, this leads to supervised methods lacking a degree of scene generalisation. Meanwhile, limited by poor lighting and content guidance, existing zero-shot methods cannot handle unknown severe degradation well. To address this problem, we will propose a new zero-shot low-light enhancement method to compensate for the lack of light and structural information in the diffusion sampling process by effectively combining the wavelet and Fourier frequency domains to construct rich a priori information. The key to the inspiration comes from the similarity between the wavelet and Fourier frequency domains: both light and structure information are closely related to specific frequency domain regions, respectively. Therefore, by transferring the diffusion process to the wavelet low-frequency domain and combining the wavelet and Fourier frequency domains by continuously decomposing them in the inverse process, the constructed rich illumination prior is utilised to guide the image generation enhancement process. Sufficient experiments show that the framework is robust and effective in various scenarios. The code will be available at: \href{https://github.com/hejh8/Joint-Wavelet-and-Fourier-priors-guided-diffusion}{https://github.com/hejh8/Joint-Wavelet-and-Fourier-priors-guided-diffusion}.
Optimizing 4D Lookup Table for Low-light Video Enhancement via Wavelet Priori
Sep 13, 2024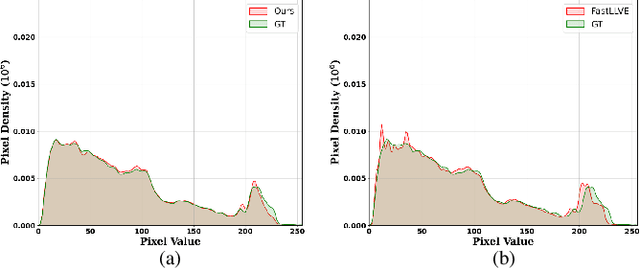

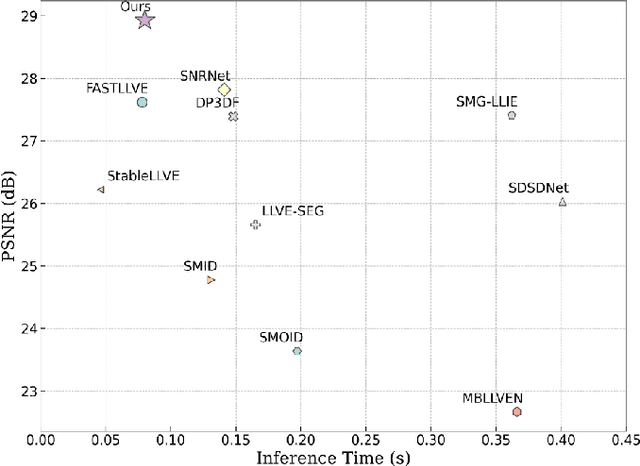
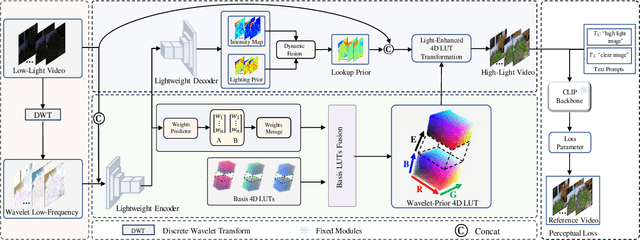
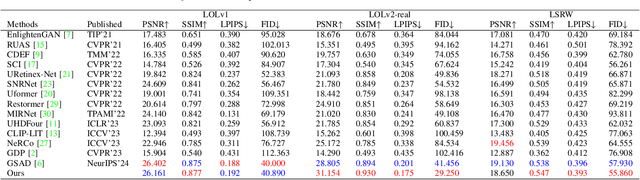
Low-light video enhancement is highly demanding in maintaining spatiotemporal color consistency. Therefore, improving the accuracy of color mapping and keeping the latency low is challenging. Based on this, we propose incorporating Wavelet-priori for 4D Lookup Table (WaveLUT), which effectively enhances the color coherence between video frames and the accuracy of color mapping while maintaining low latency. Specifically, we use the wavelet low-frequency domain to construct an optimized lookup prior and achieve an adaptive enhancement effect through a designed Wavelet-prior 4D lookup table. To effectively compensate the a priori loss in the low light region, we further explore a dynamic fusion strategy that adaptively determines the spatial weights based on the correlation between the wavelet lighting prior and the target intensity structure. In addition, during the training phase, we devise a text-driven appearance reconstruction method that dynamically balances brightness and content through multimodal semantics-driven Fourier spectra. Extensive experiments on a wide range of benchmark datasets show that this method effectively enhances the previous method's ability to perceive the color space and achieves metric-favorable and perceptually oriented real-time enhancement while maintaining high efficiency.
