 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive-X+: Clustering in the Consensus Space
Mar 25, 2021
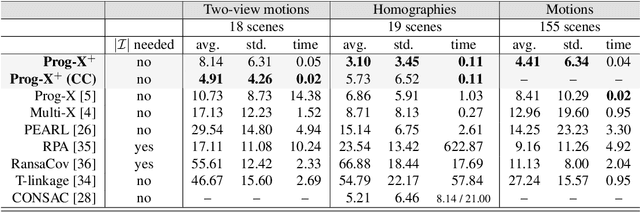

We propose Progressive-X+, a new algorithm for finding an unknown number of geometric models, e.g., homographies. The problem is formalized as finding dominant model instances progressively without forming crisp point-to-model assignments. Dominant instances are found via RANSAC-like sampling and a consolidation process driven by a model quality function considering previously proposed instances. New ones are found by clustering in the consensus space. This new formulation leads to a simple iterative algorithm with state-of-the-art accuracy while running in real-time on a number of vision problems. Also, we propose a sampler reflecting the fact that real-world data tend to form spatially coherent structures. The sampler returns connected components in a progressively growing neighborhood-graph. We present a number of applications where the use of multiple geometric models improves accuracy. These include using multiple homographies to estimate relative poses for global SfM; pose estimation from generalized homographies; and trajectory estimation of fast-moving objects.
Efficient Initial Pose-graph Generation for Global SfM
Nov 26, 2020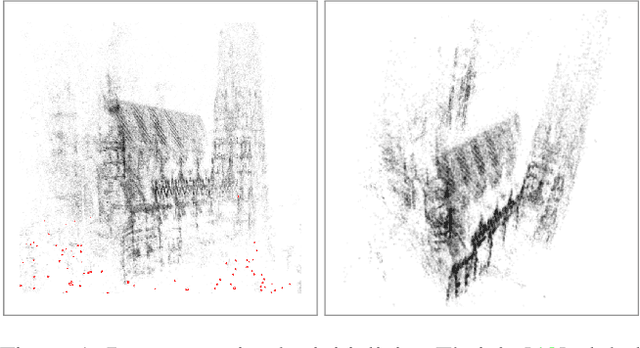

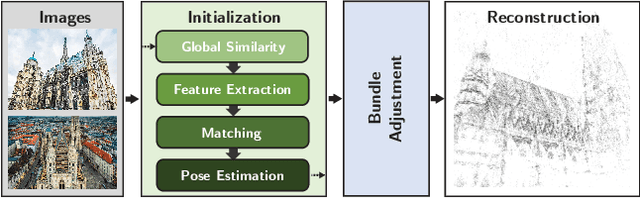
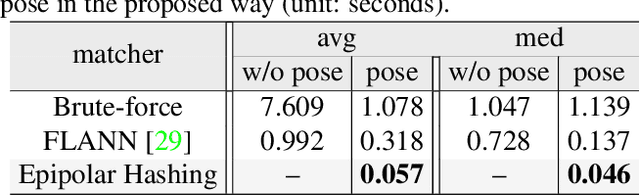
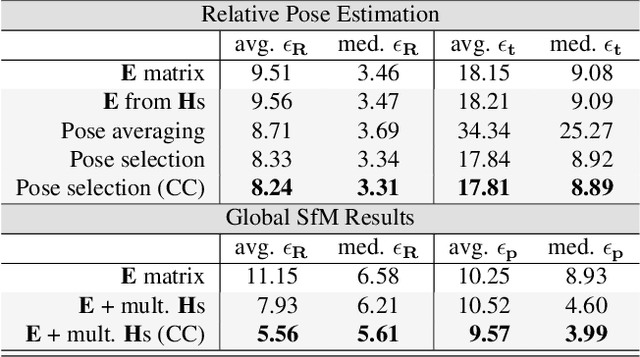
We propose ways to speed up the initial pose-graph generation for global Structure-from-Motion algorithms. To avoid forming tentative point correspondences by FLANN and geometric verification by RANSAC, which are the most time-consuming steps of the pose-graph creation, we propose two new methods - built on the fact that image pairs usually are matched consecutively. Thus, candidate relative poses can be recovered from paths in the partly-built pose-graph. We propose a heuristic for the A* traversal, considering global similarity of images and the quality of the pose-graph edges. Given a relative pose from a path, descriptor-based feature matching is made "light-weight" by exploiting the known epipolar geometry. To speed up PROSAC-based sampling when RANSAC is applied, we propose a third method to order the correspondences by their inlier probabilities from previous estimations. The algorithms are tested on 402130 image pairs from the 1DSfM dataset and they speed up the feature matching 17 times and pose estimation 5 times.
Relative Pose from Deep Learned Depth and a Single Affine Correspondence
Jul 20, 2020

