 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLipKernel: Lipschitz-Bounded Convolutional Neural Networks via Dissipative Layers
Oct 29, 2024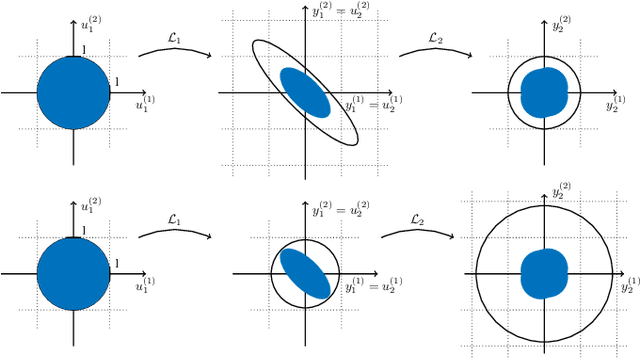
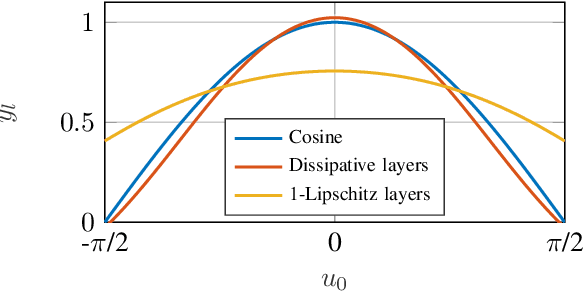
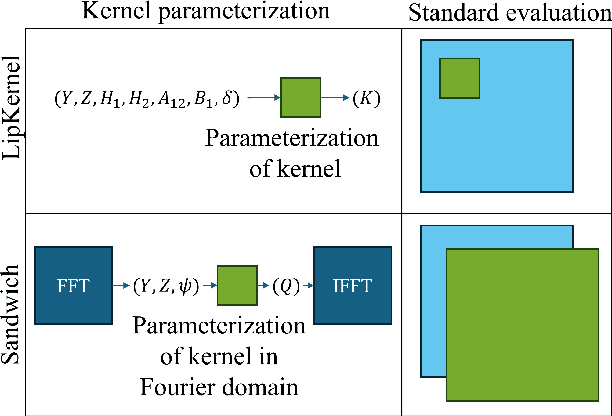
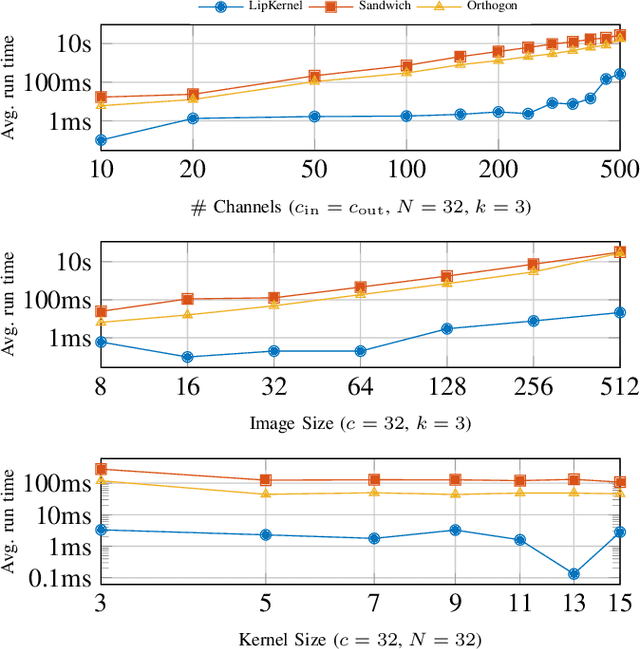
We propose a novel layer-wise parameterization for convolutional neural networks (CNNs) that includes built-in robustness guarantees by enforcing a prescribed Lipschitz bound. Each layer in our parameterization is designed to satisfy a linear matrix inequality (LMI), which in turn implies dissipativity with respect to a specific supply rate. Collectively, these layer-wise LMIs ensure Lipschitz boundedness for the input-output mapping of the neural network, yielding a more expressive parameterization than through spectral bounds or orthogonal layers. Our new method LipKernel directly parameterizes dissipative convolution kernels using a 2-D Roesser-type state space model. This means that the convolutional layers are given in standard form after training and can be evaluated without computational overhead. In numerical experiments, we show that the run-time using our method is orders of magnitude faster than state-of-the-art Lipschitz-bounded networks that parameterize convolutions in the Fourier domain, making our approach particularly attractive for improving robustness of learning-based real-time perception or control in robotics, autonomous vehicles, or automation systems. We focus on CNNs, and in contrast to previous works, our approach accommodates a wide variety of layers typically used in CNNs, including 1-D and 2-D convolutional layers, maximum and average pooling layers, as well as strided and dilated convolutions and zero padding. However, our approach naturally extends beyond CNNs as we can incorporate any layer that is incrementally dissipative.
