 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-task GANs for Semantic Segmentation and Depth Completion with Cycle Consistency
Paper and Code
Nov 29, 2020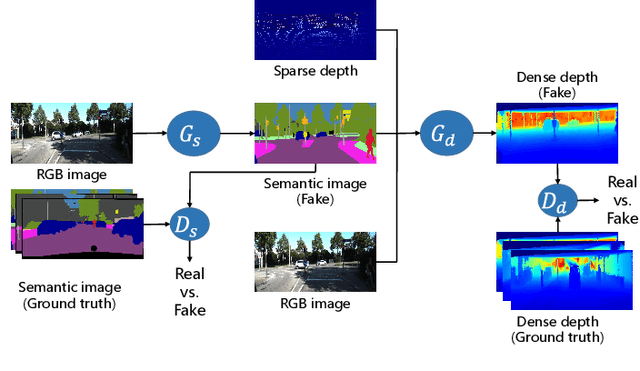
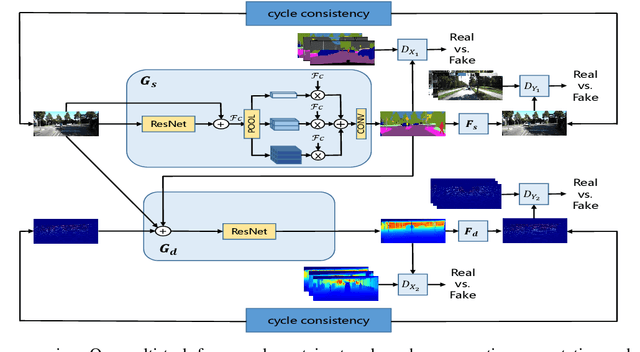


Semantic segmentation and depth completion are two challenging tasks in scene understanding, and they are widely used in robotics and autonomous driving. Although several works are proposed to jointly train these two tasks using some small modifications, like changing the last layer, the result of one task is not utilized to improve the performance of the other one despite that there are some similarities between these two tasks. In this paper, we propose multi-task generative adversarial networks (Multi-task GANs), which are not only competent in semantic segmentation and depth completion, but also improve the accuracy of depth completion through generated semantic images. In addition, we improve the details of generated semantic images based on CycleGAN by introducing multi-scale spatial pooling blocks and the structural similarity reconstruction loss. Furthermore, considering the inner consistency between semantic and geometric structures, we develop a semantic-guided smoothness loss to improve depth completion results. Extensive experiments on Cityscapes dataset and KITTI depth completion benchmark show that the Multi-task GANs are capable of achieving competitive performance for both semantic segmentation and depth completion tasks.