 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaveform-Domain Complementary Signal Sets for Interrupted Sampling Repeater Jamming Suppression
Jan 19, 2024



The interrupted-sampling repeater jamming (ISRJ) is coherent and has the characteristic of suppression and deception to degrade the radar detection capabilities. The study focuses on anti-ISRJ techniques in the waveform domain, primarily capitalizing on waveform design and and anti-jamming signal processing methods in the waveform domain. By exploring the relationship between waveform-domain adaptive matched filtering (WD-AMF) output and waveform-domain signals, we demonstrate that ISRJ can be effectively suppressed when the transmitted waveform exhibits waveform-domain complementarity. We introduce a phase-coded (PC) waveform set with waveform-domain complementarity and propose a method for generating such waveform sets of arbitrary code lengths. The performance of WD-AMF are further developed due to the designed waveforms, and simulations affirm the superior adaptive anti-jamming capabilities of the designed waveforms compared to traditional ones. Remarkably, this improved performance is achieved without the need for prior knowledge of ISRJ interference parameters at either the transmitter or receiver stages.
Waveform-Domain Adaptive Matched Filtering: A Novel Approach to Suppressing Interrupted-Sampling Repeater Jamming
Jul 07, 2023



The inadequate adaptability to flexible interference scenarios remains an unresolved challenge in the majority of techniques utilized for mitigating interrupted-sampling repeater jamming (ISRJ). Matched filtering system based methods is desirable to incorporate anti-ISRJ measures based on prior ISRJ modeling, either preceding or succeeding the matched filtering. Due to the partial matching nature of ISRJ, its characteristics are revealed during the process of matched filtering. Therefore, this paper introduces an extended domain called the waveform domain within the matched filtering process. On this domain, a novel matched filtering model, known as the waveform-domain adaptive matched filtering (WD-AMF), is established to tackle the problem of ISRJ suppression without relying on a pre-existing ISRJ model. The output of the WD-AMF encompasses an adaptive filtering term and a compensation term. The adaptive filtering term encompasses the adaptive integration outcomes in the waveform domain, which are determined by an adaptive weighted function. This function, akin to a collection of bandpass filters, decomposes the integrated function into multiple components, some of which contain interference while others do not. The compensation term adheres to an integrated guideline for discerning the presence of signal components or noise within the integrated function. The integration results are then concatenated to reconstruct a compensated matched filter signal output. Simulations are conducted to showcase the exceptional capability of the proposed method in suppressing ISRJ in diverse interference scenarios, even in the absence of a pre-existing ISRJ model.
Statistical Loss and Analysis for Deep Learning in Hyperspectral Image Classification
Dec 28, 2019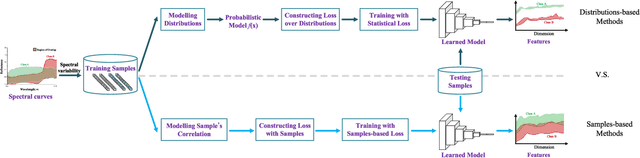
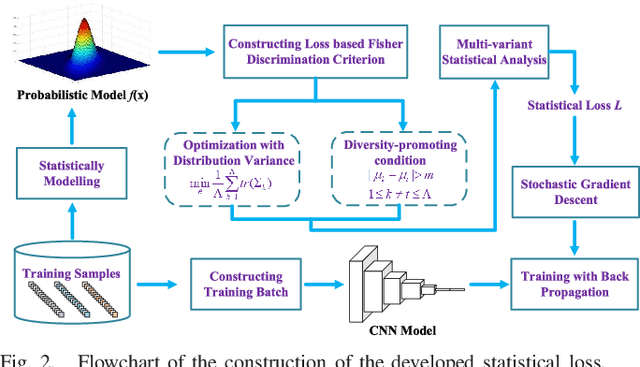

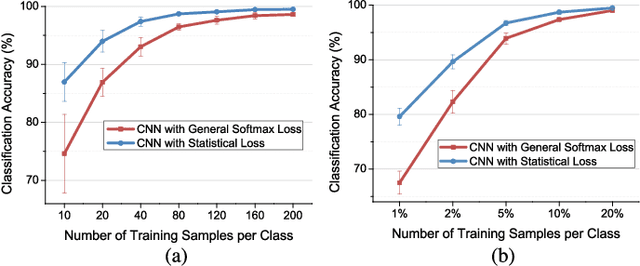
Nowadays, deep learning methods, especially the convolutional neural networks (CNNs), have shown impressive performance on extracting abstract and high-level features from the hyperspectral image. However, general training process of CNNs mainly considers the pixel-wise information or the samples' correlation to formulate the penalization while ignores the statistical properties especially the spectral variability of each class in the hyperspectral image. These samples-based penalizations would lead to the uncertainty of the training process due to the imbalanced and limited number of training samples. To overcome this problem, this work characterizes each class from the hyperspectral image as a statistical distribution and further develops a novel statistical loss with the distributions, not directly with samples for deep learning. Based on the Fisher discrimination criterion, the loss penalizes the sample variance of each class distribution to decrease the intra-class variance of the training samples. Moreover, an additional diversity-promoting condition is added to enlarge the inter-class variance between different class distributions and this could better discriminate samples from different classes in hyperspectral image. Finally, the statistical estimation form of the statistical loss is developed with the training samples through multi-variant statistical analysis. Experiments over the real-world hyperspectral images show the effectiveness of the developed statistical loss for deep learning.