Lipschitz constant estimation for general neural network architectures using control tools
May 02, 2024
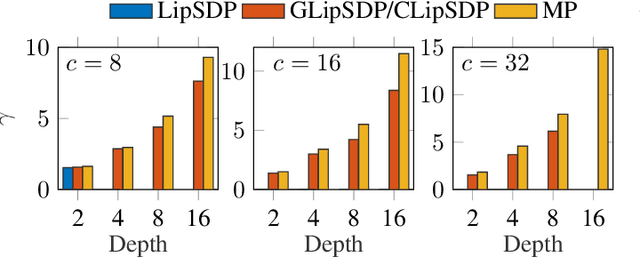
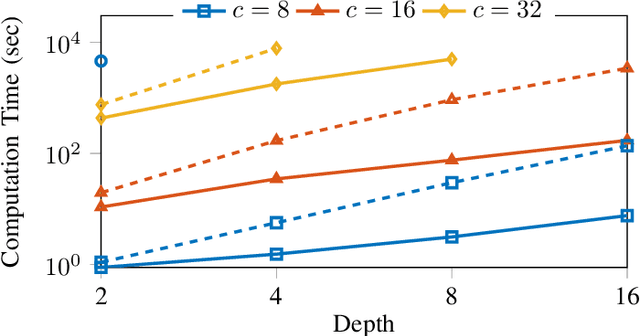
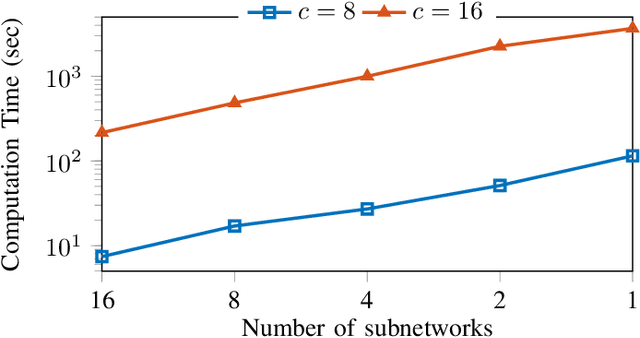
This paper is devoted to the estimation of the Lipschitz constant of neural networks using semidefinite programming. For this purpose, we interpret neural networks as time-varying dynamical systems, where the $k$-th layer corresponds to the dynamics at time $k$. A key novelty with respect to prior work is that we use this interpretation to exploit the series interconnection structure of neural networks with a dynamic programming recursion. Nonlinearities, such as activation functions and nonlinear pooling layers, are handled with integral quadratic constraints. If the neural network contains signal processing layers (convolutional or state space model layers), we realize them as 1-D/2-D/N-D systems and exploit this structure as well. We distinguish ourselves from related work on Lipschitz constant estimation by more extensive structure exploitation (scalability) and a generalization to a large class of common neural network architectures. To show the versatility and computational advantages of our method, we apply it to different neural network architectures trained on MNIST and CIFAR-10.
