 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal NeRF Self-Supervision for LiDAR Semantic Segmentation
Nov 05, 2024
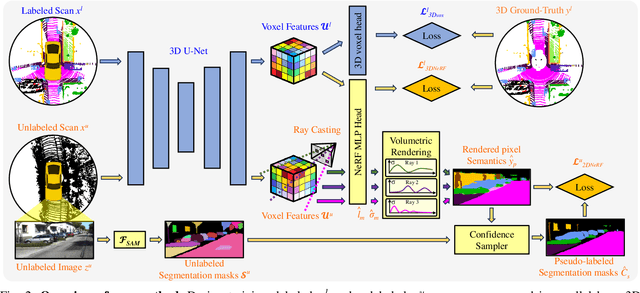
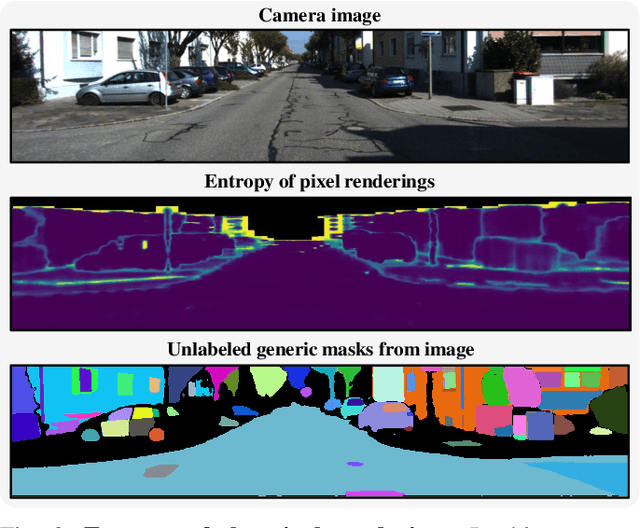

LiDAR Semantic Segmentation is a fundamental task in autonomous driving perception consisting of associating each LiDAR point to a semantic label. Fully-supervised models have widely tackled this task, but they require labels for each scan, which either limits their domain or requires impractical amounts of expensive annotations. Camera images, which are generally recorded alongside LiDAR pointclouds, can be processed by the widely available 2D foundation models, which are generic and dataset-agnostic. However, distilling knowledge from 2D data to improve LiDAR perception raises domain adaptation challenges. For example, the classical perspective projection suffers from the parallax effect produced by the position shift between both sensors at their respective capture times. We propose a Semi-Supervised Learning setup to leverage unlabeled LiDAR pointclouds alongside distilled knowledge from the camera images. To self-supervise our model on the unlabeled scans, we add an auxiliary NeRF head and cast rays from the camera viewpoint over the unlabeled voxel features. The NeRF head predicts densities and semantic logits at each sampled ray location which are used for rendering pixel semantics. Concurrently, we query the Segment-Anything (SAM) foundation model with the camera image to generate a set of unlabeled generic masks. We fuse the masks with the rendered pixel semantics from LiDAR to produce pseudo-labels that supervise the pixel predictions. During inference, we drop the NeRF head and run our model with only LiDAR. We show the effectiveness of our approach in three public LiDAR Semantic Segmentation benchmarks: nuScenes, SemanticKITTI and ScribbleKITTI.
Neural Semantic Map-Learning for Autonomous Vehicles
Oct 10, 2024


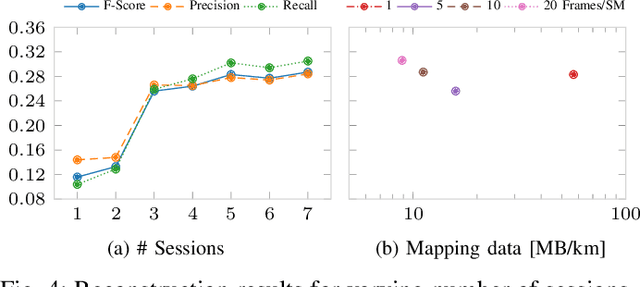
Autonomous vehicles demand detailed maps to maneuver reliably through traffic, which need to be kept up-to-date to ensure a safe operation. A promising way to adapt the maps to the ever-changing road-network is to use crowd-sourced data from a fleet of vehicles. In this work, we present a mapping system that fuses local submaps gathered from a fleet of vehicles at a central instance to produce a coherent map of the road environment including drivable area, lane markings, poles, obstacles and more as a 3D mesh. Each vehicle contributes locally reconstructed submaps as lightweight meshes, making our method applicable to a wide range of reconstruction methods and sensor modalities. Our method jointly aligns and merges the noisy and incomplete local submaps using a scene-specific Neural Signed Distance Field, which is supervised using the submap meshes to predict a fused environment representation. We leverage memory-efficient sparse feature-grids to scale to large areas and introduce a confidence score to model uncertainty in scene reconstruction. Our approach is evaluated on two datasets with different local mapping methods, showing improved pose alignment and reconstruction over existing methods. Additionally, we demonstrate the benefit of multi-session mapping and examine the required amount of data to enable high-fidelity map learning for autonomous vehicles.
