 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeID-LoRA: Identity-Driven Audio-Video Personalization with In-Context LoRA
Mar 10, 2026Existing video personalization methods preserve visual likeness but treat video and audio separately. Without access to the visual scene, audio models cannot synchronize sounds with on-screen actions; and because classical voice-cloning models condition only on a reference recording, a text prompt cannot redirect speaking style or acoustic environment. We propose ID-LoRA (Identity-Driven In-Context LoRA), which jointly generates a subject's appearance and voice in a single model, letting a text prompt, a reference image, and a short audio clip govern both modalities together. ID-LoRA adapts the LTX-2 joint audio-video diffusion backbone via parameter-efficient In-Context LoRA and, to our knowledge, is the first method to personalize visual appearance and voice in a single generative pass. Two challenges arise. Reference and generation tokens share the same positional-encoding space, making them hard to distinguish; we address this with negative temporal positions, placing reference tokens in a disjoint RoPE region while preserving their internal temporal structure. Speaker characteristics also tend to be diluted during denoising; we introduce identity guidance, a classifier-free guidance variant that amplifies speaker-specific features by contrasting predictions with and without the reference signal. In human preference studies, ID-LoRA is preferred over Kling 2.6 Pro by 73% of annotators for voice similarity and 65% for speaking style. On cross-environment settings, speaker similarity improves by 24% over Kling, with the gap widening as conditions diverge. A preliminary user study further suggests that joint generation provides a useful inductive bias for physically grounded sound synthesis. ID-LoRA achieves these results with only ~3K training pairs on a single GPU. Code, models, and data will be released.
LiteAttention: A Temporal Sparse Attention for Diffusion Transformers
Nov 14, 2025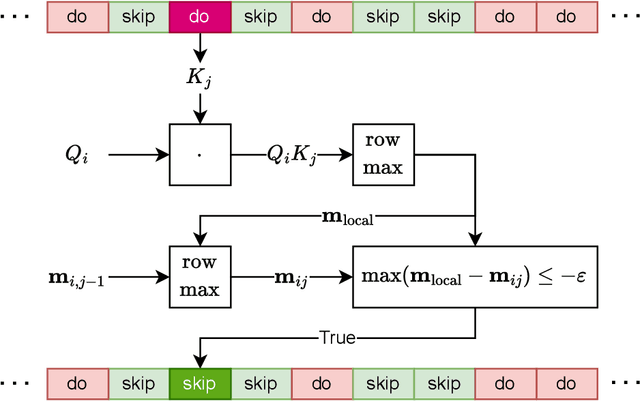



Diffusion Transformers, particularly for video generation, achieve remarkable quality but suffer from quadratic attention complexity, leading to prohibitive latency. Existing acceleration methods face a fundamental trade-off: dynamically estimating sparse attention patterns at each denoising step incurs high computational overhead and estimation errors, while static sparsity patterns remain fixed and often suboptimal throughout denoising. We identify a key structural property of diffusion attention, namely, its sparsity patterns exhibit strong temporal coherence across denoising steps. Tiles deemed non-essential at step $t$ typically remain so at step $t+δ$. Leveraging this observation, we introduce LiteAttention, a method that exploits temporal coherence to enable evolutionary computation skips across the denoising sequence. By marking non-essential tiles early and propagating skip decisions forward, LiteAttention eliminates redundant attention computations without repeated profiling overheads, combining the adaptivity of dynamic methods with the efficiency of static ones. We implement a highly optimized LiteAttention kernel on top of FlashAttention and demonstrate substantial speedups on production video diffusion models, with no degradation in quality. The code and implementation details will be publicly released.
AutoSAM: Adapting SAM to Medical Images by Overloading the Prompt Encoder
Jun 10, 2023



The recently introduced Segment Anything Model (SAM) combines a clever architecture and large quantities of training data to obtain remarkable image segmentation capabilities. However, it fails to reproduce such results for Out-Of-Distribution (OOD) domains such as medical images. Moreover, while SAM is conditioned on either a mask or a set of points, it may be desirable to have a fully automatic solution. In this work, we replace SAM's conditioning with an encoder that operates on the same input image. By adding this encoder and without further fine-tuning SAM, we obtain state-of-the-art results on multiple medical images and video benchmarks. This new encoder is trained via gradients provided by a frozen SAM. For inspecting the knowledge within it, and providing a lightweight segmentation solution, we also learn to decode it into a mask by a shallow deconvolution network.