State space representations of the Roesser type for convolutional layers
Mar 18, 2024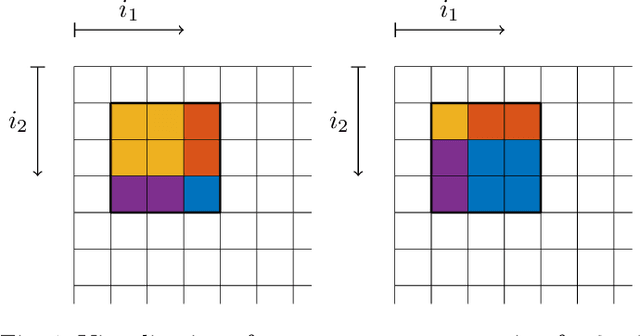
From the perspective of control theory, convolutional layers (of neural networks) are 2-D (or N-D) linear time-invariant dynamical systems. The usual representation of convolutional layers by the convolution kernel corresponds to the representation of a dynamical system by its impulse response. However, many analysis tools from control theory, e.g., involving linear matrix inequalities, require a state space representation. For this reason, we explicitly provide a state space representation of the Roesser type for 2-D convolutional layers with $c_\mathrm{in}r_1 + c_\mathrm{out}r_2$ states, where $c_\mathrm{in}$/$c_\mathrm{out}$ is the number of input/output channels of the layer and $r_1$/$r_2$ characterizes the width/length of the convolution kernel. This representation is shown to be minimal for $c_\mathrm{in} = c_\mathrm{out}$. We further construct state space representations for dilated, strided, and N-D convolutions.
Novel Quadratic Constraints for Extending LipSDP beyond Slope-Restricted Activations
Jan 25, 2024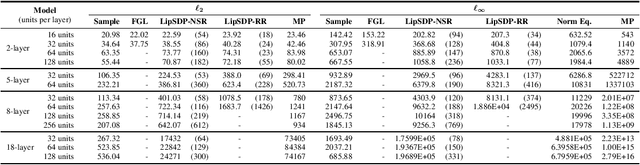


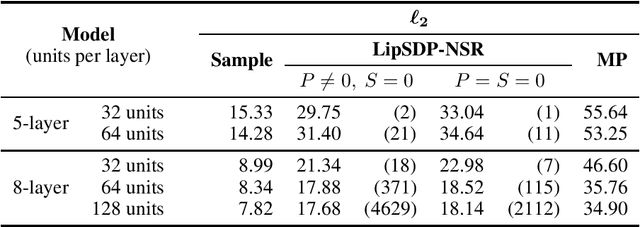
Recently, semidefinite programming (SDP) techniques have shown great promise in providing accurate Lipschitz bounds for neural networks. Specifically, the LipSDP approach (Fazlyab et al., 2019) has received much attention and provides the least conservative Lipschitz upper bounds that can be computed with polynomial time guarantees. However, one main restriction of LipSDP is that its formulation requires the activation functions to be slope-restricted on $[0,1]$, preventing its further use for more general activation functions such as GroupSort, MaxMin, and Householder. One can rewrite MaxMin activations for example as residual ReLU networks. However, a direct application of LipSDP to the resultant residual ReLU networks is conservative and even fails in recovering the well-known fact that the MaxMin activation is 1-Lipschitz. Our paper bridges this gap and extends LipSDP beyond slope-restricted activation functions. To this end, we provide novel quadratic constraints for GroupSort, MaxMin, and Householder activations via leveraging their underlying properties such as sum preservation. Our proposed analysis is general and provides a unified approach for estimating $\ell_2$ and $\ell_\infty$ Lipschitz bounds for a rich class of neural network architectures, including non-residual and residual neural networks and implicit models, with GroupSort, MaxMin, and Householder activations. Finally, we illustrate the utility of our approach with a variety of experiments and show that our proposed SDPs generate less conservative Lipschitz bounds in comparison to existing approaches.
