 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Can You Say to a Robot? Capability Communication Leads to More Natural Conversations
Feb 03, 2025
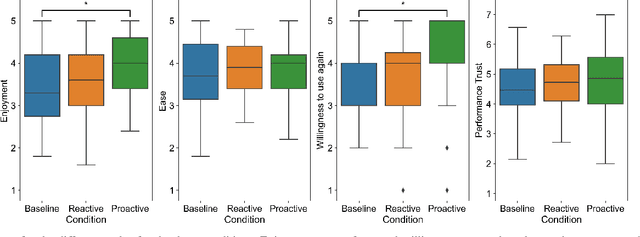
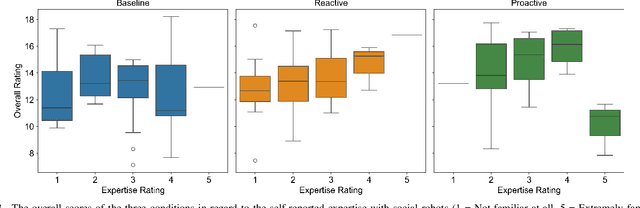
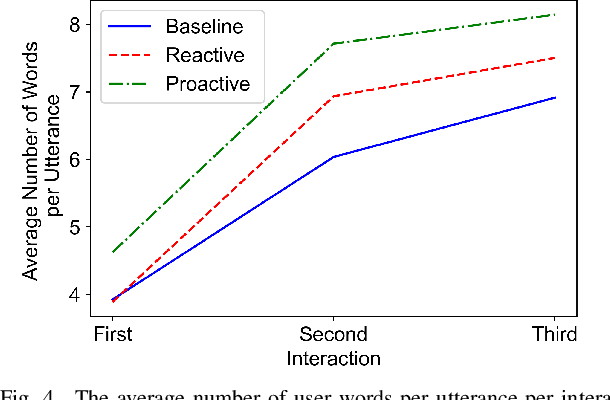
When encountering a robot in the wild, it is not inherently clear to human users what the robot's capabilities are. When encountering misunderstandings or problems in spoken interaction, robots often just apologize and move on, without additional effort to make sure the user understands what happened. We set out to compare the effect of two speech based capability communication strategies (proactive, reactive) to a robot without such a strategy, in regard to the user's rating of and their behavior during the interaction. For this, we conducted an in-person user study with 120 participants who had three speech-based interactions with a social robot in a restaurant setting. Our results suggest that users preferred the robot communicating its capabilities proactively and adjusted their behavior in those interactions, using a more conversational interaction style while also enjoying the interaction more.
Spectral oversubtraction? An approach for speech enhancement after robot ego speech filtering in semi-real-time
Sep 10, 2024


Spectral subtraction, widely used for its simplicity, has been employed to address the Robot Ego Speech Filtering (RESF) problem for detecting speech contents of human interruption from robot's single-channel microphone recordings when it is speaking. However, this approach suffers from oversubtraction in the fundamental frequency range (FFR), leading to degraded speech content recognition. To address this, we propose a Two-Mask Conformer-based Metric Generative Adversarial Network (CMGAN) to enhance the detected speech and improve recognition results. Our model compensates for oversubtracted FFR values with high-frequency information and long-term features and then de-noises the new spectrogram. In addition, we introduce an incremental processing method that allows semi-real-time audio processing with streaming input on a network trained on long fixed-length input. Evaluations of two datasets, including one with unseen noise, demonstrate significant improvements in recognition accuracy and the effectiveness of the proposed two-mask approach and incremental processing, enhancing the robustness of the proposed RESF pipeline in real-world HRI scenarios.
A Near-Real-Time Processing Ego Speech Filtering Pipeline Designed for Speech Interruption During Human-Robot Interaction
May 22, 2024With current state-of-the-art automatic speech recognition (ASR) systems, it is not possible to transcribe overlapping speech audio streams separately. Consequently, when these ASR systems are used as part of a social robot like Pepper for interaction with a human, it is common practice to close the robot's microphone while it is talking itself. This prevents the human users to interrupt the robot, which limits speech-based human-robot interaction. To enable a more natural interaction which allows for such interruptions, we propose an audio processing pipeline for filtering out robot's ego speech using only a single-channel microphone. This pipeline takes advantage of the possibility to feed the robot ego speech signal, generated by a text-to-speech API, as training data into a machine learning model. The proposed pipeline combines a convolutional neural network and spectral subtraction to extract overlapping human speech from the audio recorded by the robot-embedded microphone. When evaluating on a held-out test set, we find that this pipeline outperforms our previous approach to this task, as well as state-of-the-art target speech extraction systems that were retrained on the same dataset. We have also integrated the proposed pipeline into a lightweight robot software development framework to make it available for broader use. As a step towards demonstrating the feasibility of deploying our pipeline, we use this framework to evaluate the effectiveness of the pipeline in a small lab-based feasibility pilot using the social robot Pepper. Our results show that when participants interrupt the robot, the pipeline can extract the participant's speech from one-second streaming audio buffers received by the robot-embedded single-channel microphone, hence in near-real time.
A Survey on Dialogue Management in Human-Robot Interaction
Jul 20, 2023



As social robots see increasing deployment within the general public, improving the interaction with those robots is essential. Spoken language offers an intuitive interface for the human-robot interaction (HRI), with dialogue management (DM) being a key component in those interactive systems. Yet, to overcome current challenges and manage smooth, informative and engaging interaction a more structural approach to combining HRI and DM is needed. In this systematic review, we analyse the current use of DM in HRI and focus on the type of dialogue manager used, its capabilities, evaluation methods and the challenges specific to DM in HRI. We identify the challenges and current scientific frontier related to the DM approach, interaction domain, robot appearance, physical situatedness and multimodality.