 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Eigen Attack on Black-Box Models
Aug 27, 2020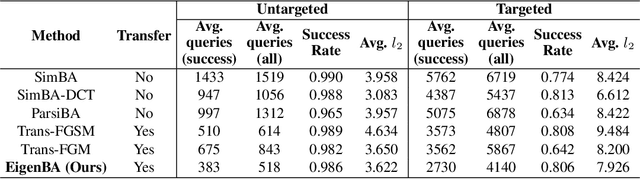



Black-box adversarial attack has attracted a lot of research interests for its practical use in AI safety. Compared with the white-box attack, a black-box setting is more difficult for less available information related to the attacked model and the additional constraint on the query budget. A general way to improve the attack efficiency is to draw support from a pre-trained transferable white-box model. In this paper, we propose a novel setting of transferable black-box attack: attackers may use external information from a pre-trained model with available network parameters, however, different from previous studies, no additional training data is permitted to further change or tune the pre-trained model. To this end, we further propose a new algorithm, EigenBA to tackle this problem. Our method aims to explore more gradient information of the black-box model, and promote the attack efficiency, while keeping the perturbation to the original attacked image small, by leveraging the Jacobian matrix of the pre-trained white-box model. We show the optimal perturbations are closely related to the right singular vectors of the Jacobian matrix. Further experiments on ImageNet and CIFAR-10 show that even the unlearnable pre-trained white-box model could also significantly boost the efficiency of the black-box attack and our proposed method could further improve the attack efficiency.
Learning to Select Base Classes for Few-shot Classification
Apr 01, 2020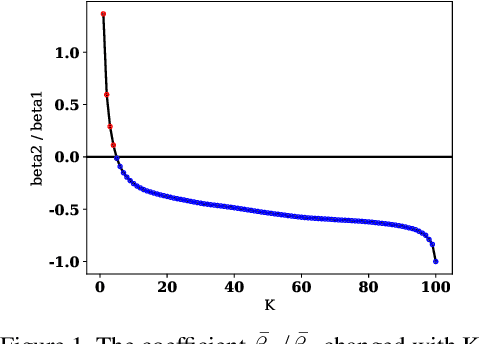