Lipschitz-bounded 1D convolutional neural networks using the Cayley transform and the controllability Gramian
Mar 20, 2023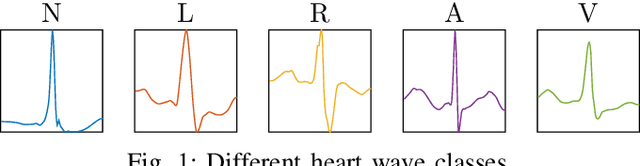
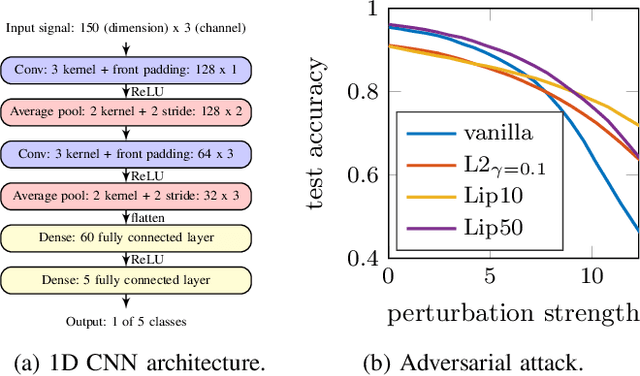
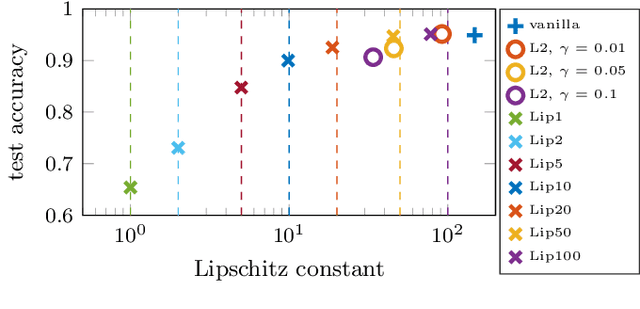
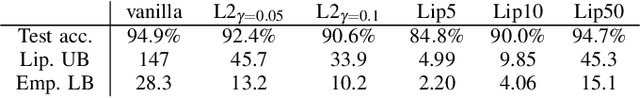
We establish a layer-wise parameterization for 1D convolutional neural networks (CNNs) with built-in end-to-end robustness guarantees. Herein, we use the Lipschitz constant of the input-output mapping characterized by a CNN as a robustness measure. We base our parameterization on the Cayley transform that parameterizes orthogonal matrices and the controllability Gramian for the state space representation of the convolutional layers. The proposed parameterization by design fulfills linear matrix inequalities that are sufficient for Lipschitz continuity of the CNN, which further enables unconstrained training of Lipschitz-bounded 1D CNNs. Finally, we train Lipschitz-bounded 1D CNNs for the classification of heart arrythmia data and show their improved robustness.
Convolutional Neural Networks as 2-D systems
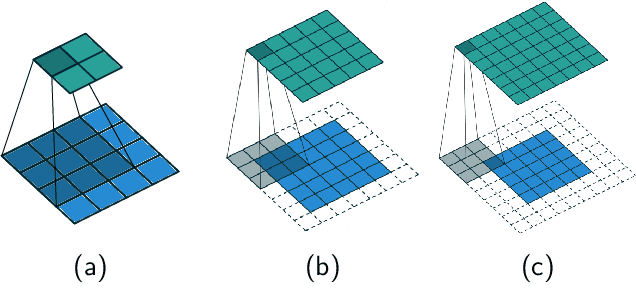
Mar 06, 2023



This paper introduces a novel representation of convolutional Neural Networks (CNNs) in terms of 2-D dynamical systems. To this end, the usual description of convolutional layers with convolution kernels, i.e., the impulse responses of linear filters, is realized in state space as a linear time-invariant 2-D system. The overall convolutional Neural Network composed of convolutional layers and nonlinear activation functions is then viewed as a 2-D version of a Lur'e system, i.e., a linear dynamical system interconnected with static nonlinear components. One benefit of this 2-D Lur'e system perspective on CNNs is that we can use robust control theory much more efficiently for Lipschitz constant estimation than previously possible.
