 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCategory-Learning with Context-Augmented Autoencoder
Oct 10, 2020
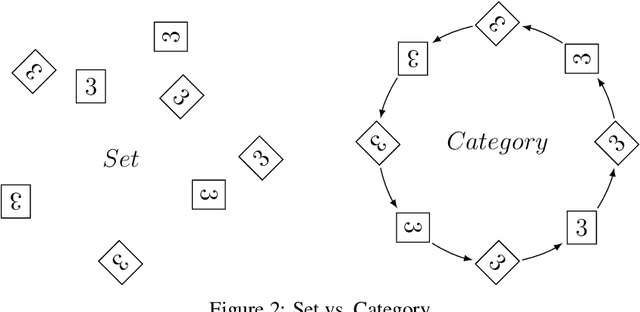
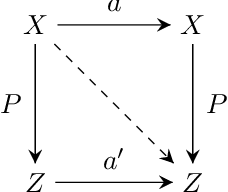
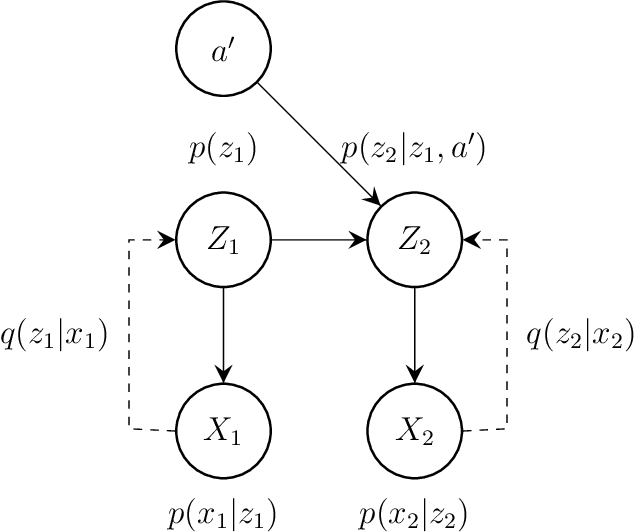
Finding an interpretable non-redundant representation of real-world data is one of the key problems in Machine Learning. Biological neural networks are known to solve this problem quite well in unsupervised manner, yet unsupervised artificial neural networks either struggle to do it or require fine tuning for each task individually. We associate this with the fact that a biological brain learns in the context of the relationships between observations, while an artificial network does not. We also notice that, though a naive data augmentation technique can be very useful for supervised learning problems, autoencoders typically fail to generalize transformations from data augmentations. Thus, we believe that providing additional knowledge about relationships between data samples will improve model's capability of finding useful inner data representation. More formally, we consider a dataset not as a manifold, but as a category, where the examples are objects. Two these objects are connected by a morphism, if they actually represent different transformations of the same entity. Following this formalism, we propose a novel method of using data augmentations when training autoencoders. We train a Variational Autoencoder in such a way, that it makes transformation outcome predictable by auxiliary network in terms of the hidden representation. We believe that the classification accuracy of a linear classifier on the learned representation is a good metric to measure its interpretability. In our experiments, present approach outperforms $\beta$-VAE and is comparable with Gaussian-mixture VAE.
* 11 pages, 12 figures