 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Implicit Neural Degradation Representation for Unpaired Image Dehazing
Nov 17, 2025
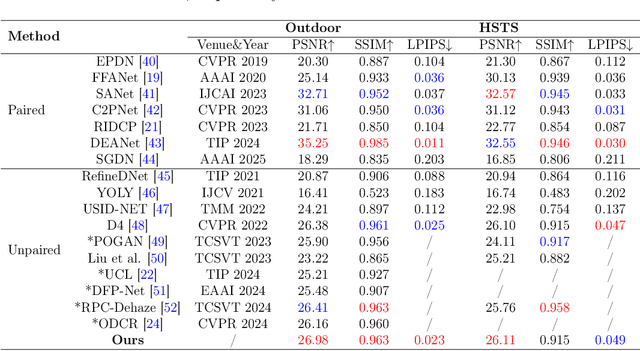
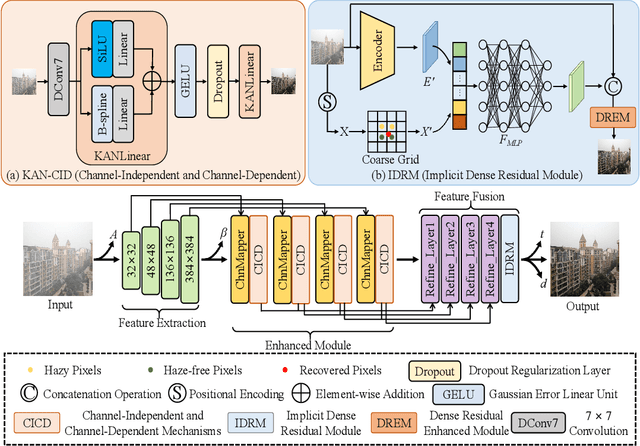
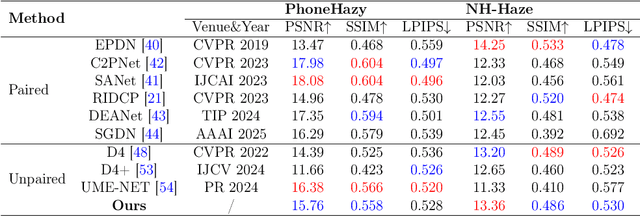
Image dehazing is an important task in the field of computer vision, aiming at restoring clear and detail-rich visual content from haze-affected images. However, when dealing with complex scenes, existing methods often struggle to strike a balance between fine-grained feature representation of inhomogeneous haze distribution and global consistency modeling. Furthermore, to better learn the common degenerate representation of haze in spatial variations, we propose an unsupervised dehaze method for implicit neural degradation representation. Firstly, inspired by the Kolmogorov-Arnold representation theorem, we propose a mechanism combining the channel-independent and channel-dependent mechanisms, which efficiently enhances the ability to learn from nonlinear dependencies. which in turn achieves good visual perception in complex scenes. Moreover, we design an implicit neural representation to model haze degradation as a continuous function to eliminate redundant information and the dependence on explicit feature extraction and physical models. To further learn the implicit representation of the haze features, we also designed a dense residual enhancement module from it to eliminate redundant information. This achieves high-quality image restoration. Experimental results show that our method achieves competitive dehaze performance on various public and real-world datasets. This project code will be available at https://github.com/Fan-pixel/NeDR-Dehaze.
