 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTHÖR-MAGNI Act: Actions for Human Motion Modeling in Robot-Shared Industrial Spaces
Dec 18, 2024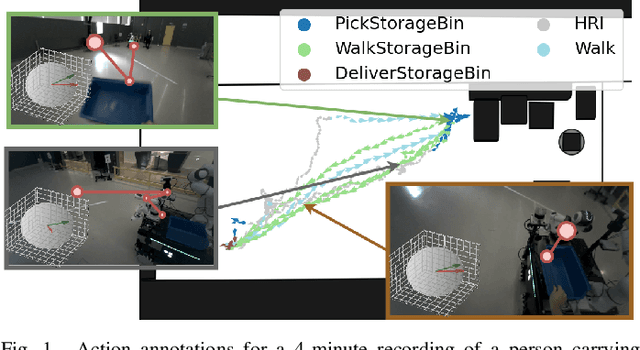
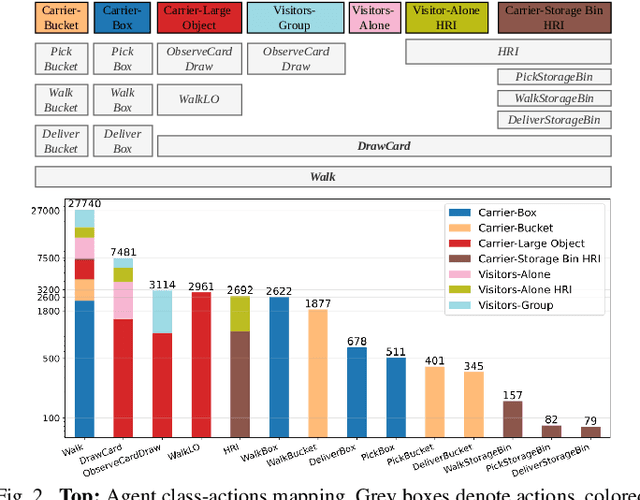
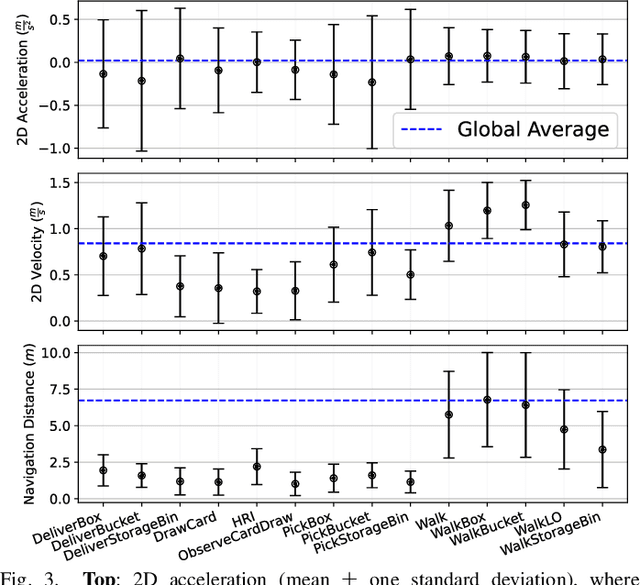
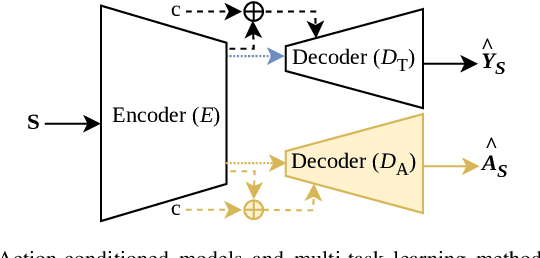
Accurate human activity and trajectory prediction are crucial for ensuring safe and reliable human-robot interactions in dynamic environments, such as industrial settings, with mobile robots. Datasets with fine-grained action labels for moving people in industrial environments with mobile robots are scarce, as most existing datasets focus on social navigation in public spaces. This paper introduces the TH\"OR-MAGNI Act dataset, a substantial extension of the TH\"OR-MAGNI dataset, which captures participant movements alongside robots in diverse semantic and spatial contexts. TH\"OR-MAGNI Act provides 8.3 hours of manually labeled participant actions derived from egocentric videos recorded via eye-tracking glasses. These actions, aligned with the provided TH\"OR-MAGNI motion cues, follow a long-tailed distribution with diversified acceleration, velocity, and navigation distance profiles. We demonstrate the utility of TH\"OR-MAGNI Act for two tasks: action-conditioned trajectory prediction and joint action and trajectory prediction. We propose two efficient transformer-based models that outperform the baselines to address these tasks. These results underscore the potential of TH\"OR-MAGNI Act to develop predictive models for enhanced human-robot interaction in complex environments.