 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelational Graph Modeling for Credit Default Prediction: Heterogeneous GNNs and Hybrid Ensemble Learning
Jan 21, 2026Credit default risk arises from complex interactions among borrowers, financial institutions, and transaction-level behaviors. While strong tabular models remain highly competitive in credit scoring, they may fail to explicitly capture cross-entity dependencies embedded in multi-table financial histories. In this work, we construct a massive-scale heterogeneous graph containing over 31 million nodes and more than 50 million edges, integrating borrower attributes with granular transaction-level entities such as installment payments, POS cash balances, and credit card histories. We evaluate heterogeneous graph neural networks (GNNs), including heterogeneous GraphSAGE and a relation-aware attentive heterogeneous GNN, against strong tabular baselines. We find that standalone GNNs provide limited lift over a competitive gradient-boosted tree baseline, while a hybrid ensemble that augments tabular features with GNN-derived customer embeddings achieves the best overall performance, improving both ROC-AUC and PR-AUC. We further observe that contrastive pretraining can improve optimization stability but yields limited downstream gains under generic graph augmentations. Finally, we conduct structured explainability and fairness analyses to characterize how relational signals affect subgroup behavior and screening-oriented outcomes.
Optimizing Data Collection in Deep Reinforcement Learning
Jul 15, 2022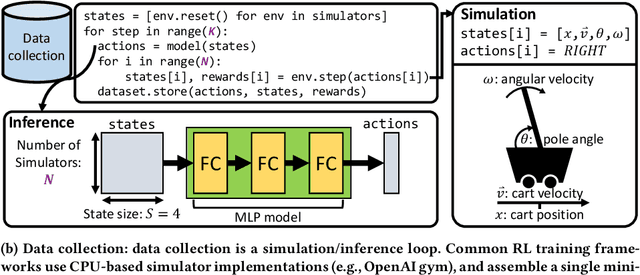
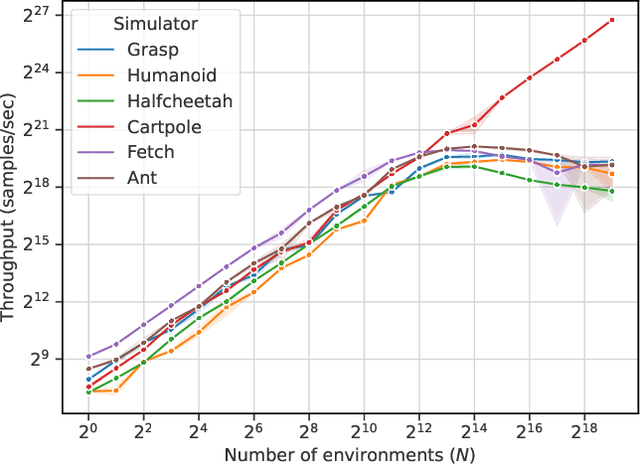
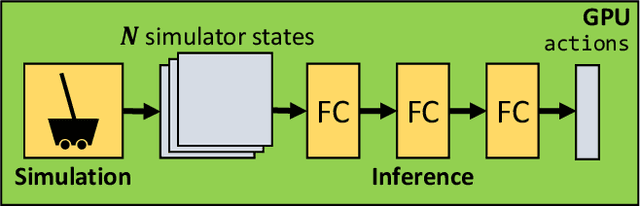
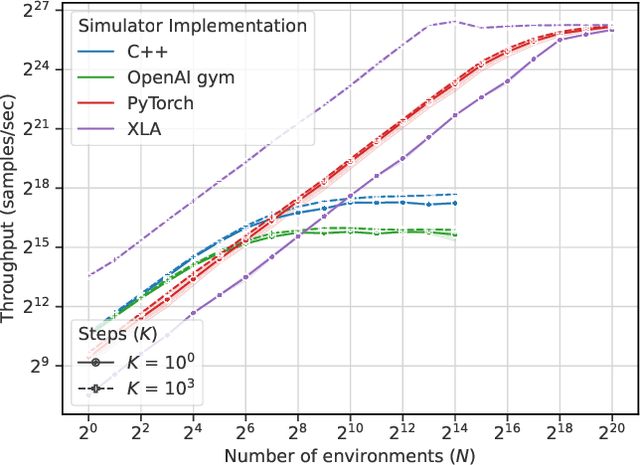
Reinforcement learning (RL) workloads take a notoriously long time to train due to the large number of samples collected at run-time from simulators. Unfortunately, cluster scale-up approaches remain expensive, and commonly used CPU implementations of simulators induce high overhead when switching back and forth between GPU computations. We explore two optimizations that increase RL data collection efficiency by increasing GPU utilization: (1) GPU vectorization: parallelizing simulation on the GPU for increased hardware parallelism, and (2) simulator kernel fusion: fusing multiple simulation steps to run in a single GPU kernel launch to reduce global memory bandwidth requirements. We find that GPU vectorization can achieve up to $1024\times$ speedup over commonly used CPU simulators. We profile the performance of different implementations and show that for a simple simulator, ML compiler implementations (XLA) of GPU vectorization outperform a DNN framework (PyTorch) by $13.4\times$ by reducing CPU overhead from repeated Python to DL backend API calls. We show that simulator kernel fusion speedups with a simple simulator are $11.3\times$ and increase by up to $1024\times$ as simulator complexity increases in terms of memory bandwidth requirements. We show that the speedups from simulator kernel fusion are orthogonal and combinable with GPU vectorization, leading to a multiplicative speedup.