 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Metric of Automatic Weight Generation for Properties in Instance Matching Technique
Paper and Code
Feb 12, 2015
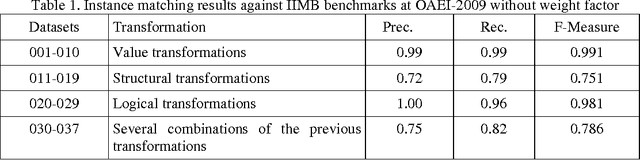
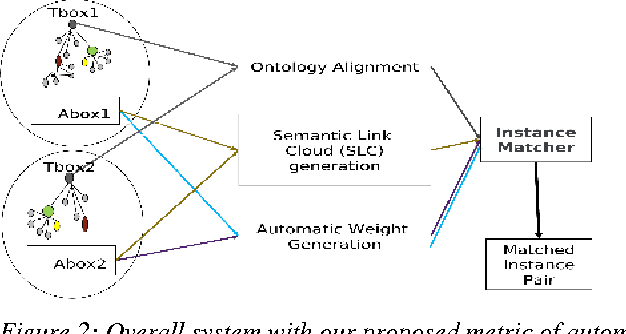
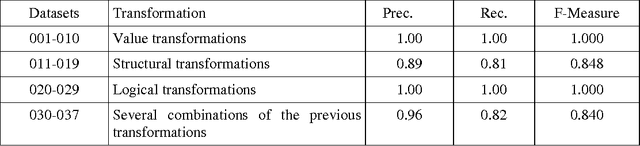
The proliferation of heterogeneous data sources of semantic knowledge base intensifies the need of an automatic instance matching technique. However, the efficiency of instance matching is often influenced by the weight of a property associated to instances. Automatic weight generation is a non-trivial, however an important task in instance matching technique. Therefore, identifying an appropriate metric for generating weight for a property automatically is nevertheless a formidable task. In this paper, we investigate an approach of generating weights automatically by considering hypotheses: (1) the weight of a property is directly proportional to the ratio of the number of its distinct values to the number of instances contain the property, and (2) the weight is also proportional to the ratio of the number of distinct values of a property to the number of instances in a training dataset. The basic intuition behind the use of our approach is the classical theory of information content that infrequent words are more informative than frequent ones. Our mathematical model derives a metric for generating property weights automatically, which is applied in instance matching system to produce re-conciliated instances efficiently. Our experiments and evaluations show the effectiveness of our proposed metric of automatic weight generation for properties in an instance matching technique.