 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Transformer: A Framework Beyond the Trade-off between Accuracy and Diversity for Image Captioning
Paper and Code

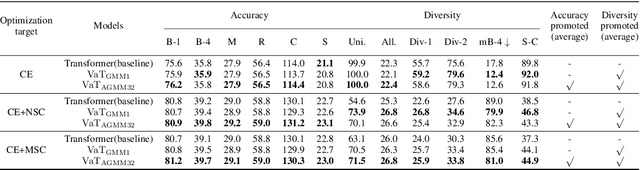

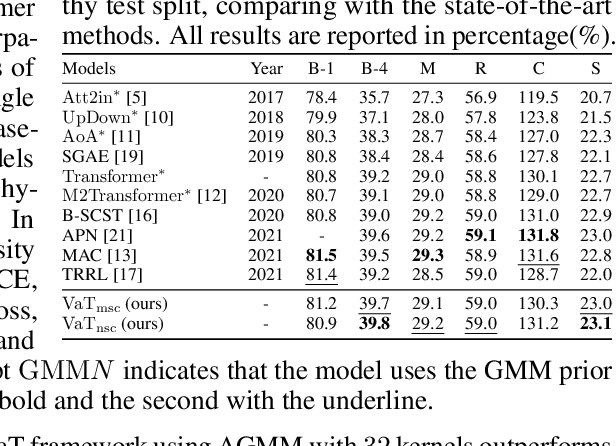
Accuracy and Diversity are two essential metrizable manifestations in generating natural and semantically correct captions. Many efforts have been made to enhance one of them with another decayed due to the trade-off gap. However, compromise does not make the progress. Decayed diversity makes the captioner a repeater, and decayed accuracy makes it a fake advisor. In this work, we exploit a novel Variational Transformer framework to improve accuracy and diversity simultaneously. To ensure accuracy, we introduce the "Invisible Information Prior" along with the "Auto-selectable GMM" to instruct the encoder to learn the precise language information and object relation in different scenes. To ensure diversity, we propose the "Range-Median Reward" baseline to retain more diverse candidates with higher rewards during the RL-based training process. Experiments show that our method achieves the simultaneous promotion of accuracy (CIDEr) and diversity (self-CIDEr), up to 1.1 and 4.8 percent, compared with the baseline. Also, our method outperforms others under the newly proposed measurement of the trade-off gap, with at least 3.55 percent promotion.