 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Iterative Hard Thresholding for Sparse Learning
Sep 02, 2024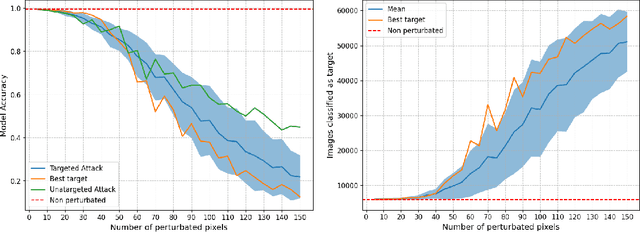

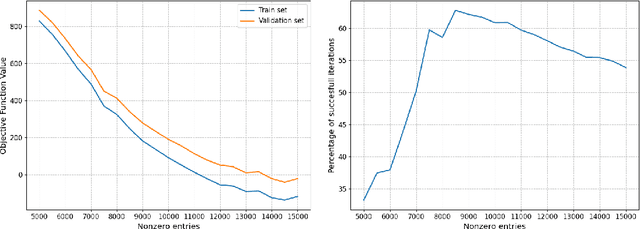
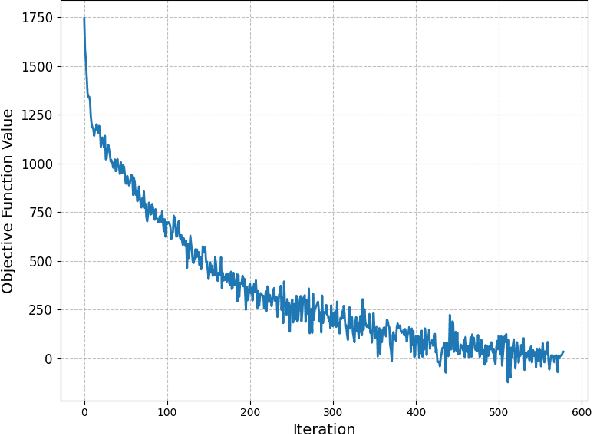
For statistical modeling wherein the data regime is unfavorable in terms of dimensionality relative to the sample size, finding hidden sparsity in the ground truth can be critical in formulating an accurate statistical model. The so-called "l0 norm" which counts the number of non-zero components in a vector, is a strong reliable mechanism of enforcing sparsity when incorporated into an optimization problem. However, in big data settings wherein noisy estimates of the gradient must be evaluated out of computational necessity, the literature is scant on methods that reliably converge. In this paper we present an approach towards solving expectation objective optimization problems with cardinality constraints. We prove convergence of the underlying stochastic process, and demonstrate the performance on two Machine Learning problems.
Learning the Right Layers: a Data-Driven Layer-Aggregation Strategy for Semi-Supervised Learning on Multilayer Graphs
May 31, 2023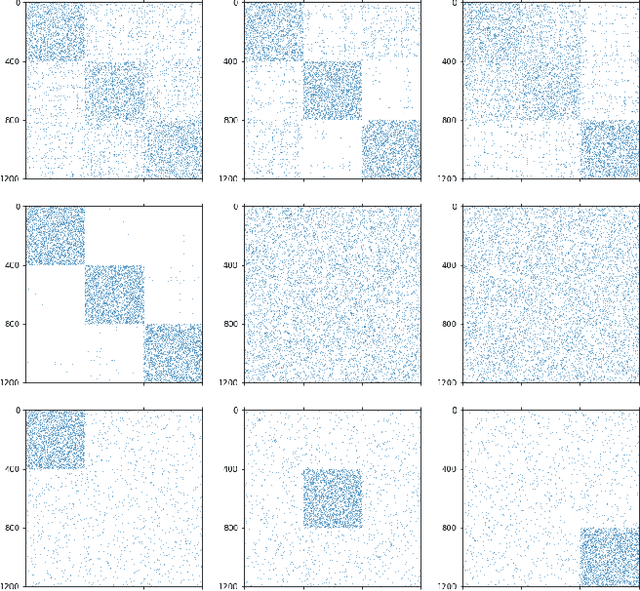
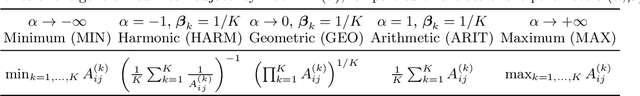
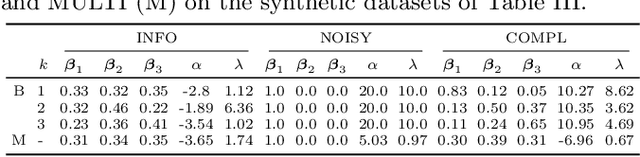
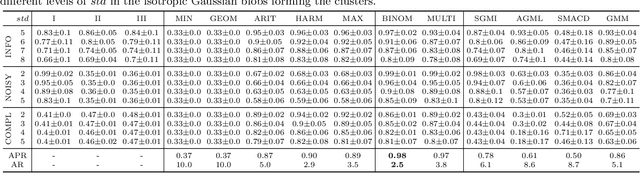
Clustering (or community detection) on multilayer graphs poses several additional complications with respect to standard graphs as different layers may be characterized by different structures and types of information. One of the major challenges is to establish the extent to which each layer contributes to the cluster assignment in order to effectively take advantage of the multilayer structure and improve upon the classification obtained using the individual layers or their union. However, making an informed a-priori assessment about the clustering information content of the layers can be very complicated. In this work, we assume a semi-supervised learning setting, where the class of a small percentage of nodes is initially provided, and we propose a parameter-free Laplacian-regularized model that learns an optimal nonlinear combination of the different layers from the available input labels. The learning algorithm is based on a Frank-Wolfe optimization scheme with inexact gradient, combined with a modified Label Propagation iteration. We provide a detailed convergence analysis of the algorithm and extensive experiments on synthetic and real-world datasets, showing that the proposed method compares favourably with a variety of baselines and outperforms each individual layer when used in isolation.
