 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Intelligent Urban Park Development Monitoring: LLM Agents for Multi-Modal Information Fusion and Analysis
Jan 28, 2026As an important part of urbanization, the development monitoring of newly constructed parks is of great significance for evaluating the effect of urban planning and optimizing resource allocation. However, traditional change detection methods based on remote sensing imagery have obvious limitations in high-level and intelligent analysis, and thus are difficult to meet the requirements of current urban planning and management. In face of the growing demand for complex multi-modal data analysis in urban park development monitoring, these methods often fail to provide flexible analysis capabilities for diverse application scenarios. This study proposes a multi-modal LLM agent framework, which aims to make full use of the semantic understanding and reasoning capabilities of LLM to meet the challenges in urban park development monitoring. In this framework, a general horizontal and vertical data alignment mechanism is designed to ensure the consistency and effective tracking of multi-modal data. At the same time, a specific toolkit is constructed to alleviate the hallucination issues of LLM due to the lack of domain-specific knowledge. Compared to vanilla GPT-4o and other agents, our approach enables robust multi-modal information fusion and analysis, offering reliable and scalable solutions tailored to the diverse and evolving demands of urban park development monitoring.
LLM Agent Framework for Intelligent Change Analysis in Urban Environment using Remote Sensing Imagery
Jan 06, 2026Existing change detection methods often lack the versatility to handle diverse real-world queries and the intelligence for comprehensive analysis. This paper presents a general agent framework, integrating Large Language Models (LLM) with vision foundation models to form ChangeGPT. A hierarchical structure is employed to mitigate hallucination. The agent was evaluated on a curated dataset of 140 questions categorized by real-world scenarios, encompassing various question types (e.g., Size, Class, Number) and complexities. The evaluation assessed the agent's tool selection ability (Precision/Recall) and overall query accuracy (Match). ChangeGPT, especially with a GPT-4-turbo backend, demonstrated superior performance, achieving a 90.71 % Match rate. Its strength lies particularly in handling change-related queries requiring multi-step reasoning and robust tool selection. Practical effectiveness was further validated through a real-world urban change monitoring case study in Qianhai Bay, Shenzhen. By providing intelligence, adaptability, and multi-type change analysis, ChangeGPT offers a powerful solution for decision-making in remote sensing applications.
A Clinician-Friendly Platform for Ophthalmic Image Analysis Without Technical Barriers
Apr 22, 2025Artificial intelligence (AI) shows remarkable potential in medical imaging diagnostics, but current models typically require retraining when deployed across different clinical centers, limiting their widespread adoption. We introduce GlobeReady, a clinician-friendly AI platform that enables ocular disease diagnosis without retraining/fine-tuning or technical expertise. GlobeReady achieves high accuracy across imaging modalities: 93.9-98.5% for an 11-category fundus photo dataset and 87.2-92.7% for a 15-category OCT dataset. Through training-free local feature augmentation, it addresses domain shifts across centers and populations, reaching an average accuracy of 88.9% across five centers in China, 86.3% in Vietnam, and 90.2% in the UK. The built-in confidence-quantifiable diagnostic approach further boosted accuracy to 94.9-99.4% (fundus) and 88.2-96.2% (OCT), while identifying out-of-distribution cases at 86.3% (49 CFP categories) and 90.6% (13 OCT categories). Clinicians from multiple countries rated GlobeReady highly (average 4.6 out of 5) for its usability and clinical relevance. These results demonstrate GlobeReady's robust, scalable diagnostic capability and potential to support ophthalmic care without technical barriers.
