 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDensePose 3D: Lifting Canonical Surface Maps of Articulated Objects to the Third Dimension
Paper and Code
Aug 31, 2021
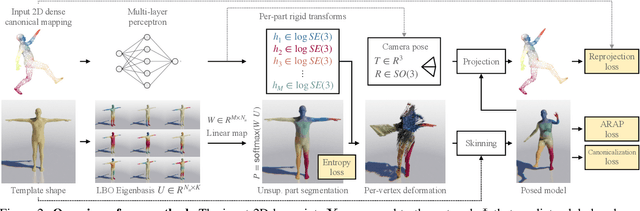


We tackle the problem of monocular 3D reconstruction of articulated objects like humans and animals. We contribute DensePose 3D, a method that can learn such reconstructions in a weakly supervised fashion from 2D image annotations only. This is in stark contrast with previous deformable reconstruction methods that use parametric models such as SMPL pre-trained on a large dataset of 3D object scans. Because it does not require 3D scans, DensePose 3D can be used for learning a wide range of articulated categories such as different animal species. The method learns, in an end-to-end fashion, a soft partition of a given category-specific 3D template mesh into rigid parts together with a monocular reconstruction network that predicts the part motions such that they reproject correctly onto 2D DensePose-like surface annotations of the object. The decomposition of the object into parts is regularized by expressing part assignments as a combination of the smooth eigenfunctions of the Laplace-Beltrami operator. We show significant improvements compared to state-of-the-art non-rigid structure-from-motion baselines on both synthetic and real data on categories of humans and animals.