Lipschitz constant estimation for 1D convolutional neural networks
Nov 28, 2022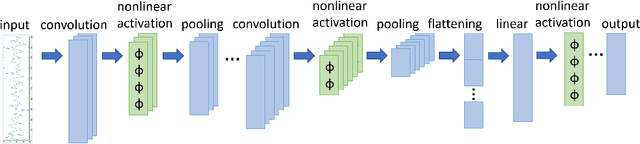

In this work, we propose a dissipativity-based method for Lipschitz constant estimation of 1D convolutional neural networks (CNNs). In particular, we analyze the dissipativity properties of convolutional, pooling, and fully connected layers making use of incremental quadratic constraints for nonlinear activation functions and pooling operations. The Lipschitz constant of the concatenation of these mappings is then estimated by solving a semidefinite program which we derive from dissipativity theory. To make our method as efficient as possible, we take the structure of convolutional layers into account realizing these finite impulse response filters as causal dynamical systems in state space and carrying out the dissipativity analysis for the state space realizations. The examples we provide show that our Lipschitz bounds are advantageous in terms of accuracy and scalability.
Neural network training under semidefinite constraints
Jan 03, 2022
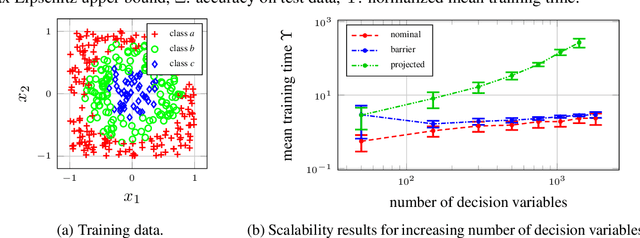

This paper is concerned with the training of neural networks (NNs) under semidefinite constraints. This type of training problems has recently gained popularity since semidefinite constraints can be used to verify interesting properties for NNs that include, e.g., the estimation of an upper bound on the Lipschitz constant, which relates to the robustness of an NN, or the stability of dynamic systems with NN controllers. The utilized semidefinite constraints are based on sector constraints satisfied by the underlying activation functions. Unfortunately, one of the biggest bottlenecks of these new results is the required computational effort for incorporating the semidefinite constraints into the training of NNs which is limiting their scalability to large NNs. We address this challenge by developing interior point methods for NN training that we implement using barrier functions for semidefinite constraints. In order to efficiently compute the gradients of the barrier terms, we exploit the structure of the semidefinite constraints. In experiments, we demonstrate the superior efficiency of our training method over previous approaches, which allows us, e.g., to use semidefinite constraints in the training of Wasserstein generative adversarial networks, where the discriminator must satisfy a Lipschitz condition.
