 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOperator Fusion in XLA: Analysis and Evaluation
Paper and Code


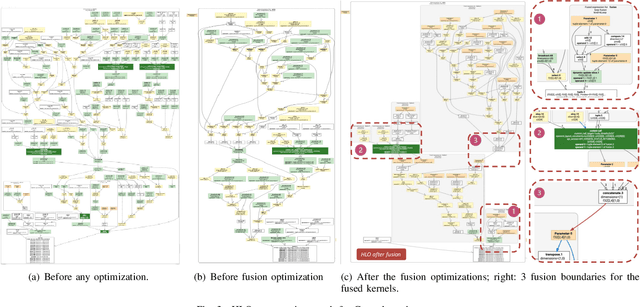

Machine learning (ML) compilers are an active area of research because they offer the potential to automatically speedup tensor programs. Kernel fusion is often cited as an important optimization performed by ML compilers. However, there exists a knowledge gap about how XLA, the most common ML compiler, applies this nuanced optimization, what kind of speedup it can afford, and what low-level effects it has on hardware. Our paper aims to bridge this knowledge gap by studying key compiler passes of XLA's source code. Our evaluation on a reinforcement learning environment Cartpole shows how different fusion decisions in XLA are made in practice. Furthermore, we implement several XLA kernel fusion strategies that can achieve up to 10.56x speedup compared to our baseline implementation.