Addressing Domain Discrepancy: A Dual-branch Collaborative Model to Unsupervised Dehazing
Jul 14, 2024
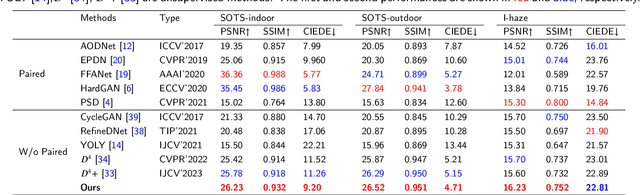
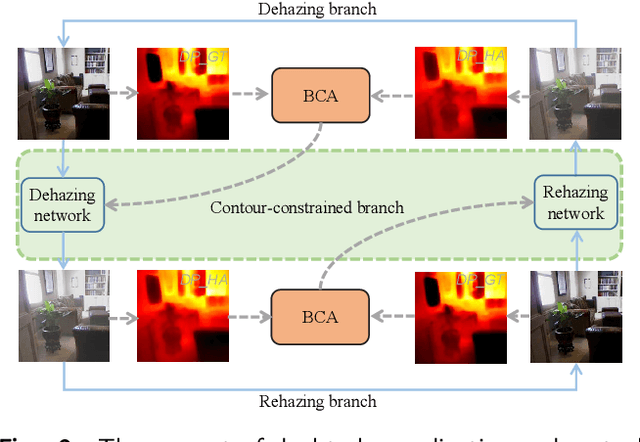
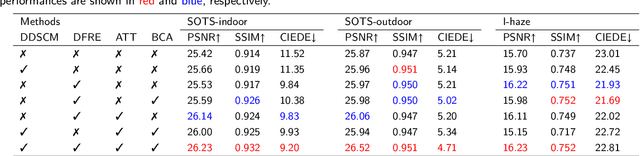
Although synthetic data can alleviate acquisition challenges in image dehazing tasks, it also introduces the problem of domain bias when dealing with small-scale data. This paper proposes a novel dual-branch collaborative unpaired dehazing model (DCM-dehaze) to address this issue. The proposed method consists of two collaborative branches: dehazing and contour constraints. Specifically, we design a dual depthwise separable convolutional module (DDSCM) to enhance the information expressiveness of deeper features and the correlation to shallow features. In addition, we construct a bidirectional contour function to optimize the edge features of the image to enhance the clarity and fidelity of the image details. Furthermore, we present feature enhancers via a residual dense architecture to eliminate redundant features of the dehazing process and further alleviate the domain deviation problem. Extensive experiments on benchmark datasets show that our method reaches the state-of-the-art. This project code will be available at \url{https://github.com/Fan-pixel/DCM-dehaze.
Artistic-style text detector and a new Movie-Poster dataset
Jun 24, 2024Although current text detection algorithms demonstrate effectiveness in general scenarios, their performance declines when confronted with artistic-style text featuring complex structures. This paper proposes a method that utilizes Criss-Cross Attention and residual dense block to address the incomplete and misdiagnosis of artistic-style text detection by current algorithms. Specifically, our method mainly consists of a feature extraction backbone, a feature enhancement network, a multi-scale feature fusion module, and a boundary discrimination module. The feature enhancement network significantly enhances the model's perceptual capabilities in complex environments by fusing horizontal and vertical contextual information, allowing it to capture detailed features overlooked in artistic-style text. We incorporate residual dense block into the Feature Pyramid Network to suppress the effect of background noise during feature fusion. Aiming to omit the complex post-processing, we explore a boundary discrimination module that guides the correct generation of boundary proposals. Furthermore, given that movie poster titles often use stylized art fonts, we collected a Movie-Poster dataset to address the scarcity of artistic-style text data. Extensive experiments demonstrate that our proposed method performs superiorly on the Movie-Poster dataset and produces excellent results on multiple benchmark datasets. The code and the Movie-Poster dataset will be available at: https://github.com/biedaxiaohua/Artistic-style-text-detection
Zero-LED: Zero-Reference Lighting Estimation Diffusion Model for Low-Light Image Enhancement
Mar 05, 2024



Diffusion model-based low-light image enhancement methods rely heavily on paired training data, leading to limited extensive application. Meanwhile, existing unsupervised methods lack effective bridging capabilities for unknown degradation. To address these limitations, we propose a novel zero-reference lighting estimation diffusion model for low-light image enhancement called Zero-LED. It utilizes the stable convergence ability of diffusion models to bridge the gap between low-light domains and real normal-light domains and successfully alleviates the dependence on pairwise training data via zero-reference learning. Specifically, we first design the initial optimization network to preprocess the input image and implement bidirectional constraints between the diffusion model and the initial optimization network through multiple objective functions. Subsequently, the degradation factors of the real-world scene are optimized iteratively to achieve effective light enhancement. In addition, we explore a frequency-domain based and semantically guided appearance reconstruction module that encourages feature alignment of the recovered image at a fine-grained level and satisfies subjective expectations. Finally, extensive experiments demonstrate the superiority of our approach to other state-of-the-art methods and more significant generalization capabilities. We will open the source code upon acceptance of the paper.