 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeaInfNet: Diagnosis in Medical Image with Feature-Driven Inference and Visual Explanations
Dec 04, 2023Interpretable deep learning models have received widespread attention in the field of image recognition. Due to the unique multi-instance learning of medical images and the difficulty in identifying decision-making regions, many interpretability models that have been proposed still have problems of insufficient accuracy and interpretability in medical image disease diagnosis. To solve these problems, we propose feature-driven inference network (FeaInfNet). Our first key innovation involves proposing a feature-based network reasoning structure, which is applied to FeaInfNet. The network of this structure compares the similarity of each sub-region image patch with the disease templates and normal templates that may appear in the region, and finally combines the comparison of each sub-region to make the final diagnosis. It simulates the diagnosis process of doctors to make the model interpretable in the reasoning process, while avoiding the misleading caused by the participation of normal areas in reasoning. Secondly, we propose local feature masks (LFM) to extract feature vectors in order to provide global information for these vectors, thus enhancing the expressive ability of the FeaInfNet. Finally, we propose adaptive dynamic masks (Adaptive-DM) to interpret feature vectors and prototypes into human-understandable image patches to provide accurate visual interpretation. We conducted qualitative and quantitative experiments on multiple publicly available medical datasets, including RSNA, iChallenge-PM, Covid-19, ChinaCXRSet, and MontgomerySet. The results of our experiments validate that our method achieves state-of-the-art performance in terms of classification accuracy and interpretability compared to baseline methods in medical image diagnosis. Additional ablation studies verify the effectiveness of each of our proposed components.
Variational Transformer: A Framework Beyond the Trade-off between Accuracy and Diversity for Image Captioning
May 28, 2022
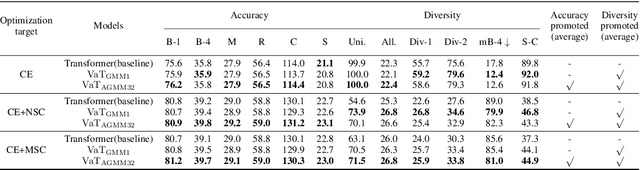

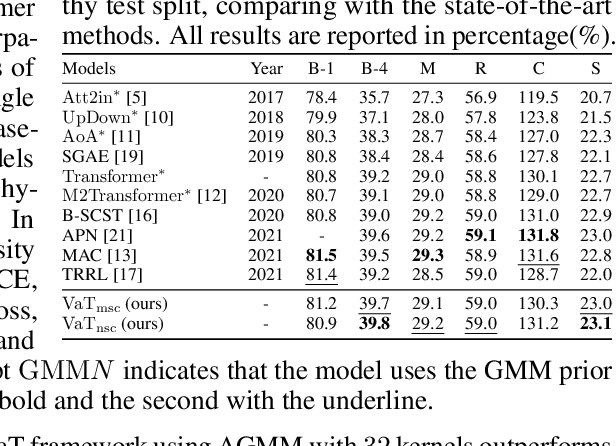
Accuracy and Diversity are two essential metrizable manifestations in generating natural and semantically correct captions. Many efforts have been made to enhance one of them with another decayed due to the trade-off gap. However, compromise does not make the progress. Decayed diversity makes the captioner a repeater, and decayed accuracy makes it a fake advisor. In this work, we exploit a novel Variational Transformer framework to improve accuracy and diversity simultaneously. To ensure accuracy, we introduce the "Invisible Information Prior" along with the "Auto-selectable GMM" to instruct the encoder to learn the precise language information and object relation in different scenes. To ensure diversity, we propose the "Range-Median Reward" baseline to retain more diverse candidates with higher rewards during the RL-based training process. Experiments show that our method achieves the simultaneous promotion of accuracy (CIDEr) and diversity (self-CIDEr), up to 1.1 and 4.8 percent, compared with the baseline. Also, our method outperforms others under the newly proposed measurement of the trade-off gap, with at least 3.55 percent promotion.
Adaptive Routing Between Capsules
Nov 19, 2019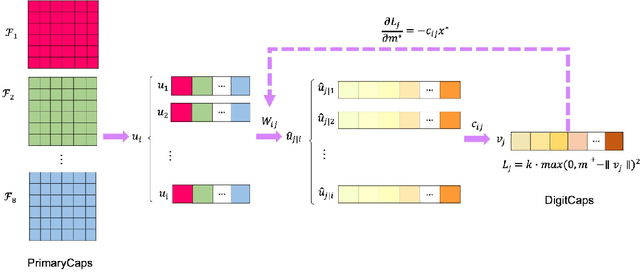

