 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Domain Adaptation: A Generative View
Paper and Code
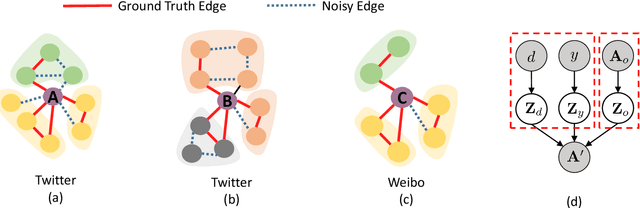
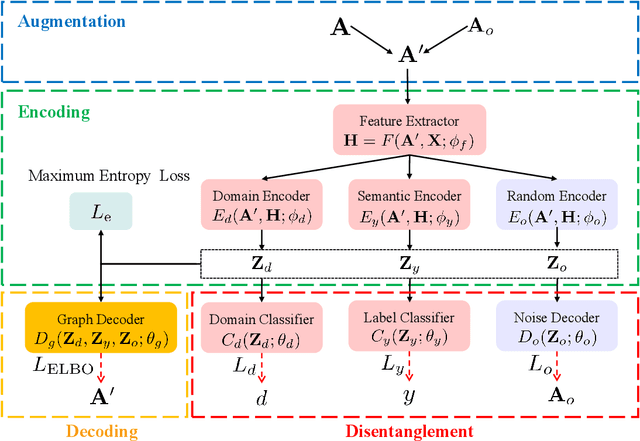
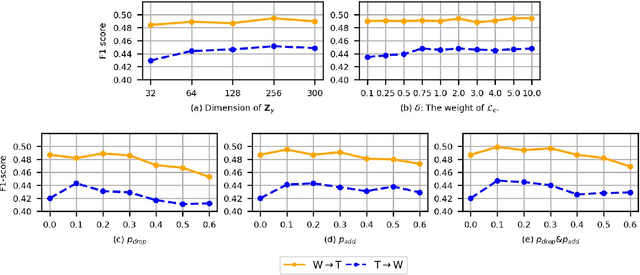
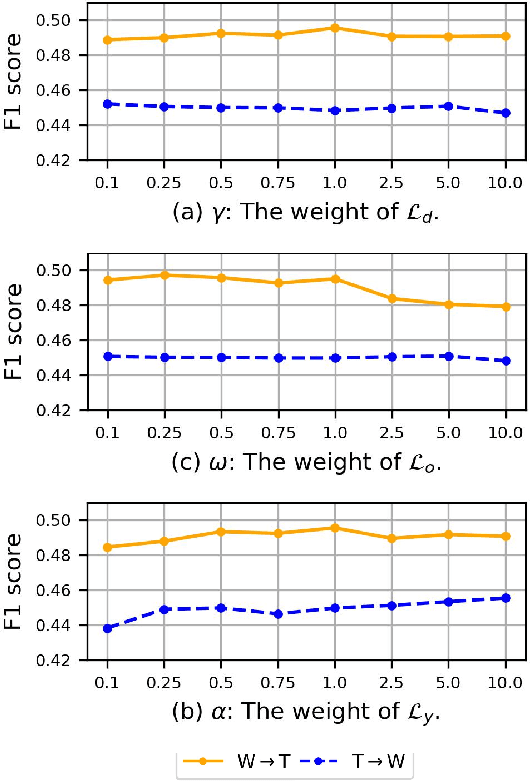
Recent years have witnessed tremendous interest in deep learning on graph-structured data. Due to the high cost of collecting labeled graph-structured data, domain adaptation is important to supervised graph learning tasks with limited samples. However, current graph domain adaptation methods are generally adopted from traditional domain adaptation tasks, and the properties of graph-structured data are not well utilized. For example, the observed social networks on different platforms are controlled not only by the different crowd or communities but also by the domain-specific policies and the background noise. Based on these properties in graph-structured data, we first assume that the graph-structured data generation process is controlled by three independent types of latent variables, i.e., the semantic latent variables, the domain latent variables, and the random latent variables. Based on this assumption, we propose a disentanglement-based unsupervised domain adaptation method for the graph-structured data, which applies variational graph auto-encoders to recover these latent variables and disentangles them via three supervised learning modules. Extensive experimental results on two real-world datasets in the graph classification task reveal that our method not only significantly outperforms the traditional domain adaptation methods and the disentangled-based domain adaptation methods but also outperforms the state-of-the-art graph domain adaptation algorithms.