 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-task GANs for Semantic Segmentation and Depth Completion with Cycle Consistency
Nov 29, 2020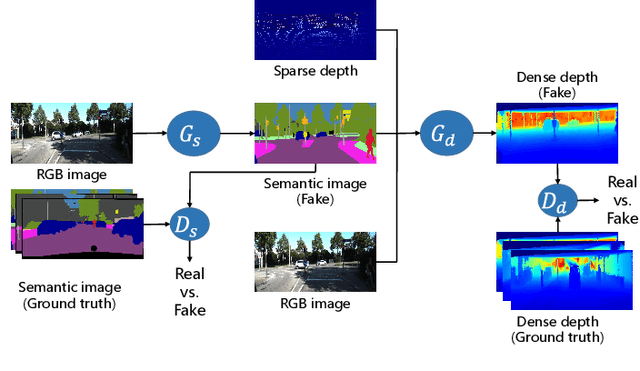
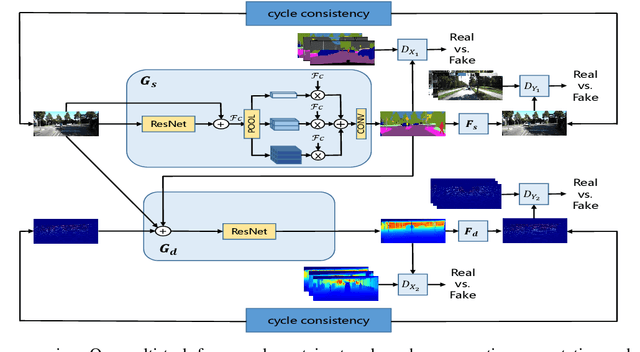


Semantic segmentation and depth completion are two challenging tasks in scene understanding, and they are widely used in robotics and autonomous driving. Although several works are proposed to jointly train these two tasks using some small modifications, like changing the last layer, the result of one task is not utilized to improve the performance of the other one despite that there are some similarities between these two tasks. In this paper, we propose multi-task generative adversarial networks (Multi-task GANs), which are not only competent in semantic segmentation and depth completion, but also improve the accuracy of depth completion through generated semantic images. In addition, we improve the details of generated semantic images based on CycleGAN by introducing multi-scale spatial pooling blocks and the structural similarity reconstruction loss. Furthermore, considering the inner consistency between semantic and geometric structures, we develop a semantic-guided smoothness loss to improve depth completion results. Extensive experiments on Cityscapes dataset and KITTI depth completion benchmark show that the Multi-task GANs are capable of achieving competitive performance for both semantic segmentation and depth completion tasks.
When Autonomous Systems Meet Accuracy and Transferability through AI: A Survey
Apr 30, 2020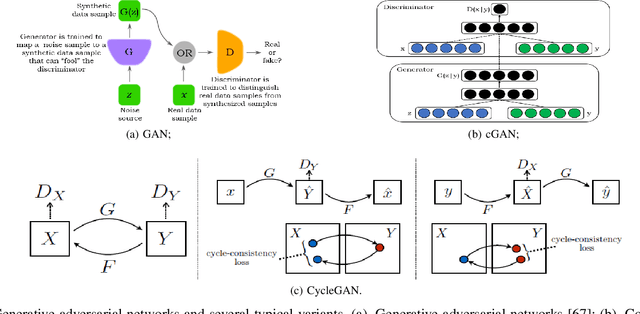
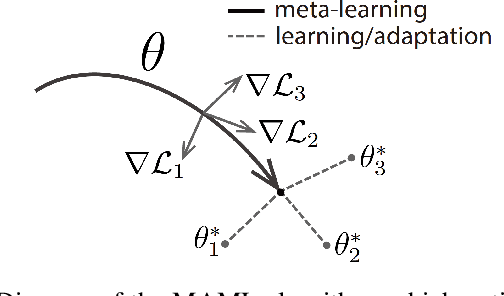


With widespread applications of artificial intelligence (AI), the capabilities of the perception, understanding, decision-making and control for autonomous systems have improved significantly in the past years. When autonomous systems consider the performance of accuracy and transferability, several AI methods, like adversarial learning, reinforcement learning (RL) and meta-learning, show their powerful performance. Here, we review the learning-based approaches in autonomous systems from the perspectives of accuracy and transferability. Accuracy means that a well-trained model shows good results during the testing phase, in which the testing set shares a same task or a data distribution with the training set. Transferability means that when a well-trained model is transferred to other testing domains, the accuracy is still good. Firstly, we introduce some basic concepts of transfer learning and then present some preliminaries of adversarial learning, RL and meta-learning. Secondly, we focus on reviewing the accuracy or transferability or both of them to show the advantages of adversarial learning, like generative adversarial networks (GANs), in typical computer vision tasks in autonomous systems, including image style transfer, image superresolution, image deblurring/dehazing/rain removal, semantic segmentation, depth estimation, pedestrian detection and person re-identification (re-ID). Then, we further review the performance of RL and meta-learning from the aspects of accuracy or transferability or both of them in autonomous systems, involving pedestrian tracking, robot navigation and robotic manipulation. Finally, we discuss several challenges and future topics for using adversarial learning, RL and meta-learning in autonomous systems.
Masked GANs for Unsupervised Depth and Pose Prediction with Scale Consistency
Apr 09, 2020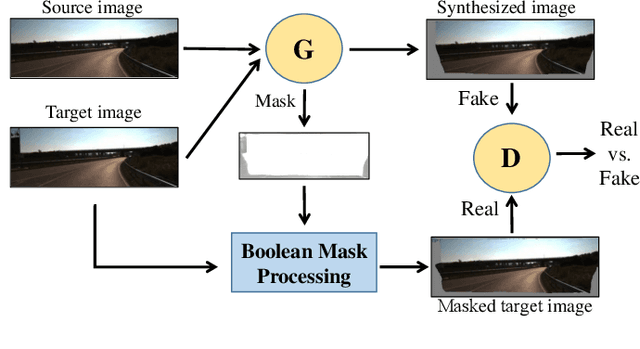