Variational Speech Waveform Compression to Catalyze Semantic Communications
Dec 13, 2022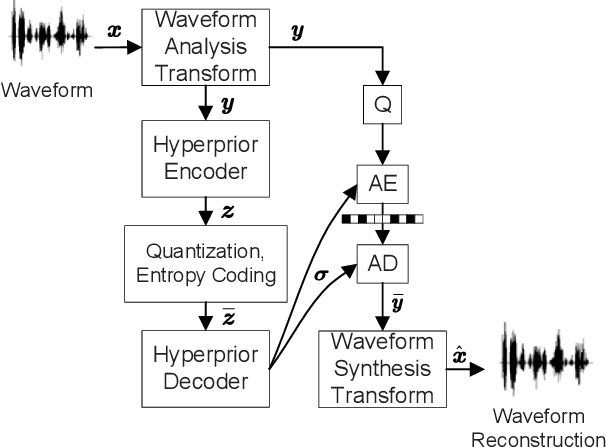
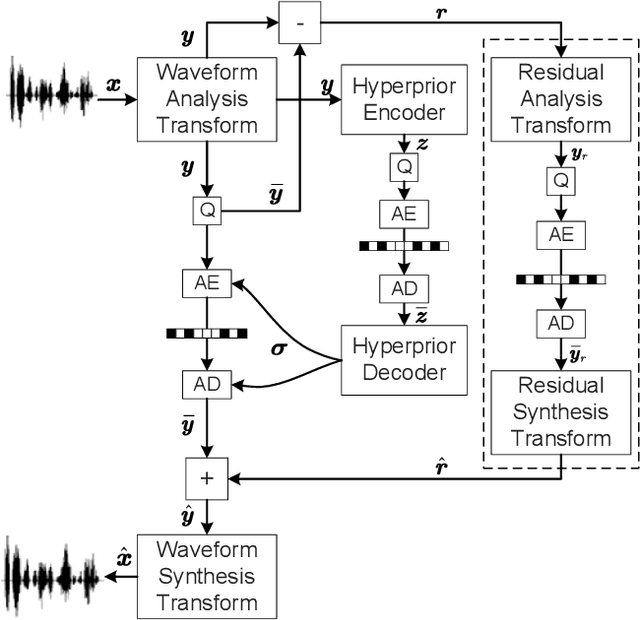
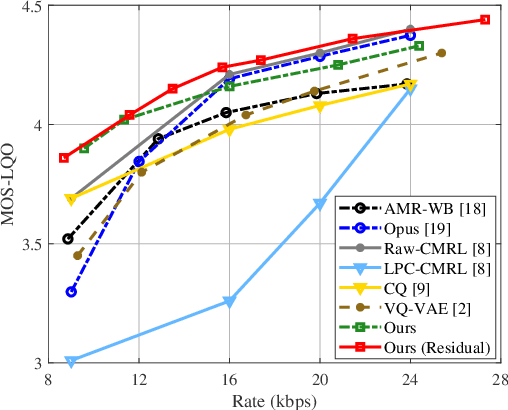
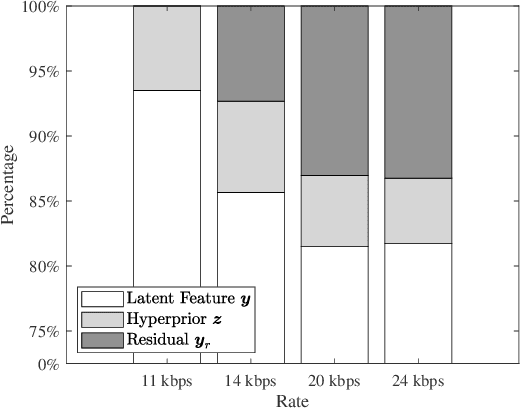
We propose a novel neural waveform compression method to catalyze emerging speech semantic communications. By introducing nonlinear transform and variational modeling, we effectively capture the dependencies within speech frames and estimate the probabilistic distribution of the speech feature more accurately, giving rise to better compression performance. In particular, the speech signals are analyzed and synthesized by a pair of nonlinear transforms, yielding latent features. An entropy model with hyperprior is built to capture the probabilistic distribution of latent features, followed with quantization and entropy coding. The proposed waveform codec can be optimized flexibly towards arbitrary rate, and the other appealing feature is that it can be easily optimized for any differentiable loss function, including perceptual loss used in semantic communications. To further improve the fidelity, we incorporate residual coding to mitigate the degradation arising from quantization distortion at the latent space. Results indicate that achieving the same performance, the proposed method saves up to 27% coding rate than widely used adaptive multi-rate wideband (AMR-WB) codec as well as emerging neural waveform coding methods.
