 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePri3D: Can 3D Priors Help 2D Representation Learning?
Paper and Code

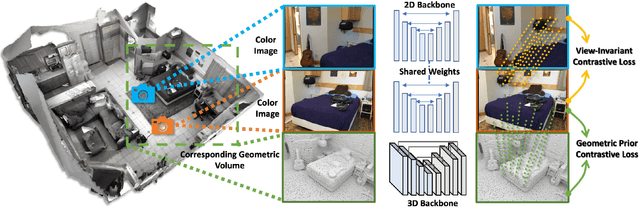

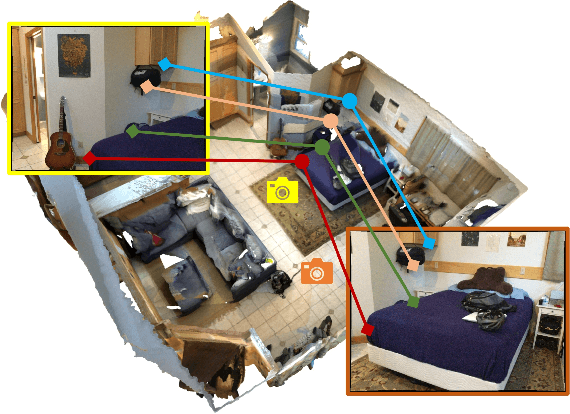
Recent advances in 3D perception have shown impressive progress in understanding geometric structures of 3Dshapes and even scenes. Inspired by these advances in geometric understanding, we aim to imbue image-based perception with representations learned under geometric constraints. We introduce an approach to learn view-invariant,geometry-aware representations for network pre-training, based on multi-view RGB-D data, that can then be effectively transferred to downstream 2D tasks. We propose to employ contrastive learning under both multi-view im-age constraints and image-geometry constraints to encode3D priors into learned 2D representations. This results not only in improvement over 2D-only representation learning on the image-based tasks of semantic segmentation, instance segmentation, and object detection on real-world in-door datasets, but moreover, provides significant improvement in the low data regime. We show a significant improvement of 6.0% on semantic segmentation on full data as well as 11.9% on 20% data against baselines on ScanNet.