KAN See In the Dark
Sep 05, 2024
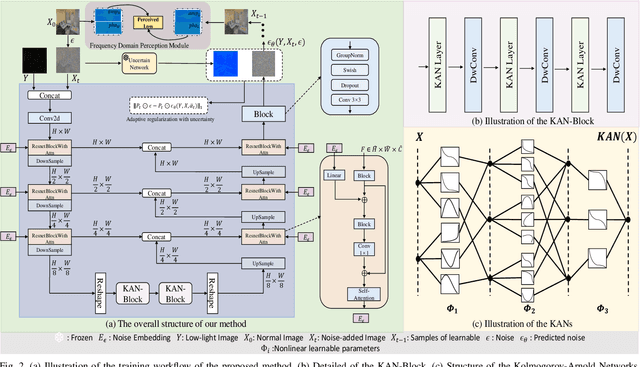

Existing low-light image enhancement methods are difficult to fit the complex nonlinear relationship between normal and low-light images due to uneven illumination and noise effects. The recently proposed Kolmogorov-Arnold networks (KANs) feature spline-based convolutional layers and learnable activation functions, which can effectively capture nonlinear dependencies. In this paper, we design a KAN-Block based on KANs and innovatively apply it to low-light image enhancement. This method effectively alleviates the limitations of current methods constrained by linear network structures and lack of interpretability, further demonstrating the potential of KANs in low-level vision tasks. Given the poor perception of current low-light image enhancement methods and the stochastic nature of the inverse diffusion process, we further introduce frequency-domain perception for visually oriented enhancement. Extensive experiments demonstrate the competitive performance of our method on benchmark datasets. The code will be available at: https://github.com/AXNing/KSID}{https://github.com/AXNing/KSID.
Addressing Domain Discrepancy: A Dual-branch Collaborative Model to Unsupervised Dehazing
Jul 14, 2024
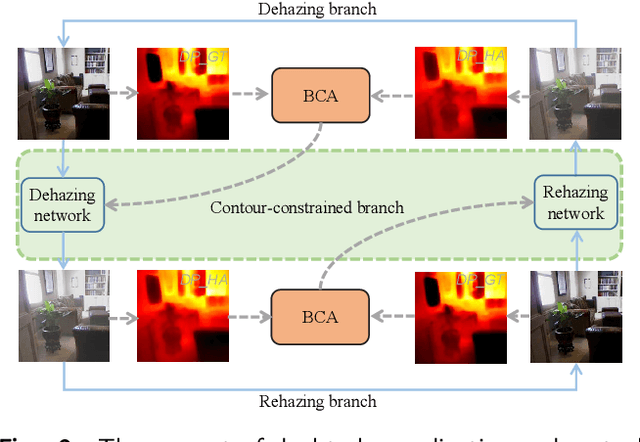
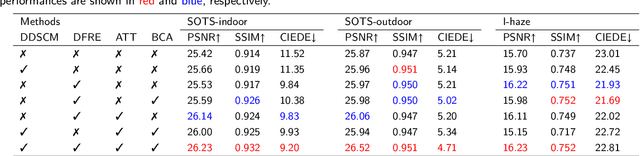
Although synthetic data can alleviate acquisition challenges in image dehazing tasks, it also introduces the problem of domain bias when dealing with small-scale data. This paper proposes a novel dual-branch collaborative unpaired dehazing model (DCM-dehaze) to address this issue. The proposed method consists of two collaborative branches: dehazing and contour constraints. Specifically, we design a dual depthwise separable convolutional module (DDSCM) to enhance the information expressiveness of deeper features and the correlation to shallow features. In addition, we construct a bidirectional contour function to optimize the edge features of the image to enhance the clarity and fidelity of the image details. Furthermore, we present feature enhancers via a residual dense architecture to eliminate redundant features of the dehazing process and further alleviate the domain deviation problem. Extensive experiments on benchmark datasets show that our method reaches the state-of-the-art. This project code will be available at \url{https://github.com/Fan-pixel/DCM-dehaze.
Artistic-style text detector and a new Movie-Poster dataset
Jun 24, 2024Although current text detection algorithms demonstrate effectiveness in general scenarios, their performance declines when confronted with artistic-style text featuring complex structures. This paper proposes a method that utilizes Criss-Cross Attention and residual dense block to address the incomplete and misdiagnosis of artistic-style text detection by current algorithms. Specifically, our method mainly consists of a feature extraction backbone, a feature enhancement network, a multi-scale feature fusion module, and a boundary discrimination module. The feature enhancement network significantly enhances the model's perceptual capabilities in complex environments by fusing horizontal and vertical contextual information, allowing it to capture detailed features overlooked in artistic-style text. We incorporate residual dense block into the Feature Pyramid Network to suppress the effect of background noise during feature fusion. Aiming to omit the complex post-processing, we explore a boundary discrimination module that guides the correct generation of boundary proposals. Furthermore, given that movie poster titles often use stylized art fonts, we collected a Movie-Poster dataset to address the scarcity of artistic-style text data. Extensive experiments demonstrate that our proposed method performs superiorly on the Movie-Poster dataset and produces excellent results on multiple benchmark datasets. The code and the Movie-Poster dataset will be available at: https://github.com/biedaxiaohua/Artistic-style-text-detection