 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGetting Inspiration for Feature Elicitation: App Store- vs. LLM-based Approach
Aug 30, 2024Over the past decade, app store (AppStore)-inspired requirements elicitation has proven to be highly beneficial. Developers often explore competitors' apps to gather inspiration for new features. With the advance of Generative AI, recent studies have demonstrated the potential of large language model (LLM)-inspired requirements elicitation. LLMs can assist in this process by providing inspiration for new feature ideas. While both approaches are gaining popularity in practice, there is a lack of insight into their differences. We report on a comparative study between AppStore- and LLM-based approaches for refining features into sub-features. By manually analyzing 1,200 sub-features recommended from both approaches, we identified their benefits, challenges, and key differences. While both approaches recommend highly relevant sub-features with clear descriptions, LLMs seem more powerful particularly concerning novel unseen app scopes. Moreover, some recommended features are imaginary with unclear feasibility, which suggests the importance of a human-analyst in the elicitation loop.
On AI-Inspired UI-Design
Jun 19, 2024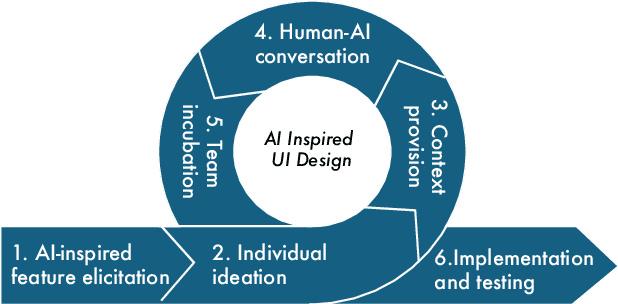


Graphical User Interface (or simply UI) is a primary mean of interaction between users and their device. In this paper, we discuss three major complementary approaches on how to use Artificial Intelligence (AI) to support app designers create better, more diverse, and creative UI of mobile apps. First, designers can prompt a Large Language Model (LLM) like GPT to directly generate and adjust one or multiple UIs. Second, a Vision-Language Model (VLM) enables designers to effectively search a large screenshot dataset, e.g. from apps published in app stores. The third approach is to train a Diffusion Model (DM) specifically designed to generate app UIs as inspirational images. We discuss how AI should be used, in general, to inspire and assist creative app design rather than automating it.
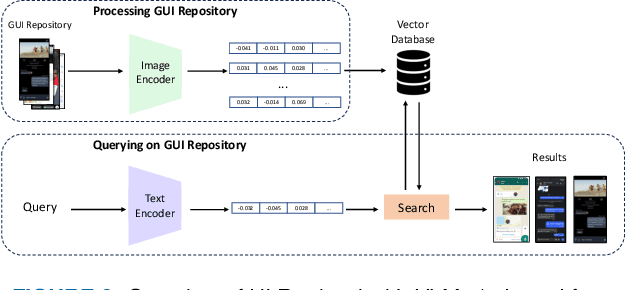
GUing: A Mobile GUI Search Engine using a Vision-Language Model
Apr 30, 2024



