 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Segmentation via Patch-wise Polygons Prediction
Paper and Code
Dec 05, 2021
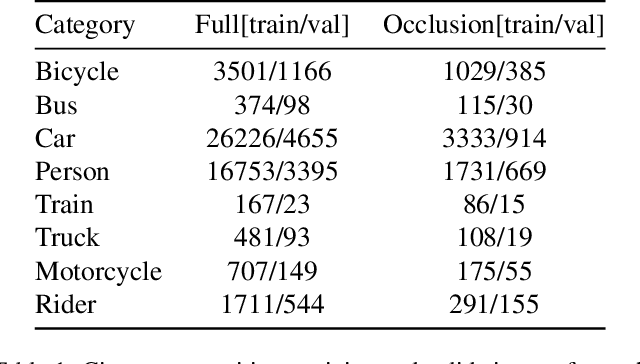
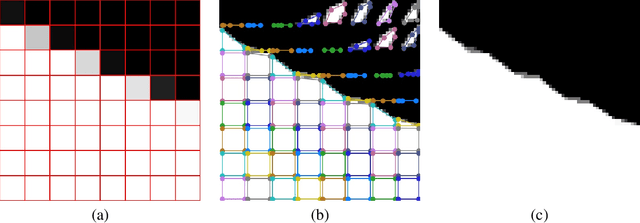
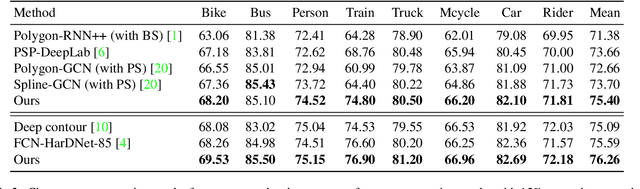
The leading segmentation methods represent the output map as a pixel grid. We study an alternative representation in which the object edges are modeled, per image patch, as a polygon with $k$ vertices that is coupled with per-patch label probabilities. The vertices are optimized by employing a differentiable neural renderer to create a raster image. The delineated region is then compared with the ground truth segmentation. Our method obtains multiple state-of-the-art results: 76.26\% mIoU on the Cityscapes validation, 90.92\% IoU on the Vaihingen building segmentation benchmark, 66.82\% IoU for the MoNU microscopy dataset, and 90.91\% for the bird benchmark CUB. Our code for training and reproducing these results is attached as supplementary.