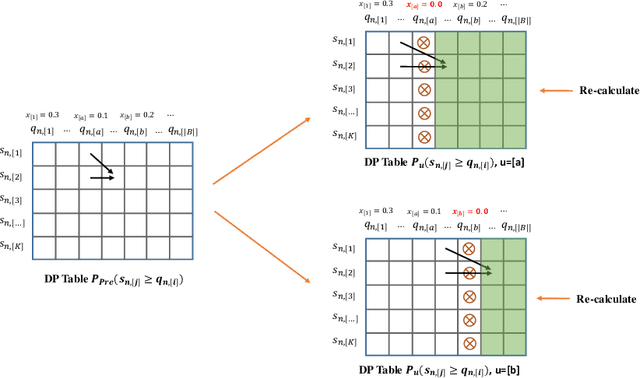
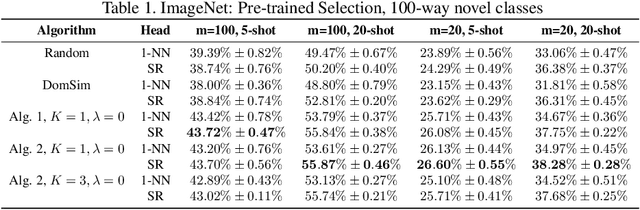
Few-shot learning has attracted intensive research attention in recent years. Many methods have been proposed to generalize a model learned from provided base classes to novel classes, but no previous work studies how to select base classes, or even whether different base classes will result in different generalization performance of the learned model. In this paper, we utilize a simple yet effective measure, the Similarity Ratio, as an indicator for the generalization performance of a few-shot model. We then formulate the base class selection problem as a submodular optimization problem over Similarity Ratio. We further provide theoretical analysis on the optimization lower bound of different optimization methods, which could be used to identify the most appropriate algorithm for different experimental settings. The extensive experiments on ImageNet, Caltech256 and CUB-200-2011 demonstrate that our proposed method is effective in selecting a better base dataset.
Learning to Learn Image Classifiers with Informative Visual Analogy
Oct 17, 2017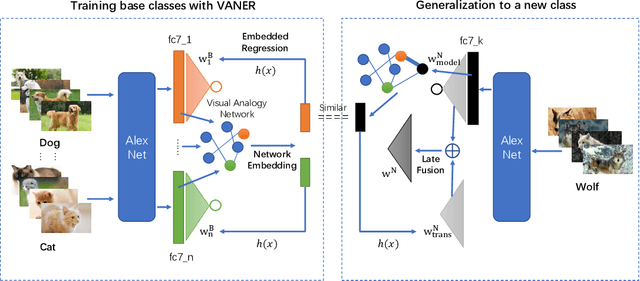
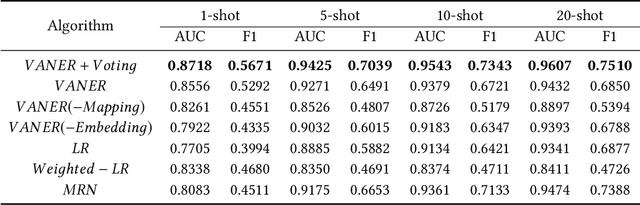
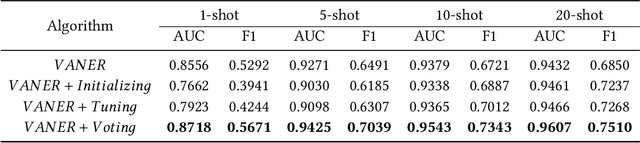
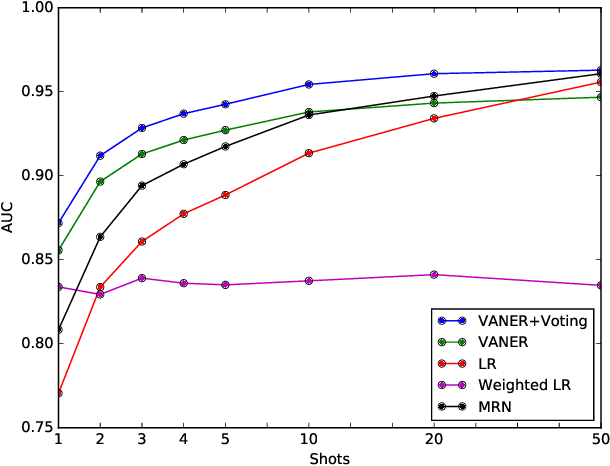
In recent years, we witnessed a huge success of Convolutional Neural Networks on the task of the image classification. However, these models are notoriously data hungry and require tons of training images to learn the parameters. In contrast, people are far better learner who can learn a new concept very fast with only a few samples. The plausible mysteries making the difference are two fundamental learning mechanisms: learning to learn and learning by analogy. In this paper, we attempt to investigate a new human-like learning method by organically combining these two mechanisms. In particular, we study how to generalize the classification parameters of previously learned concepts to a new concept. we first propose a novel Visual Analogy Network Embedded Regression (VANER) model to jointly learn a low-dimensional embedding space and a linear mapping function from the embedding space to classification parameters for base classes. We then propose an out-of-sample embedding method to learn the embedding of a new class represented by a few samples through its visual analogy with base classes. By inputting the learned embedding into VANER, we can derive the classification parameters for the new class.These classification parameters are purely generalized from base classes (i.e. transferred classification parameters), while the samples in the new class, although only a few, can also be exploited to generate a set of classification parameters (i.e. model classification parameters). Therefore, we further investigate the fusion strategy of the two kinds of parameters so that the prior knowledge and data knowledge can be fully leveraged. We also conduct extensive experiments on ImageNet and the results show that our method can consistently and significantly outperform state-of-the-art baselines.
Binary Stereo Matching
Feb 10, 2014
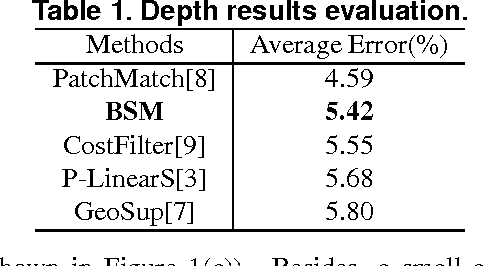
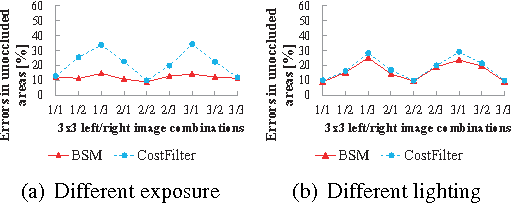

In this paper, we propose a novel binary-based cost computation and aggregation approach for stereo matching problem. The cost volume is constructed through bitwise operations on a series of binary strings. Then this approach is combined with traditional winner-take-all strategy, resulting in a new local stereo matching algorithm called binary stereo matching (BSM). Since core algorithm of BSM is based on binary and integer computations, it has a higher computational efficiency than previous methods. Experimental results on Middlebury benchmark show that BSM has comparable performance with state-of-the-art local stereo methods in terms of both quality and speed. Furthermore, experiments on images with radiometric differences demonstrate that BSM is more robust than previous methods under these changes, which is common under real illumination.