 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Image Restoration and Enhancement: Degradation Calibrated Cycle Reconstruction Diffusion Model
Dec 19, 2024Image restoration and enhancement are pivotal for numerous computer vision applications, yet unifying these tasks efficiently remains a significant challenge. Inspired by the iterative refinement capabilities of diffusion models, we propose CycleRDM, a novel framework designed to unify restoration and enhancement tasks while achieving high-quality mapping. Specifically, CycleRDM first learns the mapping relationships among the degraded domain, the rough normal domain, and the normal domain through a two-stage diffusion inference process. Subsequently, we transfer the final calibration process to the wavelet low-frequency domain using discrete wavelet transform, performing fine-grained calibration from a frequency domain perspective by leveraging task-specific frequency spaces. To improve restoration quality, we design a feature gain module for the decomposed wavelet high-frequency domain to eliminate redundant features. Additionally, we employ multimodal textual prompts and Fourier transform to drive stable denoising and reduce randomness during the inference process. After extensive validation, CycleRDM can be effectively generalized to a wide range of image restoration and enhancement tasks while requiring only a small number of training samples to be significantly superior on various benchmarks of reconstruction quality and perceptual quality. The source code will be available at https://github.com/hejh8/CycleRDM.
Zero-Shot Low-Light Image Enhancement via Joint Frequency Domain Priors Guided Diffusion
Nov 21, 2024
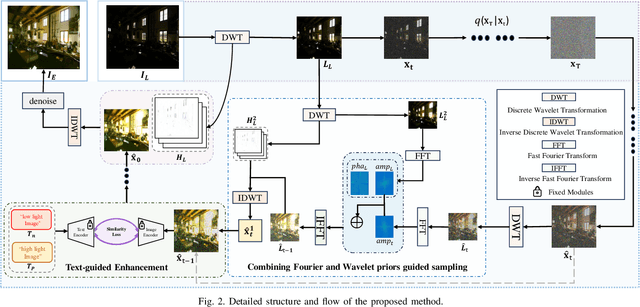

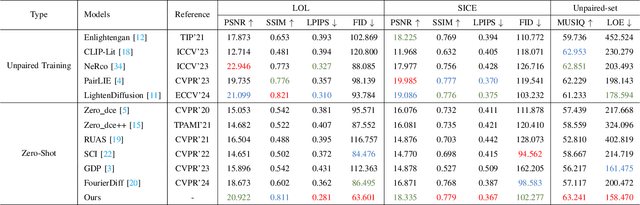
Due to the singularity of real-world paired datasets and the complexity of low-light environments, this leads to supervised methods lacking a degree of scene generalisation. Meanwhile, limited by poor lighting and content guidance, existing zero-shot methods cannot handle unknown severe degradation well. To address this problem, we will propose a new zero-shot low-light enhancement method to compensate for the lack of light and structural information in the diffusion sampling process by effectively combining the wavelet and Fourier frequency domains to construct rich a priori information. The key to the inspiration comes from the similarity between the wavelet and Fourier frequency domains: both light and structure information are closely related to specific frequency domain regions, respectively. Therefore, by transferring the diffusion process to the wavelet low-frequency domain and combining the wavelet and Fourier frequency domains by continuously decomposing them in the inverse process, the constructed rich illumination prior is utilised to guide the image generation enhancement process. Sufficient experiments show that the framework is robust and effective in various scenarios. The code will be available at: \href{https://github.com/hejh8/Joint-Wavelet-and-Fourier-priors-guided-diffusion}{https://github.com/hejh8/Joint-Wavelet-and-Fourier-priors-guided-diffusion}.
Optimizing 4D Lookup Table for Low-light Video Enhancement via Wavelet Priori
Sep 13, 2024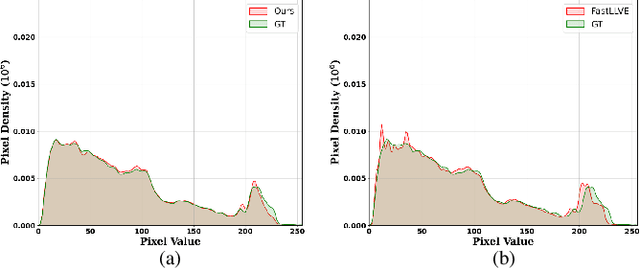