Deep Manifold Embedding for Hyperspectral Image Classification
Dec 24, 2019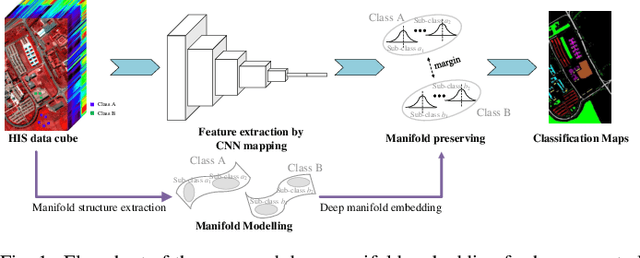

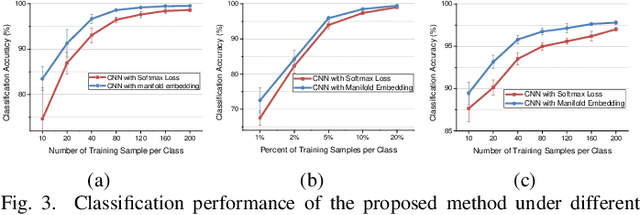
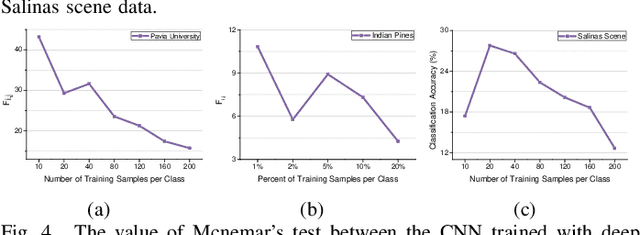
Deep learning methods have played a more and more important role in hyperspectral image classification. However, the general deep learning methods mainly take advantage of the information of sample itself or the pairwise information between samples while ignore the intrinsic data structure within the whole data. To tackle this problem, this work develops a novel deep manifold embedding method(DMEM) for hyperspectral image classification. First, each class in the image is modelled as a specific nonlinear manifold and the geodesic distance is used to measure the correlation between the samples. Then, based on the hierarchical clustering, the manifold structure of the data can be captured and each nonlinear data manifold can be divided into several sub-classes. Finally, considering the distribution of each sub-class and the correlation between different subclasses, the DMEM is constructed to preserve the estimated geodesic distances on the data manifold between the learned low dimensional features of different samples. Experiments over three real-world hyperspectral image datasets have demonstrated the effectiveness of the proposed method.