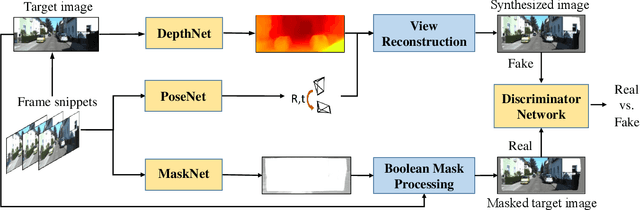

Previous works have shown that adversarial learning can be used for unsupervised monocular depth and visual odometry (VO) estimation. However, the performance of pose and depth networks is limited by occlusions and visual field changes. Because of the incomplete correspondence of visual information between frames caused by motion, target images cannot be synthesized completely from source images via view reconstruction and bilinear interpolation. The reconstruction loss based on the difference between synthesized and real target images will be affected by the incomplete reconstruction. Besides, the data distribution of unreconstructed regions will be learned and help the discriminator distinguish between real and fake images, thereby causing the case that the generator may fail to compete with the discriminator. Therefore, a MaskNet is designed in this paper to predict these regions and reduce their impacts on the reconstruction loss and adversarial loss. The impact of unreconstructed regions on discriminator is tackled by proposing a boolean mask scheme, as shown in Fig. 1. Furthermore, we consider the scale consistency of our pose network by utilizing a new scale-consistency loss, therefore our pose network is capable of providing the full camera trajectory over the long monocular sequence. Extensive experiments on KITTI dataset show that each component proposed in this paper contributes to the performance, and both of our depth and trajectory prediction achieve competitive performance.
Monocular Depth Estimation Based On Deep Learning: An Overview
Mar 14, 2020
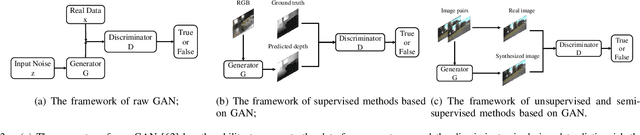
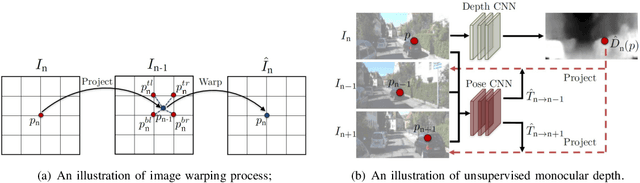
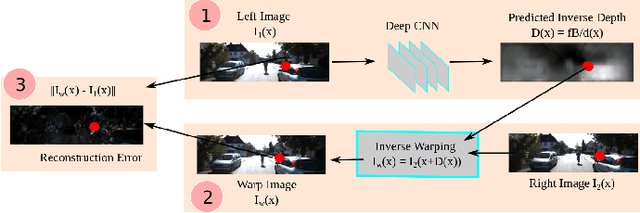
Depth information is important for autonomous systems to perceive environments and estimate their own state. Traditional depth estimation methods, like structure from motion and stereo vision matching, are built on feature correspondences of multiple viewpoints. Meanwhile, the predicted depth maps are sparse. Inferring depth information from a single image (monocular depth estimation) is an ill-posed problem. With the rapid development of deep neural networks, monocular depth estimation based on deep learning has been widely studied recently and achieved promising performance in accuracy. Meanwhile, dense depth maps are estimated from single images by deep neural networks in an end-to-end manner. In order to improve the accuracy of depth estimation, different kinds of network frameworks, loss functions and training strategies are proposed subsequently. Therefore, we survey the current monocular depth estimation methods based on deep learning in this review. Initially, we conclude several widely used datasets and evaluation indicators in deep learning-based depth estimation. Furthermore, we review some representative existing methods according to different training manners: supervised, unsupervised and semi-supervised. Finally, we discuss the challenges and provide some ideas for future researches in monocular depth estimation.
An Overview of Perception and Decision-Making in Autonomous Systems in the Era of Learning
Feb 24, 2020Autonomous systems possess the features of inferring their own ego-motion, autonomously understanding their surroundings, and planning trajectories. With the applications of deep learning and reinforcement learning, the perception and decision-making abilities of autonomous systems are being efficiently addressed, and many new learning-based algorithms have surfaced with respect to autonomous perception and decision-making. In this review, we focus on the applications of learning-based approaches in perception and decision-making in autonomous systems, which is different from previous reviews that discussed traditional methods. First, we delineate the existing classical simultaneous localization and mapping (SLAM) solutions and review the environmental perception and understanding methods based on deep learning, including deep learning-based monocular depth estimation, ego-motion prediction, image enhancement, object detection, semantic segmentation, and their combinations with traditional SLAM frameworks. Second, we briefly summarize the existing motion planning techniques, such as path planning and trajectory planning methods, and discuss the navigation methods based on reinforcement learning. Finally, we examine the several challenges and promising directions discussed and concluded in related research for future works in the era of computer science, automatic control, and robotics.