Laplacian-based Semi-Supervised Learning in Multilayer Hypergraphs by Coordinate Descent
Jan 28, 2023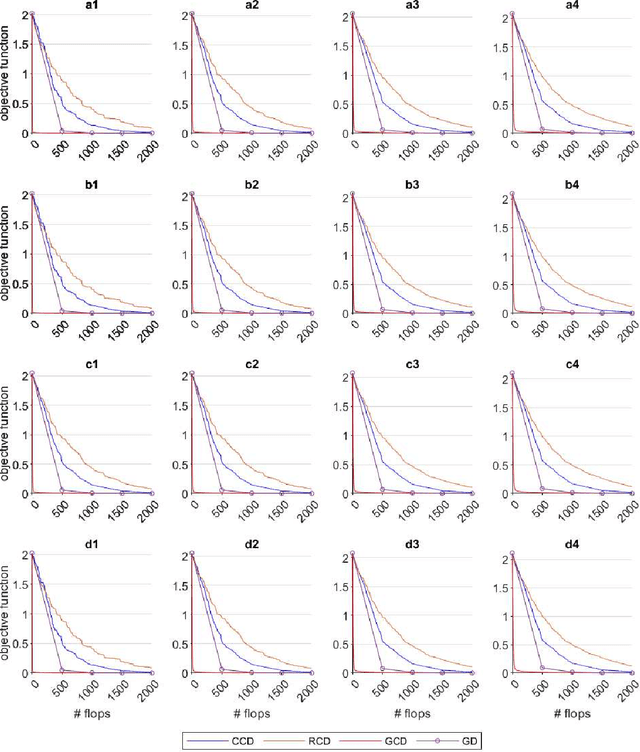
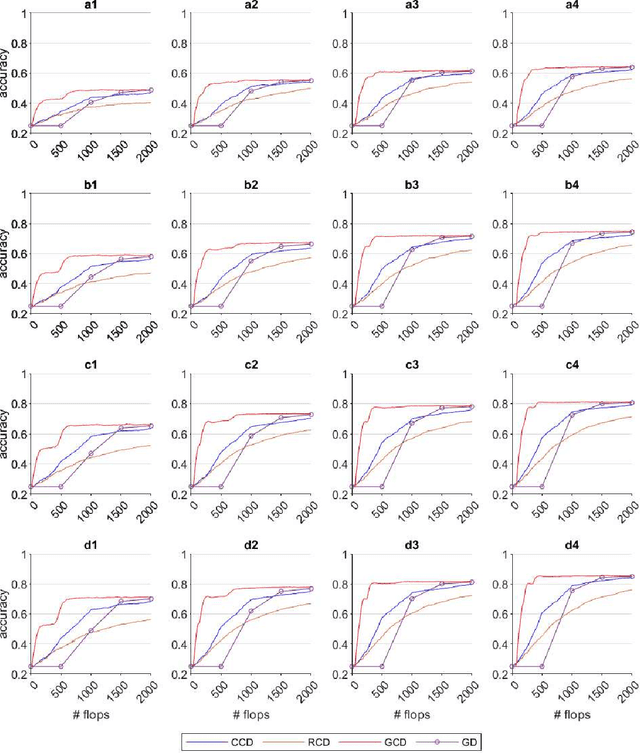
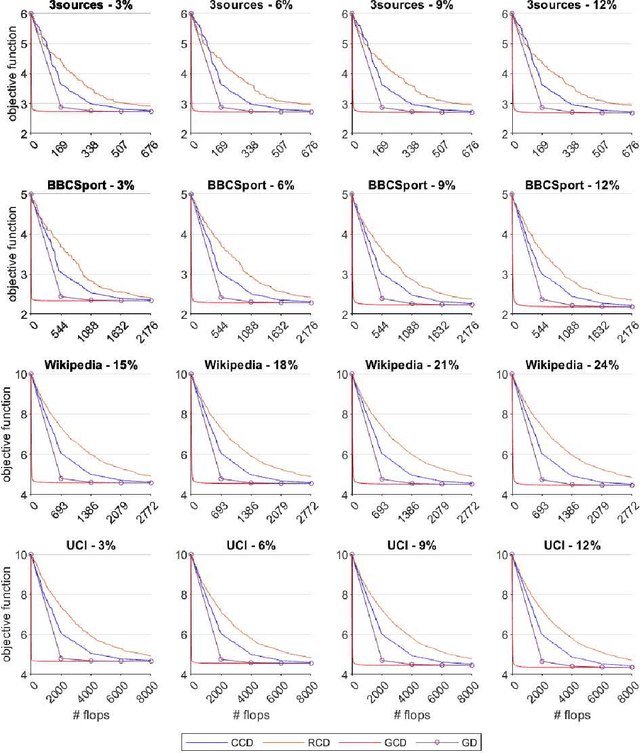
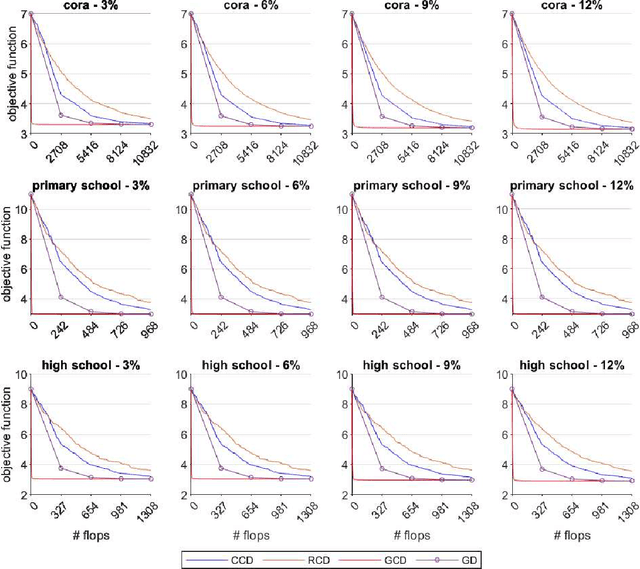
Graph Semi-Supervised learning is an important data analysis tool, where given a graph and a set of labeled nodes, the aim is to infer the labels to the remaining unlabeled nodes. In this paper, we start by considering an optimization-based formulation of the problem for an undirected graph, and then we extend this formulation to multilayer hypergraphs. We solve the problem using different coordinate descent approaches and compare the results with the ones obtained by the classic gradient descent method. Experiments on synthetic and real-world datasets show the potential of using coordinate descent methods with suitable selection rules.
