 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCopilotCAD: Empowering Radiologists with Report Completion Models and Quantitative Evidence from Medical Image Foundation Models
Apr 11, 2024



Computer-aided diagnosis systems hold great promise to aid radiologists and clinicians in radiological clinical practice and enhance diagnostic accuracy and efficiency. However, the conventional systems primarily focus on delivering diagnostic results through text report generation or medical image classification, positioning them as standalone decision-makers rather than helpers and ignoring radiologists' expertise. This study introduces an innovative paradigm to create an assistive co-pilot system for empowering radiologists by leveraging Large Language Models (LLMs) and medical image analysis tools. Specifically, we develop a collaborative framework to integrate LLMs and quantitative medical image analysis results generated by foundation models with radiologists in the loop, achieving efficient and safe generation of radiology reports and effective utilization of computational power of AI and the expertise of medical professionals. This approach empowers radiologists to generate more precise and detailed diagnostic reports, enhancing patient outcomes while reducing the burnout of clinicians. Our methodology underscores the potential of AI as a supportive tool in medical diagnostics, promoting a harmonious integration of technology and human expertise to advance the field of radiology.
ECPC-IDS:A benchmark endometrail cancer PET/CT image dataset for evaluation of semantic segmentation and detection of hypermetabolic regions
Sep 02, 2023



Endometrial cancer is one of the most common tumors in the female reproductive system and is the third most common gynecological malignancy that causes death after ovarian and cervical cancer. Early diagnosis can significantly improve the 5-year survival rate of patients. With the development of artificial intelligence, computer-assisted diagnosis plays an increasingly important role in improving the accuracy and objectivity of diagnosis, as well as reducing the workload of doctors. However, the absence of publicly available endometrial cancer image datasets restricts the application of computer-assisted diagnostic techniques.In this paper, a publicly available Endometrial Cancer PET/CT Image Dataset for Evaluation of Semantic Segmentation and Detection of Hypermetabolic Regions (ECPC-IDS) are published. Specifically, the segmentation section includes PET and CT images, with a total of 7159 images in multiple formats. In order to prove the effectiveness of segmentation methods on ECPC-IDS, five classical deep learning semantic segmentation methods are selected to test the image segmentation task. The object detection section also includes PET and CT images, with a total of 3579 images and XML files with annotation information. Six deep learning methods are selected for experiments on the detection task.This study conduct extensive experiments using deep learning-based semantic segmentation and object detection methods to demonstrate the differences between various methods on ECPC-IDS. As far as we know, this is the first publicly available dataset of endometrial cancer with a large number of multiple images, including a large amount of information required for image and target detection. ECPC-IDS can aid researchers in exploring new algorithms to enhance computer-assisted technology, benefiting both clinical doctors and patients greatly.
PHE-SICH-CT-IDS: A Benchmark CT Image Dataset for Evaluation Semantic Segmentation, Object Detection and Radiomic Feature Extraction of Perihematomal Edema in Spontaneous Intracerebral Hemorrhage
Aug 21, 2023Intracerebral hemorrhage is one of the diseases with the highest mortality and poorest prognosis worldwide. Spontaneous intracerebral hemorrhage (SICH) typically presents acutely, prompt and expedited radiological examination is crucial for diagnosis, localization, and quantification of the hemorrhage. Early detection and accurate segmentation of perihematomal edema (PHE) play a critical role in guiding appropriate clinical intervention and enhancing patient prognosis. However, the progress and assessment of computer-aided diagnostic methods for PHE segmentation and detection face challenges due to the scarcity of publicly accessible brain CT image datasets. This study establishes a publicly available CT dataset named PHE-SICH-CT-IDS for perihematomal edema in spontaneous intracerebral hemorrhage. The dataset comprises 120 brain CT scans and 7,022 CT images, along with corresponding medical information of the patients. To demonstrate its effectiveness, classical algorithms for semantic segmentation, object detection, and radiomic feature extraction are evaluated. The experimental results confirm the suitability of PHE-SICH-CT-IDS for assessing the performance of segmentation, detection and radiomic feature extraction methods. To the best of our knowledge, this is the first publicly available dataset for PHE in SICH, comprising various data formats suitable for applications across diverse medical scenarios. We believe that PHE-SICH-CT-IDS will allure researchers to explore novel algorithms, providing valuable support for clinicians and patients in the clinical setting. PHE-SICH-CT-IDS is freely published for non-commercial purpose at: https://figshare.com/articles/dataset/PHE-SICH-CT-IDS/23957937.