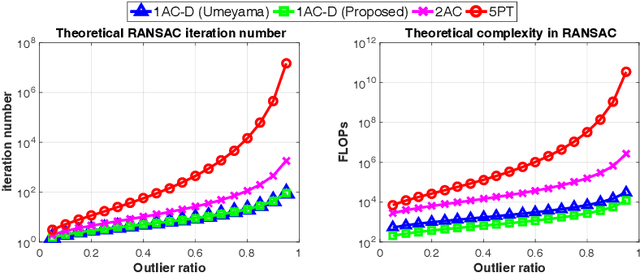

We propose a new approach for combining deep-learned non-metric monocular depth with affine correspondences (ACs) to estimate the relative pose of two calibrated cameras from a single correspondence. Considering the depth information and affine features, two new constraints on the camera pose are derived. The proposed solver is usable within 1-point RANSAC approaches. Thus, the processing time of the robust estimation is linear in the number of correspondences and, therefore, orders of magnitude faster than by using traditional approaches. The proposed 1AC+D solver is tested both on synthetic data and on 110395 publicly available real image pairs where we used an off-the-shelf monocular depth network to provide up-to-scale depth per pixel. The proposed 1AC+D leads to similar accuracy as traditional approaches while being significantly faster. When solving large-scale problems, e.g., pose-graph initialization for Structure-from-Motion (SfM) pipelines, the overhead of obtaining ACs and monocular depth is negligible compared to the speed-up gained in the pairwise geometric verification, i.e., relative pose estimation. This is demonstrated on scenes from the 1DSfM dataset using a state-of-the-art global SfM algorithm. Source code: https://github.com/eivan/one-ac-pose
Optimal Multi-view Correction of Local Affine Frames
May 01, 2019

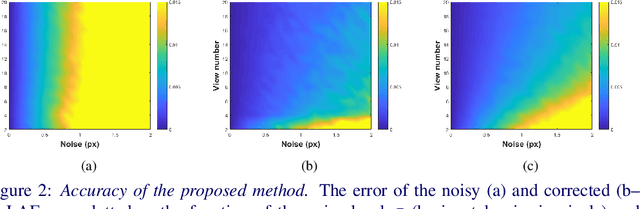
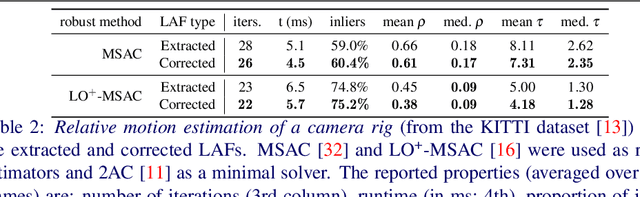
The technique requires the epipolar geometry to be pre-estimated between each image pair. It exploits the constraints which the camera movement implies, in order to apply a closed-form correction to the parameters of the input affinities. Also, it is shown that the rotations and scales obtained by partially affine-covariant detectors, e.g., AKAZE or SIFT, can be completed to be full affine frames by the proposed algorithm. It is validated both in synthetic experiments and on publicly available real-world datasets that the method always improves the output of the evaluated affine-covariant feature detectors. As a by-product, these detectors are compared and the ones obtaining the most accurate affine frames are reported. For demonstrating the applicability, we show that the proposed technique as a pre-processing step improves the accuracy of pose estimation for a camera rig, surface normal and homography estimation.