A novel statistical metric learning for hyperspectral image classification
May 13, 2019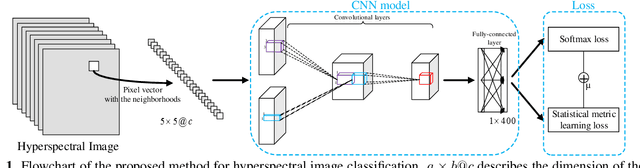
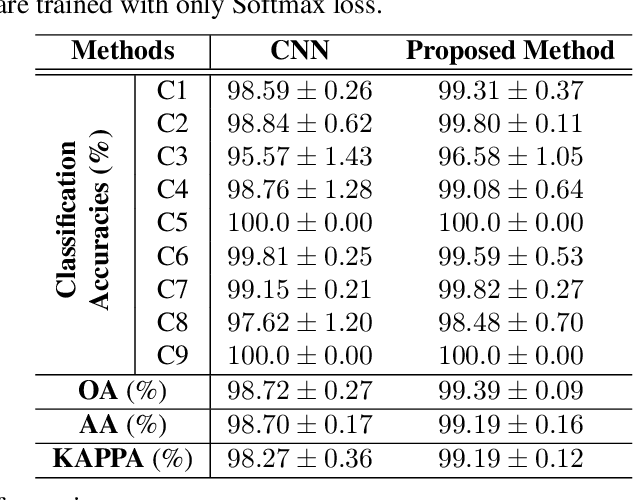

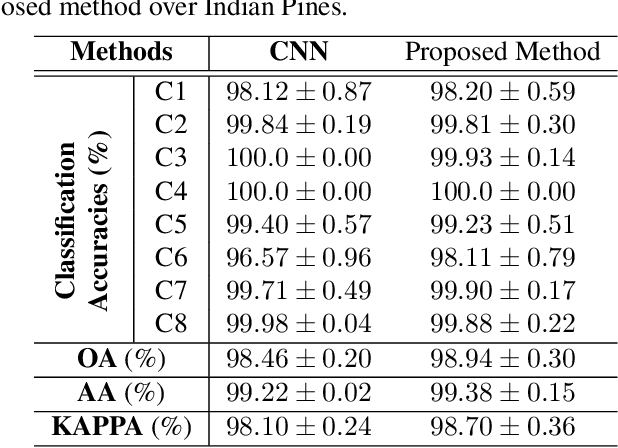
In this paper, a novel statistical metric learning is developed for spectral-spatial classification of the hyperspectral image. First, the standard variance of the samples of each class in each batch is used to decrease the intra-class variance within each class. Then, the distances between the means of different classes are used to penalize the inter-class variance of the training samples. Finally, the standard variance between the means of different classes is added as an additional diversity term to repulse different classes from each other. Experiments have conducted over two real-world hyperspectral image datasets and the experimental results have shown the effectiveness of the proposed statistical metric learning.
High-level Semantic Feature Detection: A New Perspective for Pedestrian Detection
Apr 23, 2019
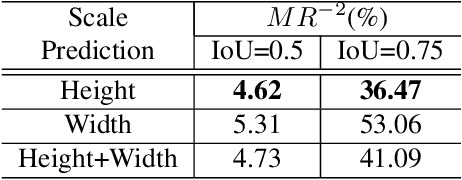
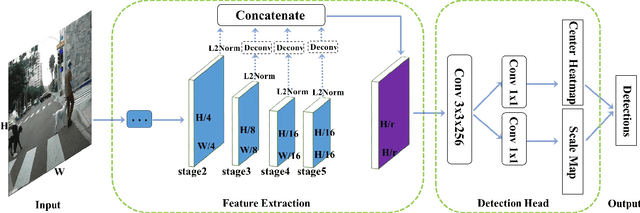
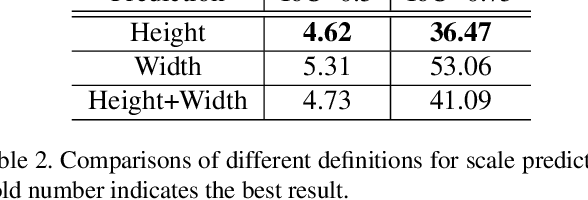
Object detection generally requires sliding-window classifiers in tradition or anchor-based predictions in modern deep learning approaches. However, either of these approaches requires tedious configurations in windows or anchors. In this paper, taking pedestrian detection as an example, we provide a new perspective where detecting objects is motivated as a high-level semantic feature detection task. Like edges, corners, blobs and other feature detectors, the proposed detector scans for feature points all over the image, for which the convolution is naturally suited. However, unlike these traditional low-level features, the proposed detector goes for a higher-level abstraction, that is, we are looking for central points where there are pedestrians, and modern deep models are already capable of such a high-level semantic abstraction. Besides, like blob detection, we also predict the scales of the pedestrian points, which is also a straightforward convolution. Therefore, in this paper, pedestrian detection is simplified as a straightforward center and scale prediction task through convolutions. This way, the proposed method enjoys an anchor-free setting. Though structurally simple, it presents competitive accuracy and good speed on challenging pedestrian detection benchmarks, and hence leading to a new attractive pedestrian detector. Code and models will be available at \url{https://github.com/liuwei16/CSP}.
