 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified smoke and fire detection in an evolutionary framework with self-supervised progressive data augment
Feb 16, 2022

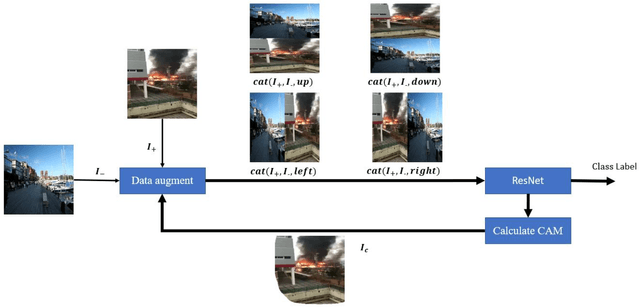
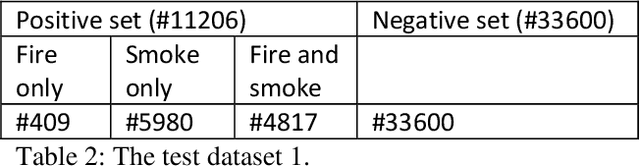
Few researches have studied simultaneous detection of smoke and flame accompanying fires due to their different physical natures that lead to uncertain fluid patterns. In this study, we collect a large image data set to re-label them as a multi-label image classification problem so as to identify smoke and flame simultaneously. In order to solve the generalization ability of the detection model on account of the movable fluid objects with uncertain shapes like fire and smoke, and their not compactible natures as well as the complex backgrounds with high variations, we propose a data augment method by random image stitch to deploy resizing, deforming, position variation, and background altering so as to enlarge the view of the learner. Moreover, we propose a self-learning data augment method by using the class activation map to extract the highly trustable region as new data source of positive examples to further enhance the data augment. By the mutual reinforcement between the data augment and the detection model that are performed iteratively, both modules make progress in an evolutionary manner. Experiments show that the proposed method can effectively improve the generalization performance of the model for concurrent smoke and fire detection.
Video Anomaly Detection By The Duality Of Normality-Granted Optical Flow
May 10, 2021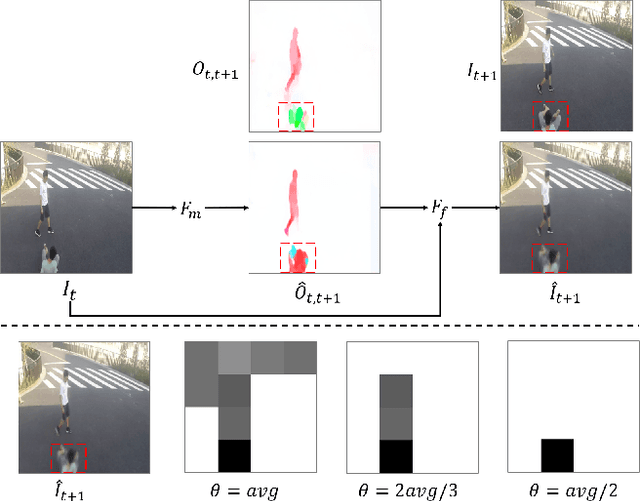
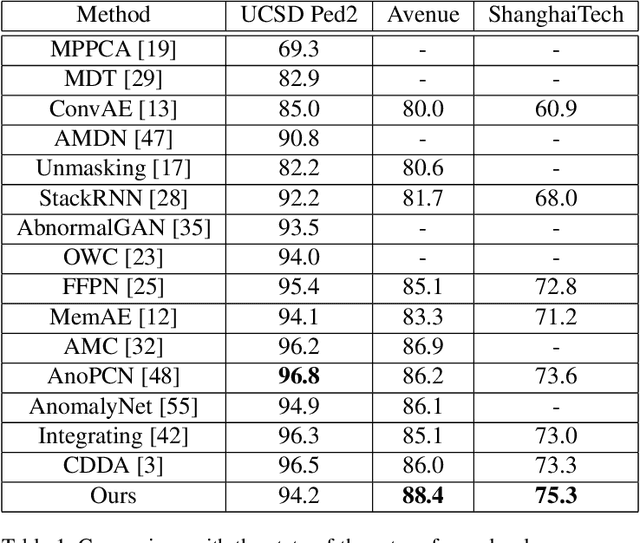
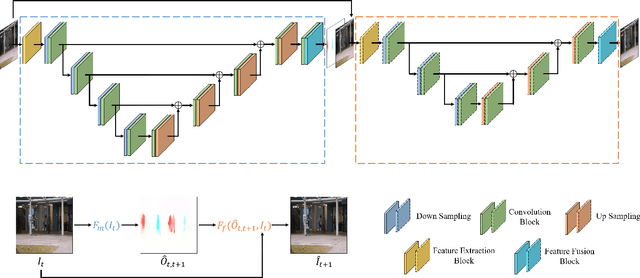
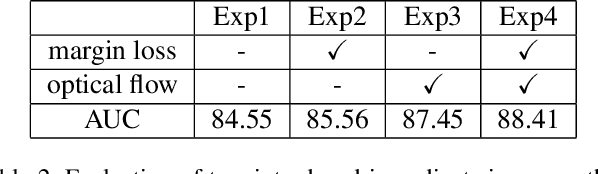
Video anomaly detection is a challenging task because of diverse abnormal events. To this task, methods based on reconstruction and prediction are wildly used in recent works, which are built on the assumption that learning on normal data, anomalies cannot be reconstructed or predicated as good as normal patterns, namely the anomaly result with more errors. In this paper, we propose to discriminate anomalies from normal ones by the duality of normality-granted optical flow, which is conducive to predict normal frames but adverse to abnormal frames. The normality-granted optical flow is predicted from a single frame, to keep the motion knowledge focused on normal patterns. Meanwhile, We extend the appearance-motion correspondence scheme from frame reconstruction to prediction, which not only helps to learn the knowledge about object appearances and correlated motion, but also meets the fact that motion is the transformation between appearances. We also introduce a margin loss to enhance the learning of frame prediction. Experiments on standard benchmark datasets demonstrate the impressive performance of our approach.