 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Map to Find Them All: Real-time Open-Vocabulary Mapping for Zero-shot Multi-Object Navigation
Sep 18, 2024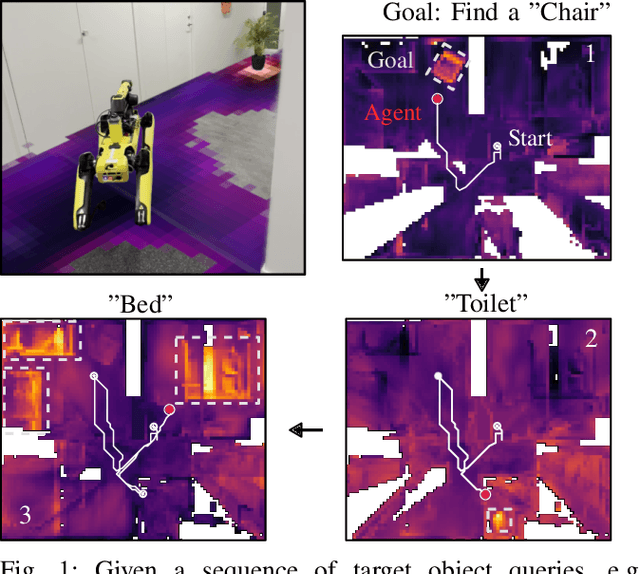
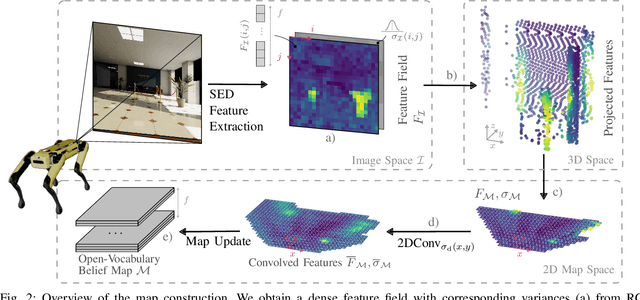
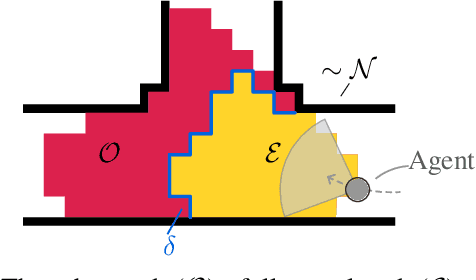
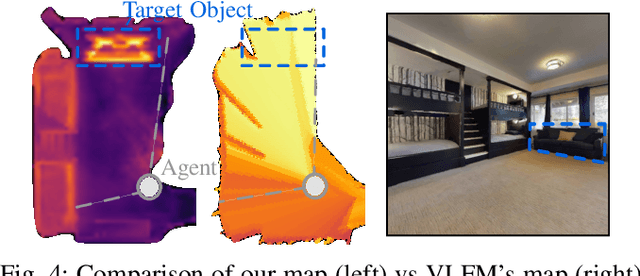
The capability to efficiently search for objects in complex environments is fundamental for many real-world robot applications. Recent advances in open-vocabulary vision models have resulted in semantically-informed object navigation methods that allow a robot to search for an arbitrary object without prior training. However, these zero-shot methods have so far treated the environment as unknown for each consecutive query. In this paper we introduce a new benchmark for zero-shot multi-object navigation, allowing the robot to leverage information gathered from previous searches to more efficiently find new objects. To address this problem we build a reusable open-vocabulary feature map tailored for real-time object search. We further propose a probabilistic-semantic map update that mitigates common sources of errors in semantic feature extraction and leverage this semantic uncertainty for informed multi-object exploration. We evaluate our method on a set of object navigation tasks in both simulation as well as with a real robot, running in real-time on a Jetson Orin AGX. We demonstrate that it outperforms existing state-of-the-art approaches both on single and multi-object navigation tasks. Additional videos, code and the multi-object navigation benchmark will be available on https://finnbsch.github.io/OneMap.
A Gaussian Process Model for Opponent Prediction in Autonomous Racing
Apr 26, 2022
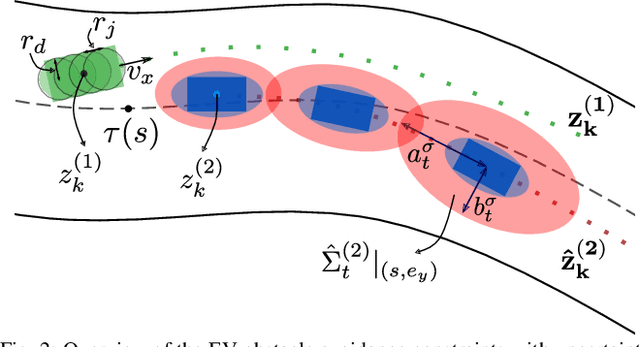
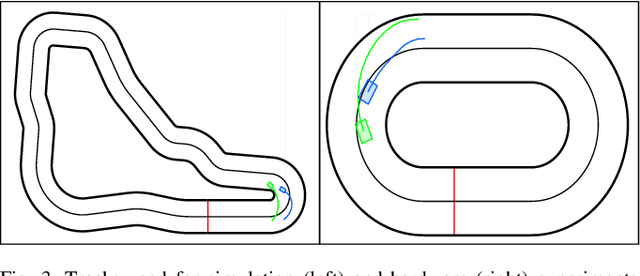
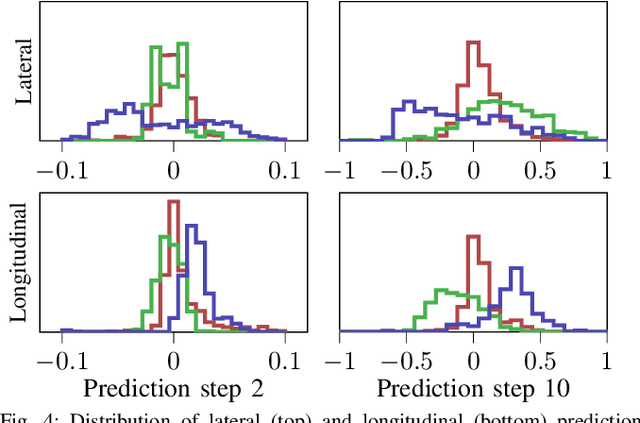
In head-to-head racing, performing tightly constrained, but highly rewarding maneuvers, such as overtaking, require an accurate model of interactive behavior of the opposing target vehicle (TV). However, such information is not typically made available in competitive scenarios, we therefore propose to construct a prediction and uncertainty model given data of the TV from previous races. In particular, a one-step Gaussian Process (GP) model is trained on closed-loop interaction data to learn the behavior of a TV driven by an unknown policy. Predictions of the nominal trajectory and associated uncertainty are rolled out via a sampling-based approach and are used in a model predictive control (MPC) policy for the ego vehicle in order to intelligently trade-off between safety and performance when attempting overtaking maneuvers against a TV. We demonstrate the GP-based predictor in closed loop with the MPC policy in simulation races and compare its performance against several predictors from literature. In a Monte Carlo study, we observe that the GP-based predictor achieves similar win rates while maintaining safety in up to 3x more races. We finally demonstrate the prediction and control framework in real-time on hardware experiments.