AATCT-IDS: A Benchmark Abdominal Adipose Tissue CT Image Dataset for Image Denoising, Semantic Segmentation, and Radiomics Evaluation
Aug 16, 2023Methods: In this study, a benchmark \emph{Abdominal Adipose Tissue CT Image Dataset} (AATTCT-IDS) containing 300 subjects is prepared and published. AATTCT-IDS publics 13,732 raw CT slices, and the researchers individually annotate the subcutaneous and visceral adipose tissue regions of 3,213 of those slices that have the same slice distance to validate denoising methods, train semantic segmentation models, and study radiomics. For different tasks, this paper compares and analyzes the performance of various methods on AATTCT-IDS by combining the visualization results and evaluation data. Thus, verify the research potential of this data set in the above three types of tasks. Results: In the comparative study of image denoising, algorithms using a smoothing strategy suppress mixed noise at the expense of image details and obtain better evaluation data. Methods such as BM3D preserve the original image structure better, although the evaluation data are slightly lower. The results show significant differences among them. In the comparative study of semantic segmentation of abdominal adipose tissue, the segmentation results of adipose tissue by each model show different structural characteristics. Among them, BiSeNet obtains segmentation results only slightly inferior to U-Net with the shortest training time and effectively separates small and isolated adipose tissue. In addition, the radiomics study based on AATTCT-IDS reveals three adipose distributions in the subject population. Conclusion: AATTCT-IDS contains the ground truth of adipose tissue regions in abdominal CT slices. This open-source dataset can attract researchers to explore the multi-dimensional characteristics of abdominal adipose tissue and thus help physicians and patients in clinical practice. AATCT-IDS is freely published for non-commercial purpose at: \url{https://figshare.com/articles/dataset/AATTCT-IDS/23807256}.
Form 10-Q Itemization
Apr 23, 2021


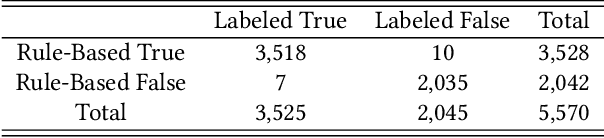
Form 10-Q, the quarterly financial statement, is one of the most crucial filings for US public firms to disclose their financial and other relevant business operation information. Due to the gigantic number of 10-Q filings prevailing in the market for each quarter and diverse variations in the implementation of format given company-specific nature, it has long been a problem in the field to provide a generalized way to dissect and retrieve the itemized information. In this paper, we create a tool to itemize 10-Q filings using multi-stage processes, blending a rule-based algorithm with a CNN deep learning model. The implementation is an integrated pipeline which provides a solution to the item retrieval on a large scale. This would enable cross sectional and longitudinal textual analysis on massive number of companies.