An End-to-End Joint Unsupervised Learning of Deep Model and Pseudo-Classes for Remote Sensing Scene Representation
Mar 18, 2019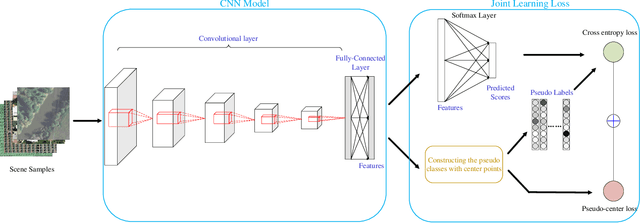
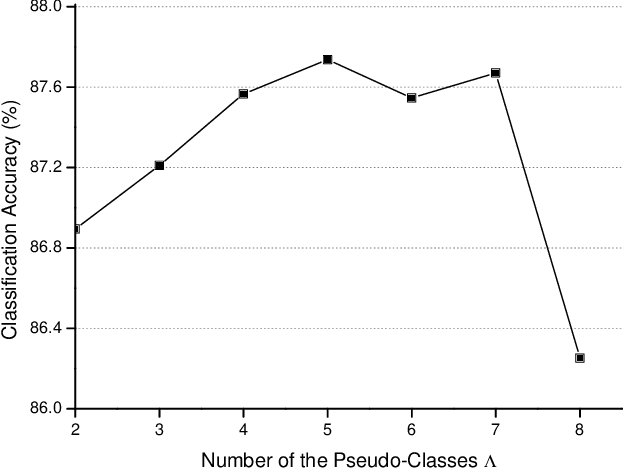
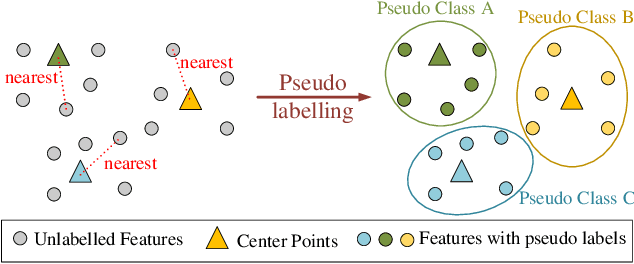

This work develops a novel end-to-end deep unsupervised learning method based on convolutional neural network (CNN) with pseudo-classes for remote sensing scene representation. First, we introduce center points as the centers of the pseudo classes and the training samples can be allocated with pseudo labels based on the center points. Therefore, the CNN model, which is used to extract features from the scenes, can be trained supervised with the pseudo labels. Moreover, a pseudo-center loss is developed to decrease the variance between the samples and the corresponding pseudo center point. The pseudo-center loss is important since it can update both the center points with the training samples and the CNN model with the center points in the training process simultaneously. Finally, joint learning of the pseudo-center loss and the pseudo softmax loss which is formulated with the samples and the pseudo labels is developed for unsupervised remote sensing scene representation to obtain discriminative representations from the scenes. Experiments are conducted over two commonly used remote sensing scene datasets to validate the effectiveness of the proposed method and the experimental results show the superiority of the proposed method when compared with other state-of-the-art methods.