Wireless Deep Speech Semantic Transmission
Nov 04, 2022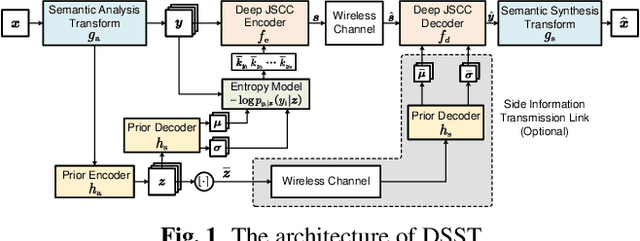
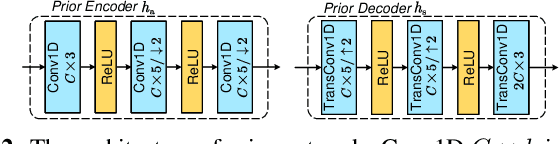
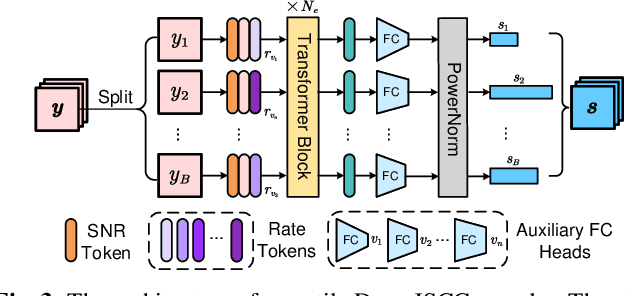
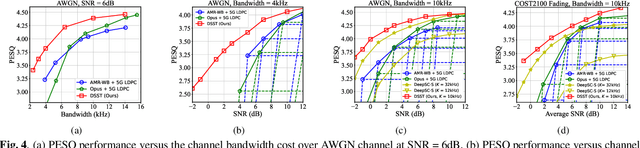
In this paper, we propose a new class of high-efficiency semantic coded transmission methods for end-to-end speech transmission over wireless channels. We name the whole system as deep speech semantic transmission (DSST). Specifically, we introduce a nonlinear transform to map the speech source to semantic latent space and feed semantic features into source-channel encoder to generate the channel-input sequence. Guided by the variational modeling idea, we build an entropy model on the latent space to estimate the importance diversity among semantic feature embeddings. Accordingly, these semantic features of different importance can be allocated with different coding rates reasonably, which maximizes the system coding gain. Furthermore, we introduce a channel signal-to-noise ratio (SNR) adaptation mechanism such that a single model can be applied over various channel states. The end-to-end optimization of our model leads to a flexible rate-distortion (RD) trade-off, supporting versatile wireless speech semantic transmission. Experimental results verify that our DSST system clearly outperforms current engineered speech transmission systems on both objective and subjective metrics. Compared with existing neural speech semantic transmission methods, our model saves up to 75% of channel bandwidth costs when achieving the same quality. An intuitive comparison of audio demos can be found at https://ximoo123.github.io/DSST.
Few-shot Object Detection with Self-adaptive Attention Network for Remote Sensing Images
Sep 26, 2020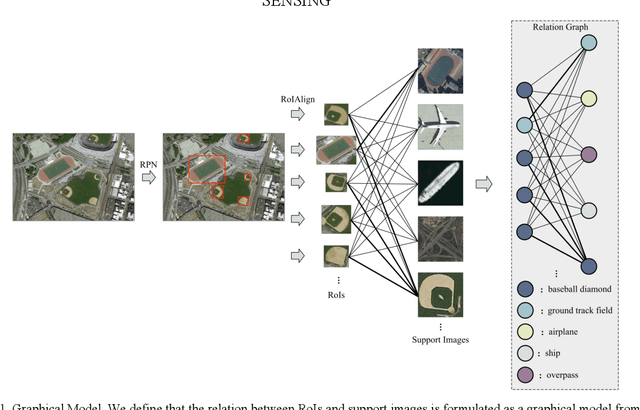