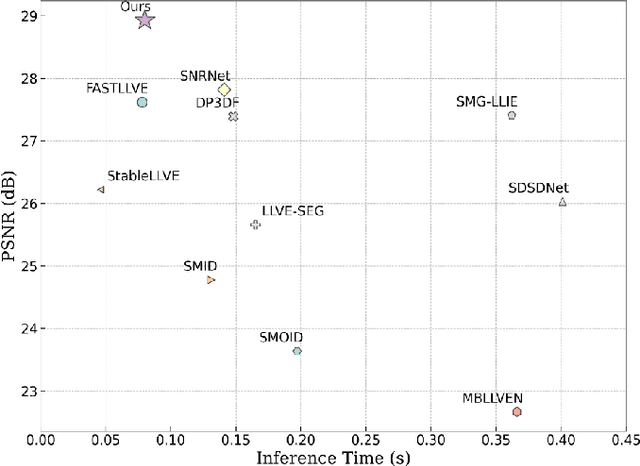
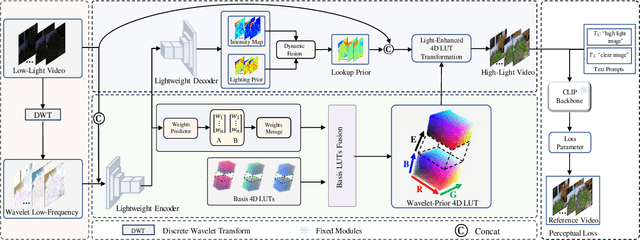
Low-light video enhancement is highly demanding in maintaining spatiotemporal color consistency. Therefore, improving the accuracy of color mapping and keeping the latency low is challenging. Based on this, we propose incorporating Wavelet-priori for 4D Lookup Table (WaveLUT), which effectively enhances the color coherence between video frames and the accuracy of color mapping while maintaining low latency. Specifically, we use the wavelet low-frequency domain to construct an optimized lookup prior and achieve an adaptive enhancement effect through a designed Wavelet-prior 4D lookup table. To effectively compensate the a priori loss in the low light region, we further explore a dynamic fusion strategy that adaptively determines the spatial weights based on the correlation between the wavelet lighting prior and the target intensity structure. In addition, during the training phase, we devise a text-driven appearance reconstruction method that dynamically balances brightness and content through multimodal semantics-driven Fourier spectra. Extensive experiments on a wide range of benchmark datasets show that this method effectively enhances the previous method's ability to perceive the color space and achieves metric-favorable and perceptually oriented real-time enhancement while maintaining high efficiency.
KAN See In the Dark
Sep 05, 2024
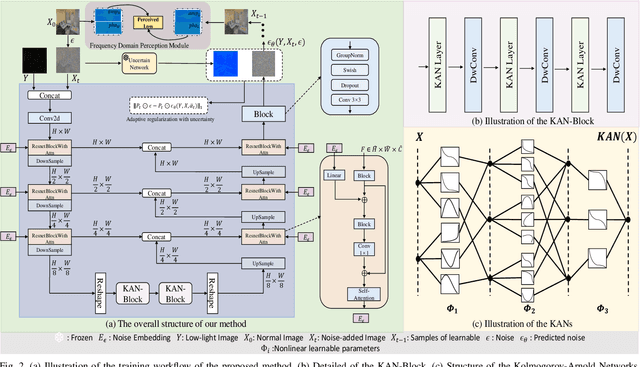

Existing low-light image enhancement methods are difficult to fit the complex nonlinear relationship between normal and low-light images due to uneven illumination and noise effects. The recently proposed Kolmogorov-Arnold networks (KANs) feature spline-based convolutional layers and learnable activation functions, which can effectively capture nonlinear dependencies. In this paper, we design a KAN-Block based on KANs and innovatively apply it to low-light image enhancement. This method effectively alleviates the limitations of current methods constrained by linear network structures and lack of interpretability, further demonstrating the potential of KANs in low-level vision tasks. Given the poor perception of current low-light image enhancement methods and the stochastic nature of the inverse diffusion process, we further introduce frequency-domain perception for visually oriented enhancement. Extensive experiments demonstrate the competitive performance of our method on benchmark datasets. The code will be available at: https://github.com/AXNing/KSID}{https://github.com/AXNing/KSID.
Zero-LED: Zero-Reference Lighting Estimation Diffusion Model for Low-Light Image Enhancement
Mar 05, 2024



Diffusion model-based low-light image enhancement methods rely heavily on paired training data, leading to limited extensive application. Meanwhile, existing unsupervised methods lack effective bridging capabilities for unknown degradation. To address these limitations, we propose a novel zero-reference lighting estimation diffusion model for low-light image enhancement called Zero-LED. It utilizes the stable convergence ability of diffusion models to bridge the gap between low-light domains and real normal-light domains and successfully alleviates the dependence on pairwise training data via zero-reference learning. Specifically, we first design the initial optimization network to preprocess the input image and implement bidirectional constraints between the diffusion model and the initial optimization network through multiple objective functions. Subsequently, the degradation factors of the real-world scene are optimized iteratively to achieve effective light enhancement. In addition, we explore a frequency-domain based and semantically guided appearance reconstruction module that encourages feature alignment of the recovered image at a fine-grained level and satisfies subjective expectations. Finally, extensive experiments demonstrate the superiority of our approach to other state-of-the-art methods and more significant generalization capabilities. We will open the source code upon acceptance of the paper.
Low-light Image Enhancement via CLIP-Fourier Guided Wavelet Diffusion
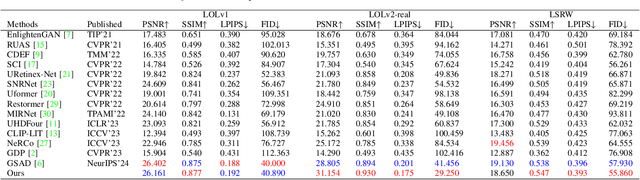
Jan 08, 2024Low-light image enhancement techniques have significantly progressed, but unstable image quality recovery and unsatisfactory visual perception are still significant challenges. To solve these problems, we propose a novel and robust low-light image enhancement method via CLIP-Fourier Guided Wavelet Diffusion, abbreviated as CFWD. Specifically, we design a guided network with a multiscale visual language in the frequency domain based on the wavelet transform to achieve effective image enhancement iteratively. In addition, we combine the advantages of Fourier transform in detail perception to construct a hybrid frequency domain space with significant perceptual capabilities(HFDPM). This operation guides wavelet diffusion to recover the fine-grained structure of the image and avoid diversity confusion. Extensive quantitative and qualitative experiments on publicly available real-world benchmarks show that our method outperforms existing state-of-the-art methods and better reproduces images similar to normal images. Code is available at https://github.com/He-Jinhong/CFWD.