Semantic Image Alignment for Vehicle Localization
Oct 08, 2021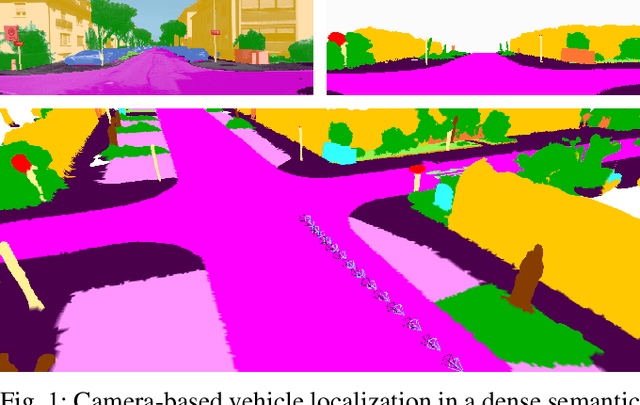
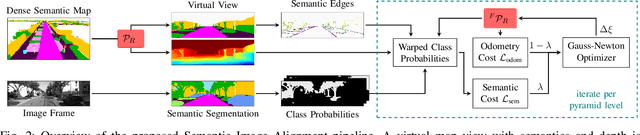
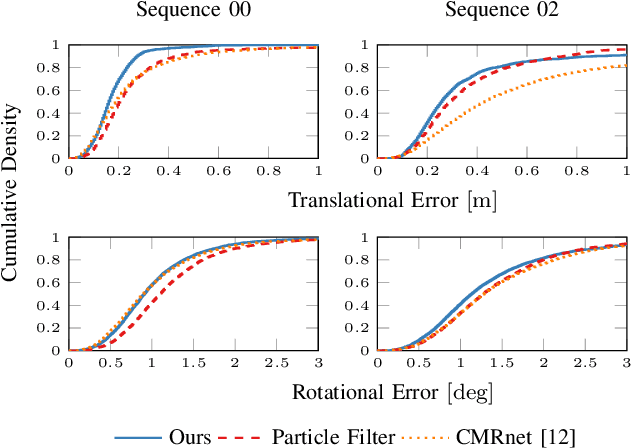
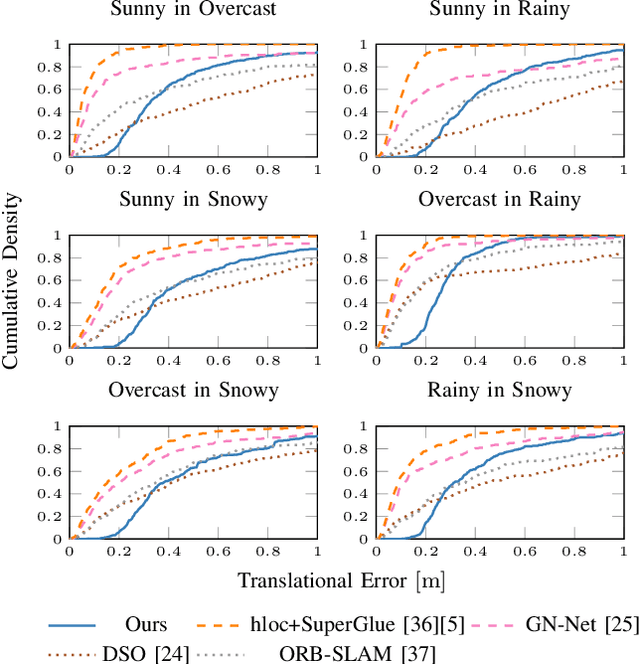
Accurate and reliable localization is a fundamental requirement for autonomous vehicles to use map information in higher-level tasks such as navigation or planning. In this paper, we present a novel approach to vehicle localization in dense semantic maps, including vectorized high-definition maps or 3D meshes, using semantic segmentation from a monocular camera. We formulate the localization task as a direct image alignment problem on semantic images, which allows our approach to robustly track the vehicle pose in semantically labeled maps by aligning virtual camera views rendered from the map to sequences of semantically segmented camera images. In contrast to existing visual localization approaches, the system does not require additional keypoint features, handcrafted localization landmark extractors or expensive LiDAR sensors. We demonstrate the wide applicability of our method on a diverse set of semantic mesh maps generated from stereo or LiDAR as well as manually annotated HD maps and show that it achieves reliable and accurate localization in real-time.