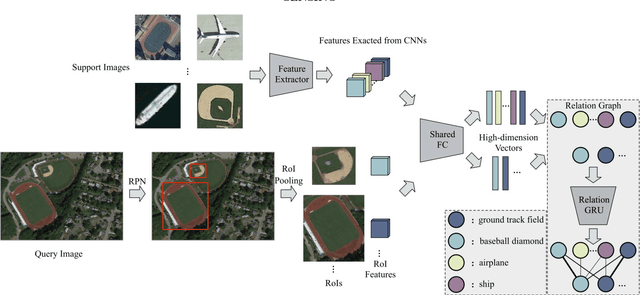
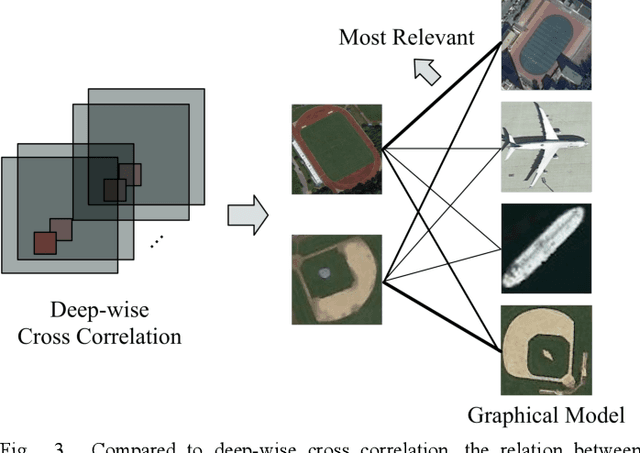
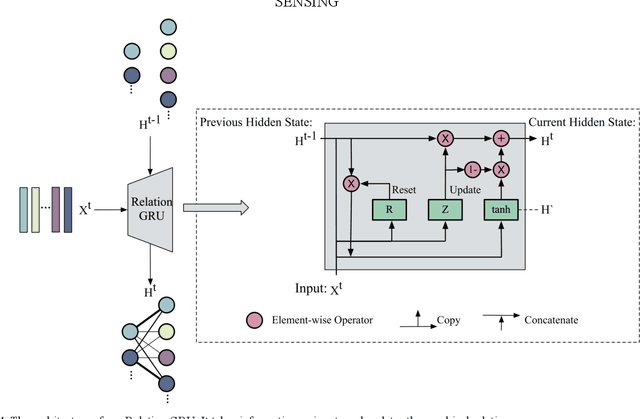
In remote sensing field, there are many applications of object detection in recent years, which demands a great number of labeled data. However, we may be faced with some cases where only limited data are available. In this paper, we proposed a few-shot object detector which is designed for detecting novel objects provided with only a few examples. Particularly, in order to fit the object detection settings, our proposed few-shot detector concentrates on the relations that lie in the level of objects instead of the full image with the assistance of Self-Adaptive Attention Network (SAAN). The SAAN can fully leverage the object-level relations through a relation GRU unit and simultaneously attach attention on object features in a self-adaptive way according to the object-level relations to avoid some situations where the additional attention is useless or even detrimental. Eventually, the detection results are produced from the features that are added with attention and thus are able to be detected simply. The experiments demonstrate the effectiveness of the proposed method in few-shot scenes.
Few-shot Object Detection with Feature Attention Highlight Module in Remote Sensing Images
Sep 03, 2020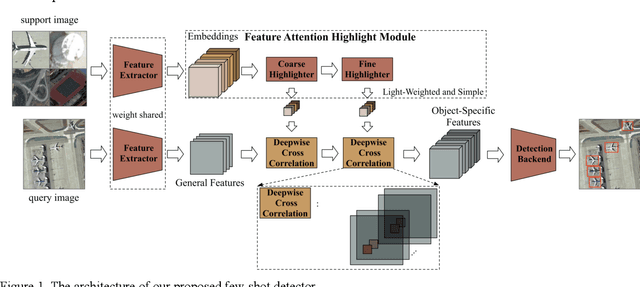
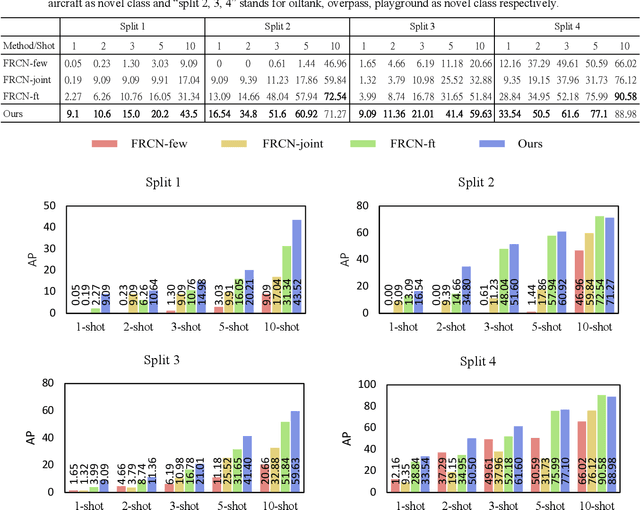
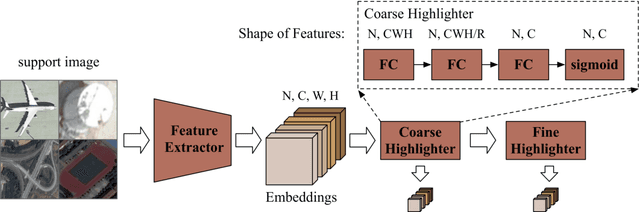
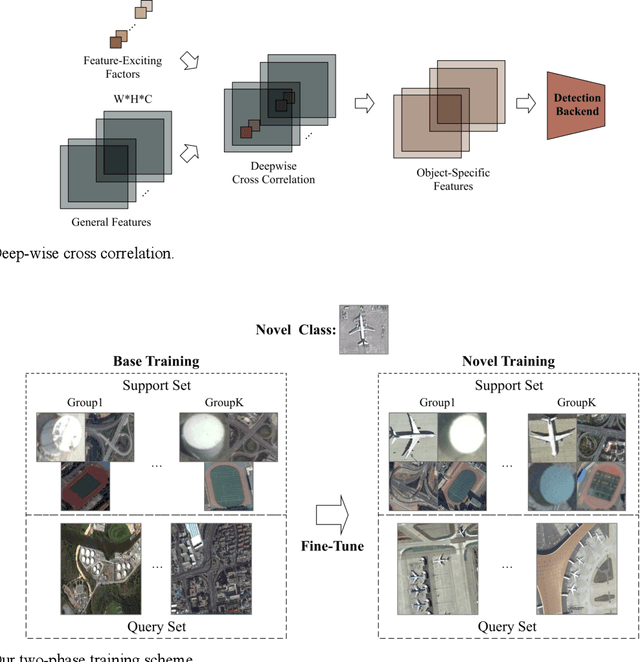