Adaptive convolutional neural networks for k-space data interpolation in fast magnetic resonance imaging
Jun 09, 2020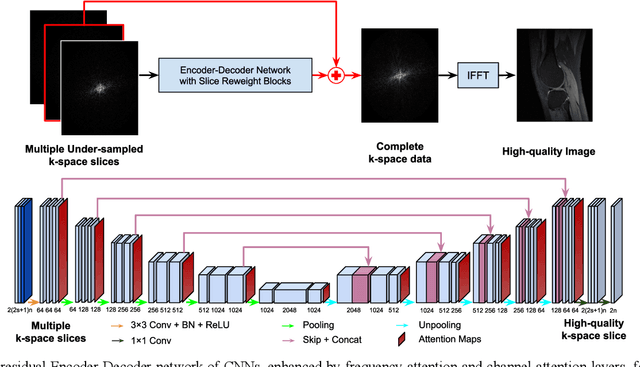
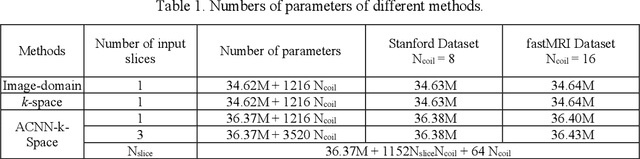
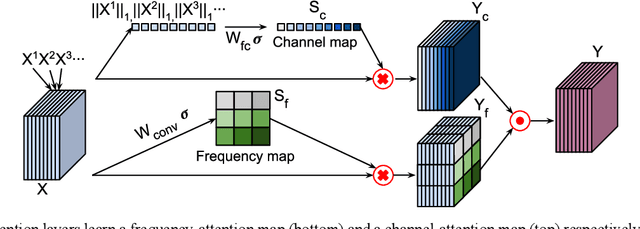
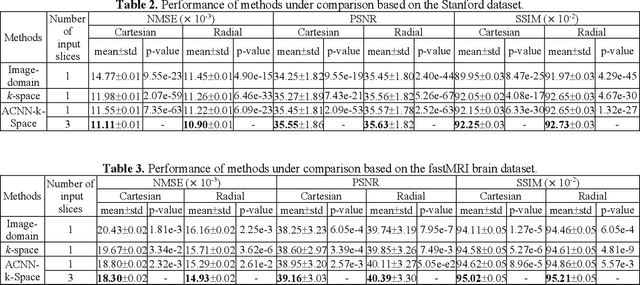
Deep learning in k-space has demonstrated great potential for image reconstruction from undersampled k-space data in fast magnetic resonance imaging (MRI). However, existing deep learning-based image reconstruction methods typically apply weight-sharing convolutional neural networks (CNNs) to k-space data without taking into consideration the k-space data's spatial frequency properties, leading to ineffective learning of the image reconstruction models. Moreover, complementary information of spatially adjacent slices is often ignored in existing deep learning methods. To overcome such limitations, we develop a deep learning algorithm, referred to as adaptive convolutional neural networks for k-space data interpolation (ACNN-k-Space), which adopts a residual Encoder-Decoder network architecture to interpolate the undersampled k-space data by integrating spatially contiguous slices as multi-channel input, along with k-space data from multiple coils if available. The network is enhanced by self-attention layers to adaptively focus on k-space data at different spatial frequencies and channels. We have evaluated our method on two public datasets and compared it with state-of-the-art existing methods. Ablation studies and experimental results demonstrate that our method effectively reconstructs images from undersampled k-space data and achieves significantly better image reconstruction performance than current state-of-the-art techniques.
Deep Learning over Multi-field Categorical Data: A Case Study on User Response Prediction
Jan 11, 2016


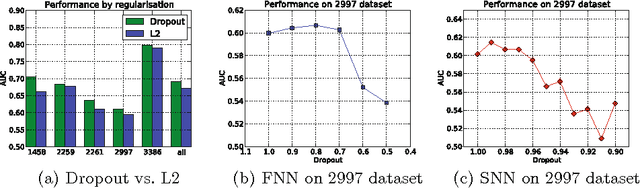
Predicting user responses, such as click-through rate and conversion rate, are critical in many web applications including web search, personalised recommendation, and online advertising. Different from continuous raw features that we usually found in the image and audio domains, the input features in web space are always of multi-field and are mostly discrete and categorical while their dependencies are little known. Major user response prediction models have to either limit themselves to linear models or require manually building up high-order combination features. The former loses the ability of exploring feature interactions, while the latter results in a heavy computation in the large feature space. To tackle the issue, we propose two novel models using deep neural networks (DNNs) to automatically learn effective patterns from categorical feature interactions and make predictions of users' ad clicks. To get our DNNs efficiently work, we propose to leverage three feature transformation methods, i.e., factorisation machines (FMs), restricted Boltzmann machines (RBMs) and denoising auto-encoders (DAEs). This paper presents the structure of our models and their efficient training algorithms. The large-scale experiments with real-world data demonstrate that our methods work better than major state-of-the-art models.