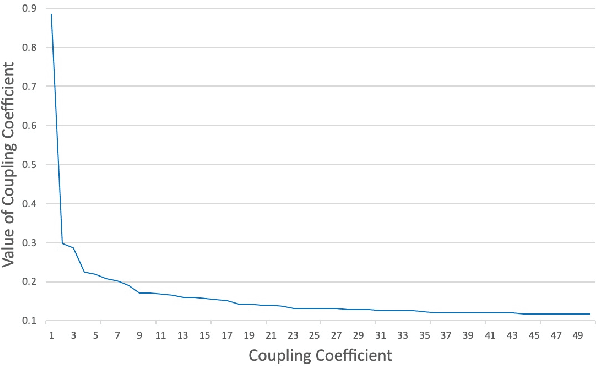
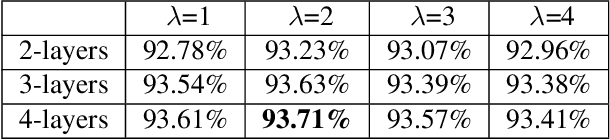
Capsule network is the most recent exciting advancement in the deep learning field and represents positional information by stacking features into vectors. The dynamic routing algorithm is used in the capsule network, however, there are some disadvantages such as the inability to stack multiple layers and a large amount of computation. In this paper, we propose an adaptive routing algorithm that can solve the problems mentioned above. First, the low-layer capsules adaptively adjust their direction and length in the routing algorithm and removing the influence of the coupling coefficient on the gradient propagation, so that the network can work when stacked in multiple layers. Then, the iterative process of routing is simplified to reduce the amount of computation and we introduce the gradient coefficient $\lambda$. Further, we tested the performance of our proposed adaptive routing algorithm on CIFAR10, Fashion-MNIST, SVHN and MNIST, while achieving better results than the dynamic routing algorithm.
Virtual Conditional Generative Adversarial Networks
Jan 25, 2019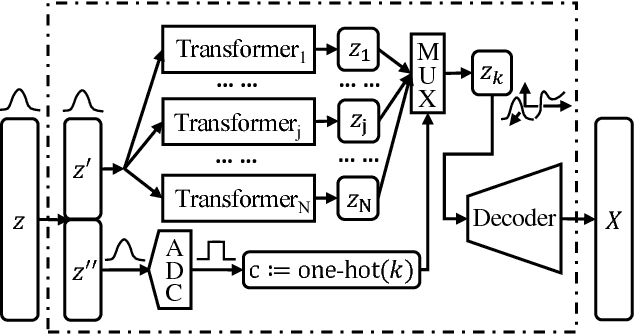
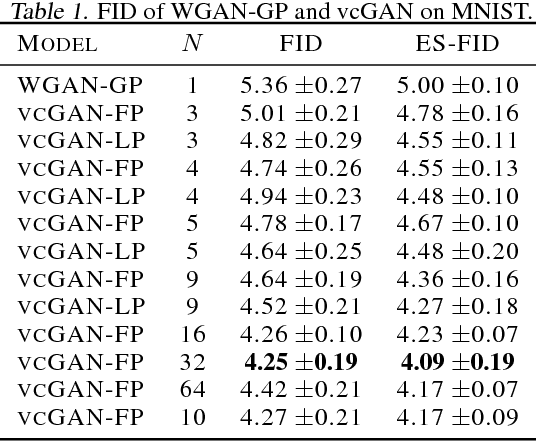

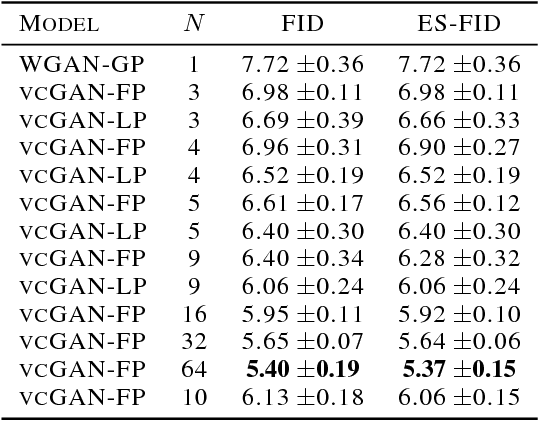
When trained on multimodal image datasets, normal Generative Adversarial Networks (GANs) are usually outperformed by class-conditional GANs and ensemble GANs, but conditional GANs is restricted to labeled datasets and ensemble GANs lack efficiency. We propose a novel GAN variant called virtual conditional GAN (vcGAN) which is not only an ensemble GAN with multiple generative paths while adding almost zero network parameters, but also a conditional GAN that can be trained on unlabeled datasets without explicit clustering steps or objectives other than the adversary loss. Inside the vcGAN's generator, a learnable ``analog-to-digital converter (ADC)" module maps a slice of the inputted multivariate Gaussian noise to discrete/digital noise (virtual label), according to which a selector selects the corresponding generative path to produce the sample. All the generative paths share the same decoder network while in each path the decoder network is fed with a concatenation of a different pre-computed amplified one-hot vector and the inputted Gaussian noise. We conducted a lot of experiments on several balanced/imbalanced image datasets to demonstrate that vcGAN converges faster and achieves improved Frech\'et Inception Distance (FID). In addition, we show the training byproduct that the ADC in vcGAN learned the categorical probability of each mode and that each generative path generates samples of specific mode, which enables class-conditional sampling. Codes are available at \url{https://github.com/annonnymmouss/vcgan}