In recent years, there are many applications of object detection in remote sensing field, which demands a great number of labeled data. However, in many cases, data is extremely rare. In this paper, we proposed a few-shot object detector which is designed for detecting novel objects based on only a few examples. Through fully leveraging labeled base classes, our model that is composed of a feature-extractor, a feature attention highlight module as well as a two-stage detection backend can quickly adapt to novel classes. The pre-trained feature extractor whose parameters are shared produces general features. While the feature attention highlight module is designed to be light-weighted and simple in order to fit the few-shot cases. Although it is simple, the information provided by it in a serial way is helpful to make the general features to be specific for few-shot objects. Then the object-specific features are delivered to the two-stage detection backend for the detection results. The experiments demonstrate the effectiveness of the proposed method for few-shot cases.
A novel statistical metric learning for hyperspectral image classification
May 13, 2019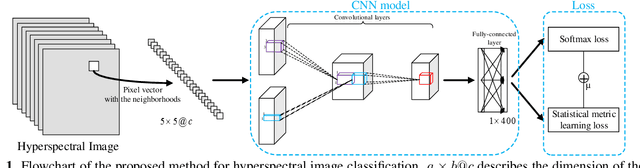
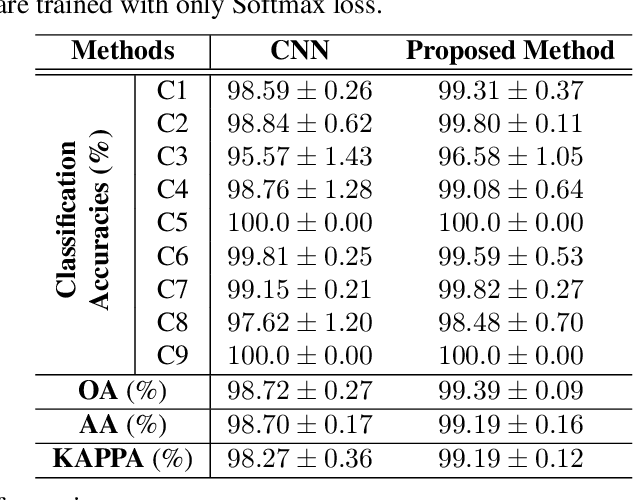

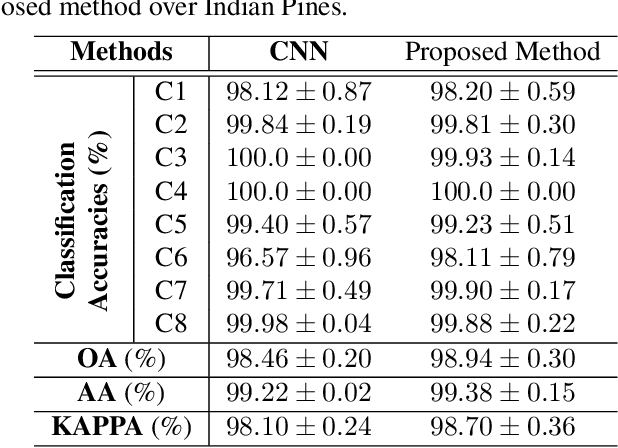
In this paper, a novel statistical metric learning is developed for spectral-spatial classification of the hyperspectral image. First, the standard variance of the samples of each class in each batch is used to decrease the intra-class variance within each class. Then, the distances between the means of different classes are used to penalize the inter-class variance of the training samples. Finally, the standard variance between the means of different classes is added as an additional diversity term to repulse different classes from each other. Experiments have conducted over two real-world hyperspectral image datasets and the experimental results have shown the effectiveness of the proposed statistical metric learning.