 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval-Augmented Generation for Service Discovery: Chunking Strategies and Benchmarking
May 25, 2025Integrating multiple (sub-)systems is essential to create advanced Information Systems. Difficulties mainly arise when integrating dynamic environments, e.g., the integration at design time of not yet existing services. This has been traditionally addressed using a registry that provides the API documentation of the endpoints. Large Language Models have shown to be capable of automatically creating system integrations (e.g., as service composition) based on this documentation but require concise input due to input oken limitations, especially regarding comprehensive API descriptions. Currently, it is unknown how best to preprocess these API descriptions. In the present work, we (i) analyze the usage of Retrieval Augmented Generation for endpoint discovery and the chunking, i.e., preprocessing, of state-of-practice OpenAPIs to reduce the input oken length while preserving the most relevant information. To further reduce the input token length for the composition prompt and improve endpoint retrieval, we propose (ii) a Discovery Agent that only receives a summary of the most relevant endpoints nd retrieves specification details on demand. We evaluate RAG for endpoint discovery using (iii) a proposed novel service discovery benchmark SOCBench-D representing a general setting across numerous domains and the real-world RestBench enchmark, first, for the different chunking possibilities and parameters measuring the endpoint retrieval accuracy. Then, we assess the Discovery Agent using the same test data set. The prototype shows how to successfully employ RAG for endpoint discovery to reduce the token count. Our experiments show that endpoint-based approaches outperform naive chunking methods for preprocessing. Relying on an agent significantly improves precision while being prone to decrease recall, disclosing the need for further reasoning capabilities.
Advanced System Integration: Analyzing OpenAPI Chunking for Retrieval-Augmented Generation
Nov 29, 2024

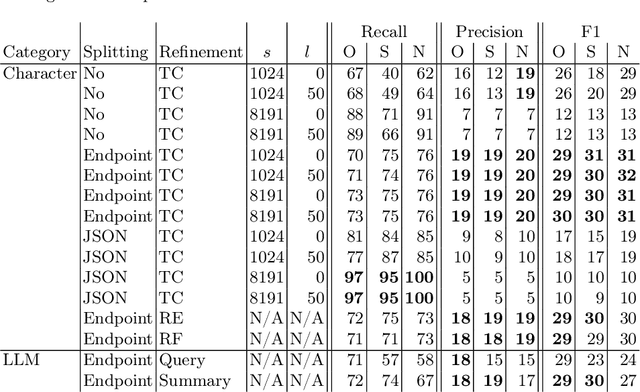
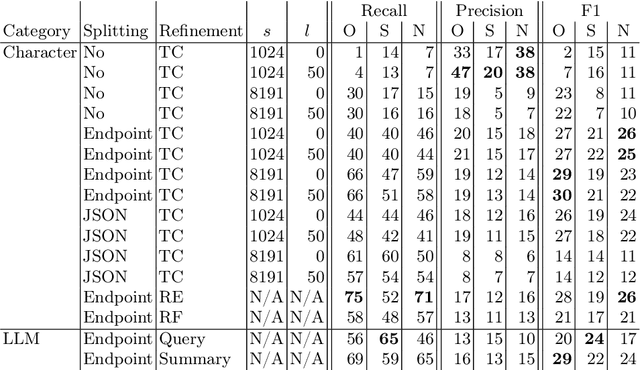
Integrating multiple (sub-)systems is essential to create advanced Information Systems (ISs). Difficulties mainly arise when integrating dynamic environments across the IS lifecycle. A traditional approach is a registry that provides the API documentation of the systems' endpoints. Large Language Models (LLMs) have shown to be capable of automatically creating system integrations (e.g., as service composition) based on this documentation but require concise input due to input token limitations, especially regarding comprehensive API descriptions. Currently, it is unknown how best to preprocess these API descriptions. Within this work, we (i) analyze the usage of Retrieval Augmented Generation (RAG) for endpoint discovery and the chunking, i.e., preprocessing, of OpenAPIs to reduce the input token length while preserving the most relevant information. To further reduce the input token length for the composition prompt and improve endpoint retrieval, we propose (ii) a Discovery Agent that only receives a summary of the most relevant endpoints and retrieves details on demand. We evaluate RAG for endpoint discovery using the RestBench benchmark, first, for the different chunking possibilities and parameters measuring the endpoint retrieval recall, precision, and F1 score. Then, we assess the Discovery Agent using the same test set. With our prototype, we demonstrate how to successfully employ RAG for endpoint discovery to reduce the token count. While revealing high values for recall, precision, and F1, further research is necessary to retrieve all requisite endpoints. Our experiments show that for preprocessing, LLM-based and format-specific approaches outperform na\"ive chunking methods. Relying on an agent further enhances these results as the agent splits the tasks into multiple fine granular subtasks, improving the overall RAG performance in the token count, precision, and F1 score.
Enhancing Object Detection in Ancient Documents with Synthetic Data Generation and Transformer-Based Models
Jul 29, 2023The study of ancient documents provides a glimpse into our past. However, the low image quality and intricate details commonly found in these documents present significant challenges for accurate object detection. The objective of this research is to enhance object detection in ancient documents by reducing false positives and improving precision. To achieve this, we propose a method that involves the creation of synthetic datasets through computational mediation, along with the integration of visual feature extraction into the object detection process. Our approach includes associating objects with their component parts and introducing a visual feature map to enable the model to discern between different symbols and document elements. Through our experiments, we demonstrate that improved object detection has a profound impact on the field of Paleography, enabling in-depth analysis and fostering a greater understanding of these valuable historical artifacts.
Towards Intelligent Robotic Process Automation for BPMers
Jan 03, 2020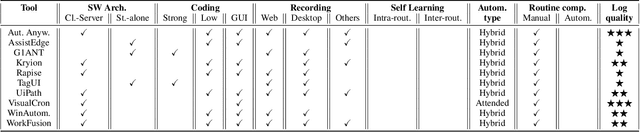
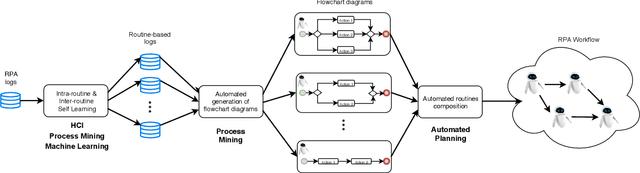
Robotic Process Automation (RPA) is a fast-emerging automation technology that sits between the fields of Business Process Management (BPM) and Artificial Intelligence (AI), and allows organizations to automate high volume routines. RPA tools are able to capture the execution of such routines previously performed by a human users on the interface of a computer system, and then emulate their enactment in place of the user by means of a software robot. Nowadays, in the BPM domain, only simple, predictable business processes involving routine work can be automated by RPA tools in situations where there is no room for interpretation, while more sophisticated work is still left to human experts. In this paper, starting from an in-depth experimentation of the RPA tools available on the market, we provide a classification framework to categorize them on the basis of some key dimensions. Then, based on this analysis, we derive four research challenges and discuss prospective approaches necessary to inject intelligence into current RPA technology, in order to achieve more widespread adoption of RPA in the BPM domain.