Data Filtering for Cluster Analysis by $\ell_0$-Norm Regularization
May 22, 2017
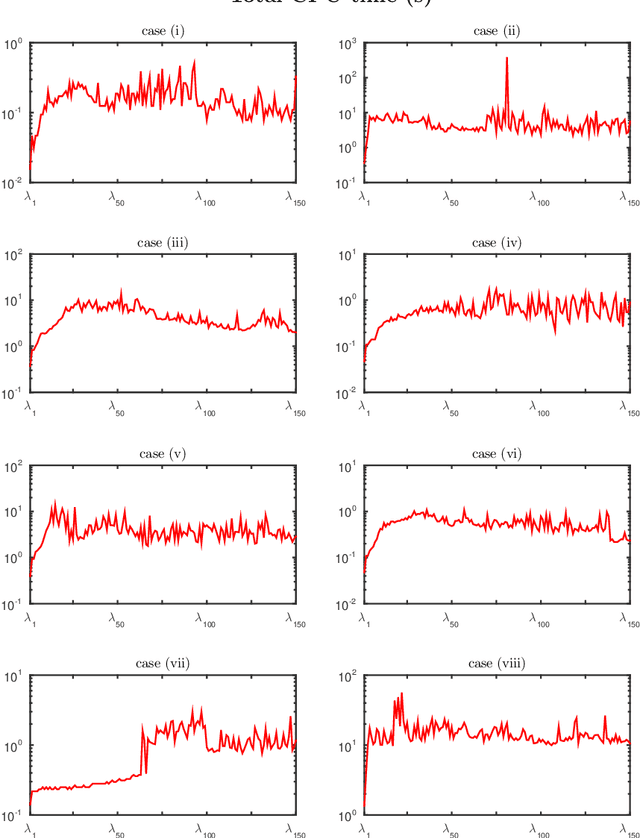

A data filtering method for cluster analysis is proposed, based on minimizing a least squares function with a weighted $\ell_0$-norm penalty. To overcome the discontinuity of the objective function, smooth non-convex functions are employed to approximate the $\ell_0$-norm. The convergence of the global minimum points of the approximating problems towards global minimum points of the original problem is stated. The proposed method also exploits a suitable technique to choose the penalty parameter. Numerical results on synthetic and real data sets are finally provided, showing how some existing clustering methods can take advantages from the proposed filtering strategy.