Linear systems with neural network nonlinearities: Improved stability analysis via acausal Zames-Falb multipliers
Mar 31, 2021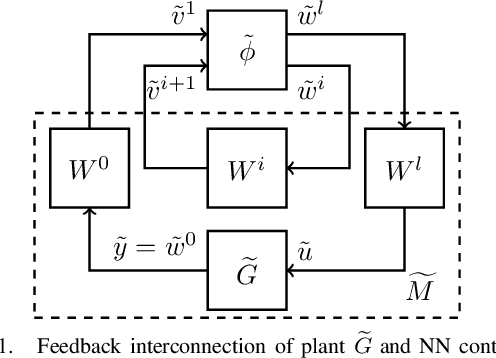
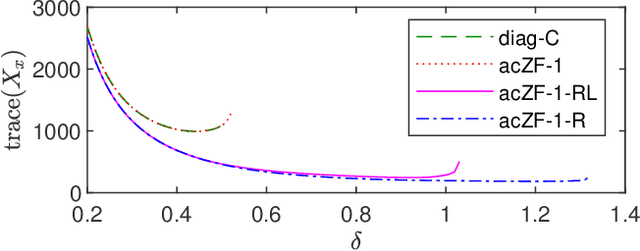
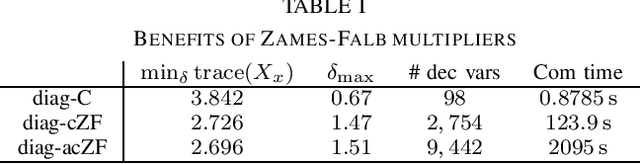
In this paper, we analyze the stability of feedback interconnections of a linear time-invariant system with a neural network nonlinearity in discrete time. Our analysis is based on abstracting neural networks using integral quadratic constraints (IQCs), exploiting the sector-bounded and slope-restricted structure of the underlying activation functions. In contrast to existing approaches, we leverage the full potential of dynamic IQCs to describe the nonlinear activation functions in a less conservative fashion. To be precise, we consider multipliers based on the full-block Yakubovich / circle criterion in combination with acausal Zames-Falb multipliers, leading to linear matrix inequality based stability certificates. Our approach provides a flexible and versatile framework for stability analysis of feedback interconnections with neural network nonlinearities, allowing to trade off computational efficiency and conservatism. Finally, we provide numerical examples that demonstrate the applicability of the proposed framework and the achievable improvements over previous approaches.
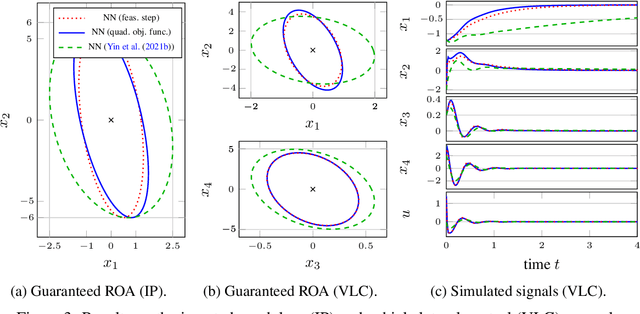
Offset-free setpoint tracking using neural network controllers
Nov 23, 2020
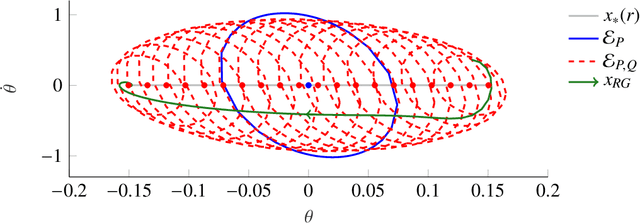
In this paper, we present a method to analyze local and global stability in offset-free setpoint tracking using neural network controllers and we provide ellipsoidal inner approximations of the corresponding region of attraction. We consider a feedback interconnection using a neural network controller in connection with an integrator, which allows for offset-free tracking of a desired piecewise constant reference that enters the controller as an external input. The feedback interconnection considered in this paper allows for general configurations of the neural network controller that include the special cases of output error and state feedback. Exploiting the fact that activation functions used in neural networks are slope-restricted, we derive linear matrix inequalities to verify stability using Lyapunov theory. After stating a global stability result, we present less conservative local stability conditions (i) for a given reference and (ii) for any reference from a certain set. The latter result even enables guaranteed tracking under setpoint changes using a reference governor which can lead to a significant increase of the region of attraction. Finally, we demonstrate the applicability of our analysis by verifying stability and offset-free tracking of a neural network controller that was trained to stabilize an inverted pendulum.