 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParrot: Enhancing Multi-Turn Chat Models by Learning to Ask Questions
Oct 11, 2023
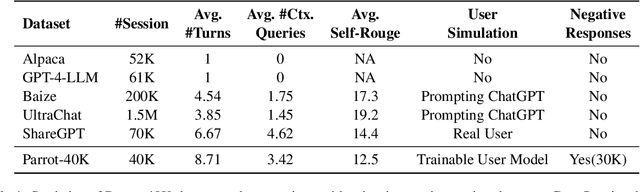


Impressive progress has been made on chat models based on Large Language Models (LLMs) recently; however, there is a noticeable lag in multi-turn conversations between open-source chat models (e.g., Alpaca and Vicuna) and the leading chat models (e.g., ChatGPT and GPT-4). Through a series of analyses, we attribute the lag to the lack of enough high-quality multi-turn instruction-tuning data. The available instruction-tuning data for the community are either single-turn conversations or multi-turn ones with certain issues, such as non-human-like instructions, less detailed responses, or rare topic shifts. In this paper, we address these challenges by introducing Parrot, a highly scalable solution designed to automatically generate high-quality instruction-tuning data, which are then used to enhance the effectiveness of chat models in multi-turn conversations. Specifically, we start by training the Parrot-Ask model, which is designed to emulate real users in generating instructions. We then utilize Parrot-Ask to engage in multi-turn conversations with ChatGPT across a diverse range of topics, resulting in a collection of 40K high-quality multi-turn dialogues (Parrot-40K). These data are subsequently employed to train a chat model that we have named Parrot-Chat. We demonstrate that the dialogues gathered from Parrot-Ask markedly outperform existing multi-turn instruction-following datasets in critical metrics, including topic diversity, number of turns, and resemblance to human conversation. With only 40K training examples, Parrot-Chat achieves strong performance against other 13B open-source models across a range of instruction-following benchmarks, and particularly excels in evaluations of multi-turn capabilities. We make all codes, datasets, and two versions of the Parrot-Ask model based on LLaMA2-13B and KuaiYii-13B available at https://github.com/kwai/KwaiYii/Parrot.
Dynamic Multi-scale Convolution for Dialect Identification
Aug 02, 2021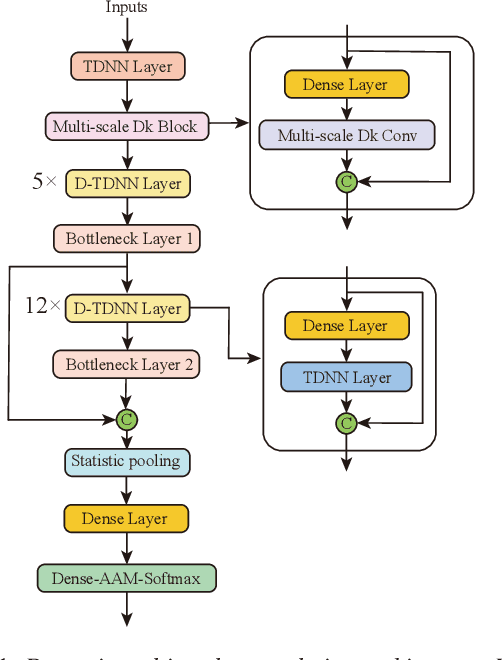

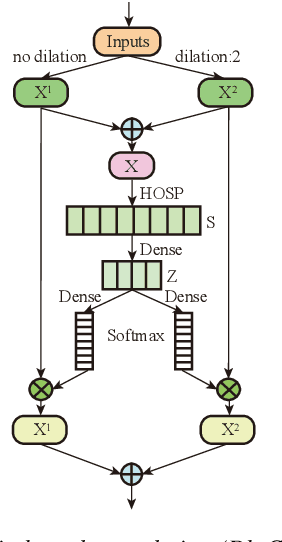

Time Delay Neural Networks (TDNN)-based methods are widely used in dialect identification. However, in previous work with TDNN application, subtle variant is being neglected in different feature scales. To address this issue, we propose a new architecture, named dynamic multi-scale convolution, which consists of dynamic kernel convolution, local multi-scale learning, and global multi-scale pooling. Dynamic kernel convolution captures features between short-term and long-term context adaptively. Local multi-scale learning, which represents multi-scale features at a granular level, is able to increase the range of receptive fields for convolution operation. Besides, global multi-scale pooling is applied to aggregate features from different bottleneck layers in order to collect information from multiple aspects. The proposed architecture significantly outperforms state-of-the-art system on the AP20-OLR-dialect-task of oriental language recognition (OLR) challenge 2020, with the best average cost performance (Cavg) of 0.067 and the best equal error rate (EER) of 6.52%. Compared with the known best results, our method achieves 9% of Cavg and 45% of EER relative improvement, respectively. Furthermore, the parameters of proposed model are 91% fewer than the best known model.