 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelfOccFlow: Towards end-to-end self-supervised 3D Occupancy Flow prediction
Feb 27, 2026Estimating 3D occupancy and motion at the vehicle's surroundings is essential for autonomous driving, enabling situational awareness in dynamic environments. Existing approaches jointly learn geometry and motion but rely on expensive 3D occupancy and flow annotations, velocity labels from bounding boxes, or pretrained optical flow models. We propose a self-supervised method for 3D occupancy flow estimation that eliminates the need for human-produced annotations or external flow supervision. Our method disentangles the scene into separate static and dynamic signed distance fields and learns motion implicitly through temporal aggregation. Additionally, we introduce a strong self-supervised flow cue derived from features' cosine similarities. We demonstrate the efficacy of our 3D occupancy flow method on SemanticKITTI, KITTI-MOT, and nuScenes.
* Accepted version. Final version is published in IEEE Robotics and Automation Letters, DOI: 10.1109/LRA.2026.3665447
Multi-modal NeRF Self-Supervision for LiDAR Semantic Segmentation
Nov 05, 2024
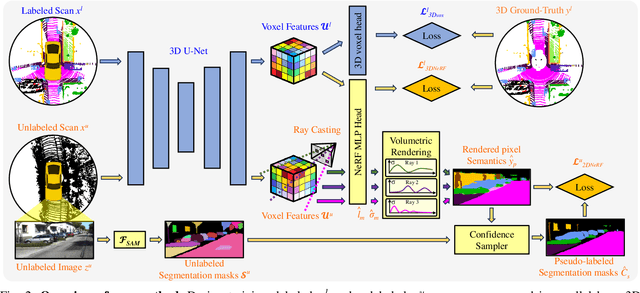
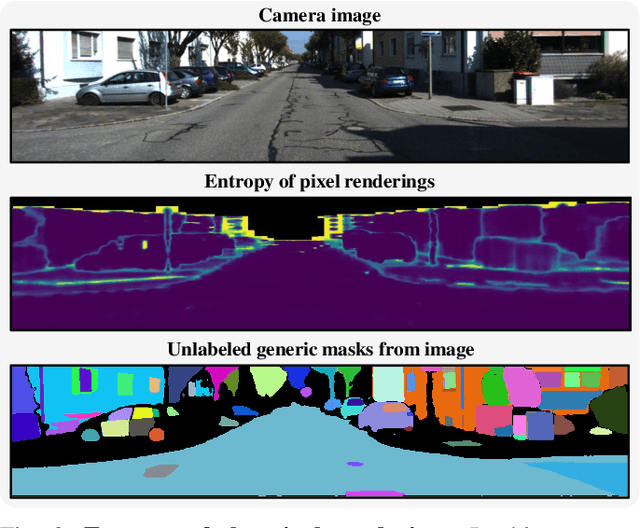

LiDAR Semantic Segmentation is a fundamental task in autonomous driving perception consisting of associating each LiDAR point to a semantic label. Fully-supervised models have widely tackled this task, but they require labels for each scan, which either limits their domain or requires impractical amounts of expensive annotations. Camera images, which are generally recorded alongside LiDAR pointclouds, can be processed by the widely available 2D foundation models, which are generic and dataset-agnostic. However, distilling knowledge from 2D data to improve LiDAR perception raises domain adaptation challenges. For example, the classical perspective projection suffers from the parallax effect produced by the position shift between both sensors at their respective capture times. We propose a Semi-Supervised Learning setup to leverage unlabeled LiDAR pointclouds alongside distilled knowledge from the camera images. To self-supervise our model on the unlabeled scans, we add an auxiliary NeRF head and cast rays from the camera viewpoint over the unlabeled voxel features. The NeRF head predicts densities and semantic logits at each sampled ray location which are used for rendering pixel semantics. Concurrently, we query the Segment-Anything (SAM) foundation model with the camera image to generate a set of unlabeled generic masks. We fuse the masks with the rendered pixel semantics from LiDAR to produce pseudo-labels that supervise the pixel predictions. During inference, we drop the NeRF head and run our model with only LiDAR. We show the effectiveness of our approach in three public LiDAR Semantic Segmentation benchmarks: nuScenes, SemanticKITTI and ScribbleKITTI.