Diversity in Machine Learning
Jul 04, 2018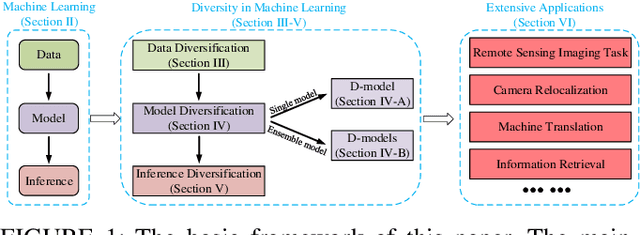
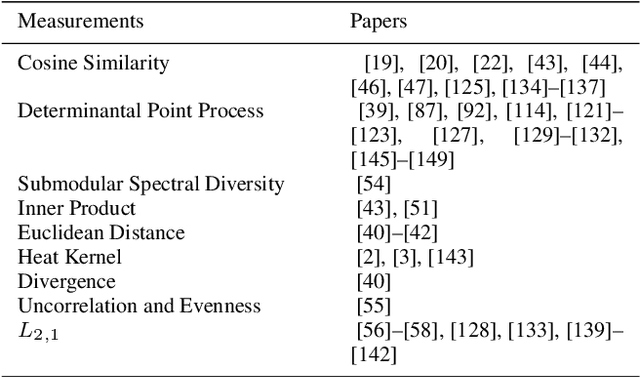
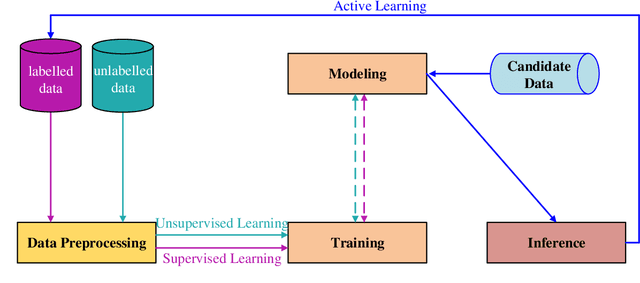

Machine learning methods have achieved good performance and been widely applied in various real-world applications. It can learn the model adaptively and be better fit for special requirements of different tasks. Many factors can affect the performance of the machine learning process, among which diversity of the machine learning is an important one. Generally, a good machine learning system is composed of plentiful training data, a good model training process, and an accurate inference. The diversity could help each procedure to guarantee a total good machine learning: diversity of the training data ensures the data contain enough discriminative information, diversity of the learned model (diversity in parameters of each model or diversity in models) makes each parameter/model capture unique or complement information and the diversity in inference can provide multiple choices each of which corresponds to a plausible result. However, there is no systematical analysis of the diversification in machine learning system. In this paper, we systematically summarize the methods to make data diversification, model diversification, and inference diversification in machine learning process, respectively. In addition, the typical applications where the diversity technology improved the machine learning performances have been surveyed, including the remote sensing imaging tasks, machine translation, camera relocalization, image segmentation, object detection, topic modeling, and others. Finally, we discuss some challenges of diversity technology in machine learning and point out some directions in future work. Our analysis provides a deeper understanding of the diversity technology in machine learning tasks, and hence can help design and learn more effective models for specific tasks.
Binary Stereo Matching
Feb 10, 2014
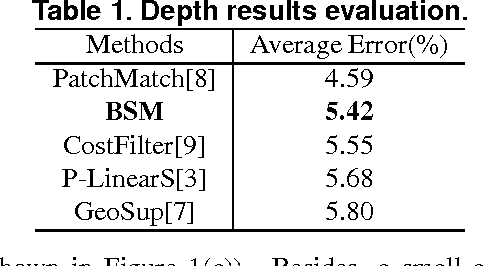
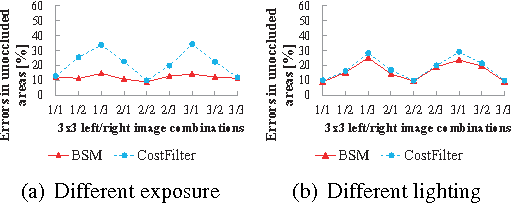

In this paper, we propose a novel binary-based cost computation and aggregation approach for stereo matching problem. The cost volume is constructed through bitwise operations on a series of binary strings. Then this approach is combined with traditional winner-take-all strategy, resulting in a new local stereo matching algorithm called binary stereo matching (BSM). Since core algorithm of BSM is based on binary and integer computations, it has a higher computational efficiency than previous methods. Experimental results on Middlebury benchmark show that BSM has comparable performance with state-of-the-art local stereo methods in terms of both quality and speed. Furthermore, experiments on images with radiometric differences demonstrate that BSM is more robust than previous methods under these changes, which is common under real illumination.