 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly Detection and Localization in Crowded Scenes by Motion-field Shape Description and Similarity-based Statistical Learning
May 27, 2018
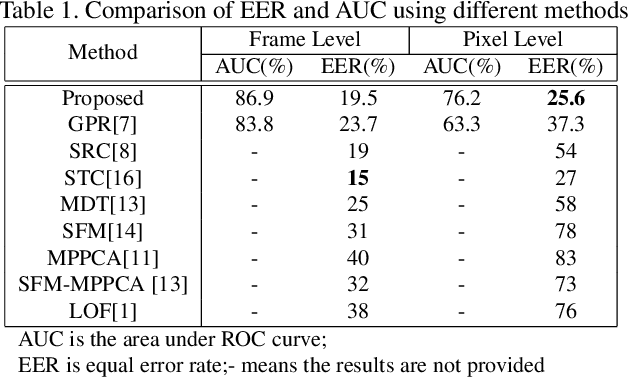


In crowded scenes, detection and localization of abnormal behaviors is challenging in that high-density people make object segmentation and tracking extremely difficult. We associate the optical flows of multiple frames to capture short-term trajectories and introduce the histogram-based shape descriptor referred to as shape contexts to describe such short-term trajectories. Furthermore, we propose a K-NN similarity-based statistical model to detect anomalies over time and space, which is an unsupervised one-class learning algorithm requiring no clustering nor any prior assumption. Firstly, we retrieve the K-NN samples from the training set in regard to the testing sample, and then use the similarities between every pair of the K-NN samples to construct a Gaussian model. Finally, the probabilities of the similarities from the testing sample to the K-NN samples under the Gaussian model are calculated in the form of a joint probability. Abnormal events can be detected by judging whether the joint probability is below predefined thresholds in terms of time and space, separately. Such a scheme can adapt to the whole scene, since the probability computed as such is not affected by motion distortions arising from perspective distortion. We conduct experiments on real-world surveillance videos, and the results demonstrate that the proposed method can reliably detect and locate the abnormal events in the video sequences, outperforming the state-of-the-art approaches.
Neural Aesthetic Image Reviewer
Feb 28, 2018
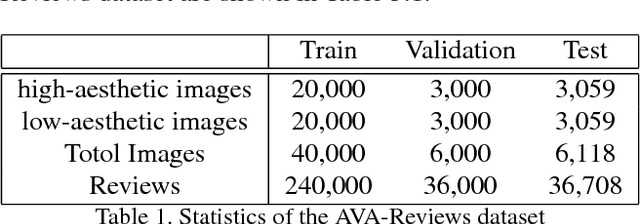
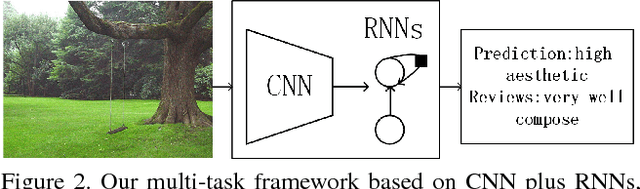

Recently, there is a rising interest in perceiving image aesthetics. The existing works deal with image aesthetics as a classification or regression problem. To extend the cognition from rating to reasoning, a deeper understanding of aesthetics should be based on revealing why a high- or low-aesthetic score should be assigned to an image. From such a point of view, we propose a model referred to as Neural Aesthetic Image Reviewer, which can not only give an aesthetic score for an image, but also generate a textual description explaining why the image leads to a plausible rating score. Specifically, we propose two multi-task architectures based on shared aesthetically semantic layers and task-specific embedding layers at a high level for performance improvement on different tasks. To facilitate researches on this problem, we collect the AVA-Reviews dataset, which contains 52,118 images and 312,708 comments in total. Through multi-task learning, the proposed models can rate aesthetic images as well as produce comments in an end-to-end manner. It is confirmed that the proposed models outperform the baselines according to the performance evaluation on the AVA-Reviews dataset. Moreover, we demonstrate experimentally that our model can generate textual reviews related to aesthetics, which are consistent with human perception.