Deep Sensor Fusion with Pyramid Fusion Networks for 3D Semantic Segmentation
May 26, 2022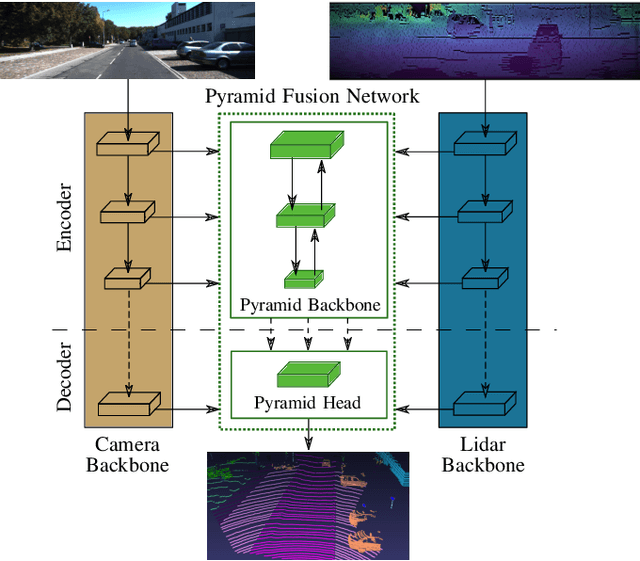

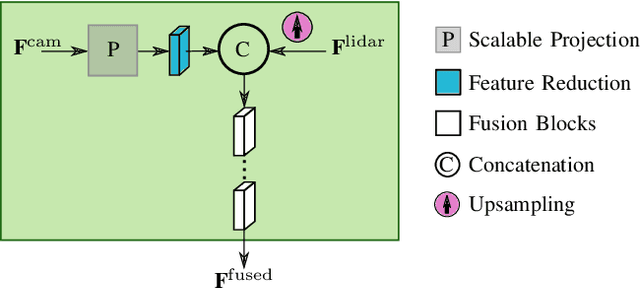
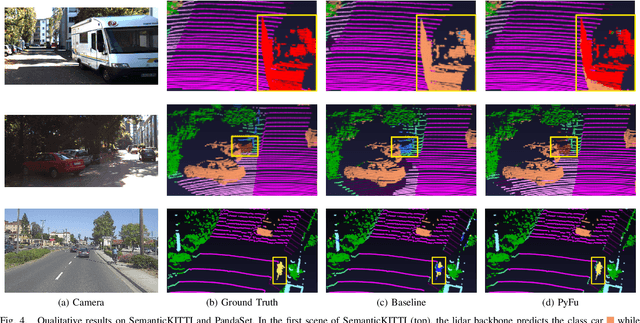
Robust environment perception for autonomous vehicles is a tremendous challenge, which makes a diverse sensor set with e.g. camera, lidar and radar crucial. In the process of understanding the recorded sensor data, 3D semantic segmentation plays an important role. Therefore, this work presents a pyramid-based deep fusion architecture for lidar and camera to improve 3D semantic segmentation of traffic scenes. Individual sensor backbones extract feature maps of camera images and lidar point clouds. A novel Pyramid Fusion Backbone fuses these feature maps at different scales and combines the multimodal features in a feature pyramid to compute valuable multimodal, multi-scale features. The Pyramid Fusion Head aggregates these pyramid features and further refines them in a late fusion step, incorporating the final features of the sensor backbones. The approach is evaluated on two challenging outdoor datasets and different fusion strategies and setups are investigated. It outperforms recent range view based lidar approaches as well as all so far proposed fusion strategies and architectures.
LiDAR-based Recurrent 3D Semantic Segmentation with Temporal Memory Alignment
Mar 03, 2021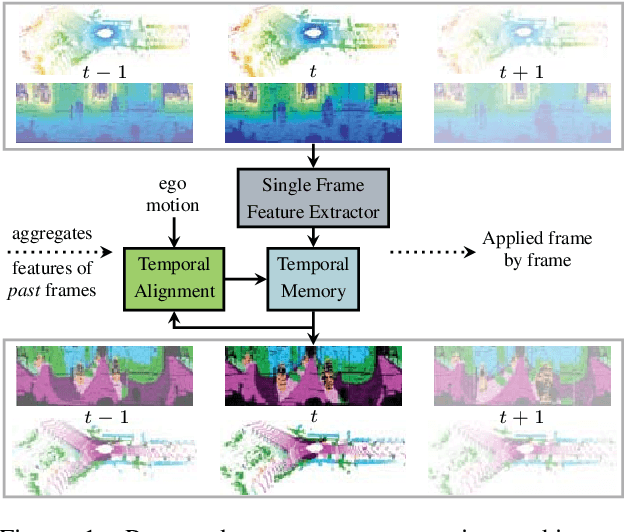
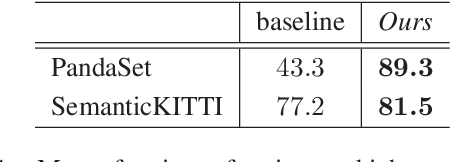
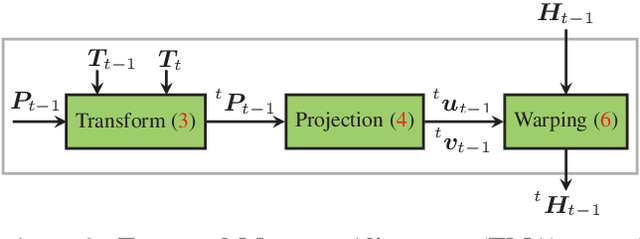
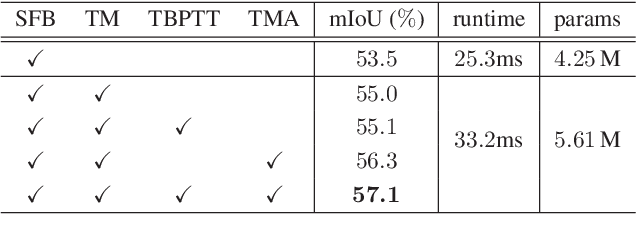
Understanding and interpreting a 3d environment is a key challenge for autonomous vehicles. Semantic segmentation of 3d point clouds combines 3d information with semantics and thereby provides a valuable contribution to this task. In many real-world applications, point clouds are generated by lidar sensors in a consecutive fashion. Working with a time series instead of single and independent frames enables the exploitation of temporal information. We therefore propose a recurrent segmentation architecture (RNN), which takes a single range image frame as input and exploits recursively aggregated temporal information. An alignment strategy, which we call Temporal Memory Alignment, uses ego motion to temporally align the memory between consecutive frames in feature space. A Residual Network and ConvGRU are investigated for the memory update. We demonstrate the benefits of the presented approach on two large-scale datasets and compare it to several stateof-the-art methods. Our approach ranks first on the SemanticKITTI multiple scan benchmark and achieves state-of-the-art performance on the single scan benchmark. In addition, the evaluation shows that the exploitation of temporal information significantly improves segmentation results compared to a single frame approach.