 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenTrim: Inference-Time Token Pruning for Autoregressive Long Video Generation
Jan 30, 2026Auto-regressive video generation enables long video synthesis by iteratively conditioning each new batch of frames on previously generated content. However, recent work has shown that such pipelines suffer from severe temporal drift, where errors accumulate and amplify over long horizons. We hypothesize that this drift does not primarily stem from insufficient model capacity, but rather from inference-time error propagation. Specifically, we contend that drift arises from the uncontrolled reuse of corrupted latent conditioning tokens during auto-regressive inference. To correct this accumulation of errors, we propose a simple, inference-time method that mitigates temporal drift by identifying and removing unstable latent tokens before they are reused for conditioning. For this purpose, we define unstable tokens as latent tokens whose representations deviate significantly from those of the previously generated batch, indicating potential corruption or semantic drift. By explicitly removing corrupted latent tokens from the auto-regressive context, rather than modifying entire spatial regions or model parameters, our method prevents unreliable latent information from influencing future generation steps. As a result, it significantly improves long-horizon temporal consistency without modifying the model architecture, training procedure, or leaving latent space.
Adapting to the Unknown: Training-Free Audio-Visual Event Perception with Dynamic Thresholds
Mar 21, 2025In the domain of audio-visual event perception, which focuses on the temporal localization and classification of events across distinct modalities (audio and visual), existing approaches are constrained by the vocabulary available in their training data. This limitation significantly impedes their capacity to generalize to novel, unseen event categories. Furthermore, the annotation process for this task is labor-intensive, requiring extensive manual labeling across modalities and temporal segments, limiting the scalability of current methods. Current state-of-the-art models ignore the shifts in event distributions over time, reducing their ability to adjust to changing video dynamics. Additionally, previous methods rely on late fusion to combine audio and visual information. While straightforward, this approach results in a significant loss of multimodal interactions. To address these challenges, we propose Audio-Visual Adaptive Video Analysis ($\text{AV}^2\text{A}$), a model-agnostic approach that requires no further training and integrates a score-level fusion technique to retain richer multimodal interactions. $\text{AV}^2\text{A}$ also includes a within-video label shift algorithm, leveraging input video data and predictions from prior frames to dynamically adjust event distributions for subsequent frames. Moreover, we present the first training-free, open-vocabulary baseline for audio-visual event perception, demonstrating that $\text{AV}^2\text{A}$ achieves substantial improvements over naive training-free baselines. We demonstrate the effectiveness of $\text{AV}^2\text{A}$ on both zero-shot and weakly-supervised state-of-the-art methods, achieving notable improvements in performance metrics over existing approaches.
Classifier-Guided Captioning Across Modalities
Jan 03, 2025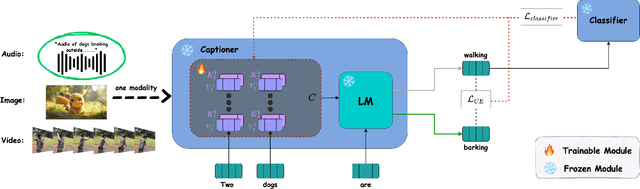
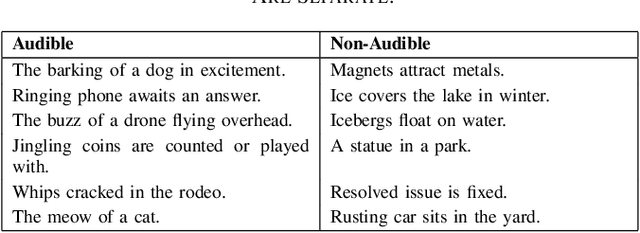
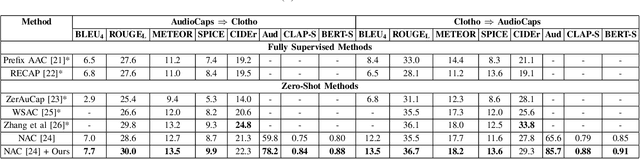
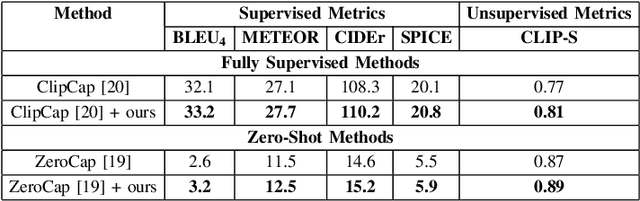
Most current captioning systems use language models trained on data from specific settings, such as image-based captioning via Amazon Mechanical Turk, limiting their ability to generalize to other modality distributions and contexts. This limitation hinders performance in tasks like audio or video captioning, where different semantic cues are needed. Addressing this challenge is crucial for creating more adaptable and versatile captioning frameworks applicable across diverse real-world contexts. In this work, we introduce a method to adapt captioning networks to the semantics of alternative settings, such as capturing audibility in audio captioning, where it is crucial to describe sounds and their sources. Our framework consists of two main components: (i) a frozen captioning system incorporating a language model (LM), and (ii) a text classifier that guides the captioning system. The classifier is trained on a dataset automatically generated by GPT-4, using tailored prompts specifically designed to enhance key aspects of the generated captions. Importantly, the framework operates solely during inference, eliminating the need for further training of the underlying captioning model. We evaluate the framework on various models and modalities, with a focus on audio captioning, and report promising results. Notably, when combined with an existing zero-shot audio captioning system, our framework improves its quality and sets state-of-the-art performance in zero-shot audio captioning.
Zero-Shot Audio Captioning via Audibility Guidance
Sep 07, 2023



The task of audio captioning is similar in essence to tasks such as image and video captioning. However, it has received much less attention. We propose three desiderata for captioning audio -- (i) fluency of the generated text, (ii) faithfulness of the generated text to the input audio, and the somewhat related (iii) audibility, which is the quality of being able to be perceived based only on audio. Our method is a zero-shot method, i.e., we do not learn to perform captioning. Instead, captioning occurs as an inference process that involves three networks that correspond to the three desired qualities: (i) A Large Language Model, in our case, for reasons of convenience, GPT-2, (ii) A model that provides a matching score between an audio file and a text, for which we use a multimodal matching network called ImageBind, and (iii) A text classifier, trained using a dataset we collected automatically by instructing GPT-4 with prompts designed to direct the generation of both audible and inaudible sentences. We present our results on the AudioCap dataset, demonstrating that audibility guidance significantly enhances performance compared to the baseline, which lacks this objective.