App developers use the Graphical User Interface (GUI) of other apps as an important source of inspiration to design and improve their own apps. In recent years, research suggested various approaches to retrieve GUI designs that fit a certain text query from screenshot datasets acquired through automated GUI exploration. However, such text-to-GUI retrieval approaches only leverage the textual information of the GUI elements in the screenshots, neglecting visual information such as icons or background images. In addition, the retrieved screenshots are not steered by app developers and often lack important app features, e.g. whose UI pages require user authentication. To overcome these limitations, this paper proposes GUing, a GUI search engine based on a vision-language model called UIClip, which we trained specifically for the app GUI domain. For this, we first collected app introduction images from Google Play, which usually display the most representative screenshots selected and often captioned (i.e. labeled) by app vendors. Then, we developed an automated pipeline to classify, crop, and extract the captions from these images. This finally results in a large dataset which we share with this paper: including 303k app screenshots, out of which 135k have captions. We used this dataset to train a novel vision-language model, which is, to the best of our knowledge, the first of its kind in GUI retrieval. We evaluated our approach on various datasets from related work and in manual experiment. The results demonstrate that our model outperforms previous approaches in text-to-GUI retrieval achieving a Recall@10 of up to 0.69 and a HIT@10 of 0.91. We also explored the performance of UIClip for other GUI tasks including GUI classification and Sketch-to-GUI retrieval with encouraging results.
Using Shallow Neural Networks with Functional Connectivity from EEG signals for Early Diagnosis of Alzheimer's and Frontotemporal Dementia
Nov 06, 2023
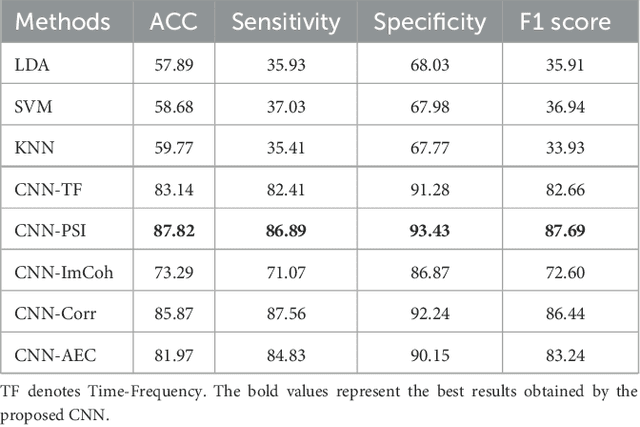

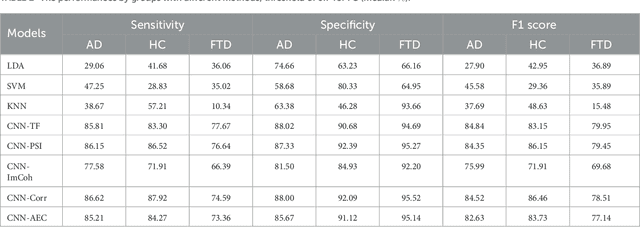
{Introduction: } Dementia is a neurological disorder associated with aging that can cause a loss of cognitive functions, impacting daily life. Alzheimer's disease (AD) is the most common cause of dementia, accounting for 50--70\% of cases, while frontotemporal dementia (FTD) affects social skills and personality. Electroencephalography (EEG) provides an effective tool to study the effects of AD on the brain. {Methods: } In this study, we propose to use shallow neural networks applied to two sets of features: spectral-temporal and functional connectivity using four methods. We compare three supervised machine learning techniques to the CNN models to classify EEG signals of AD / FTD and control cases. We also evaluate different measures of functional connectivity from common EEG frequency bands considering multiple thresholds. {Results and Discussion: } Results showed that the shallow CNN-based models achieved the highest accuracy of 94.54\% with AEC in test dataset when considering all connections, outperforming conventional methods and providing potentially an additional early dementia diagnosis tool. \url{https://doi.org/10.3389%2Ffneur.2023.1270405}
Zero-shot Bilingual App Reviews Mining with Large Language Models
Nov 06, 2023



App reviews from app stores are crucial for improving software requirements. A large number of valuable reviews are continually being posted, describing software problems and expected features. Effectively utilizing user reviews necessitates the extraction of relevant information, as well as their subsequent summarization. Due to the substantial volume of user reviews, manual analysis is arduous. Various approaches based on natural language processing (NLP) have been proposed for automatic user review mining. However, the majority of them requires a manually crafted dataset to train their models, which limits their usage in real-world scenarios. In this work, we propose Mini-BAR, a tool that integrates large language models (LLMs) to perform zero-shot mining of user reviews in both English and French. Specifically, Mini-BAR is designed to (i) classify the user reviews, (ii) cluster similar reviews together, (iii) generate an abstractive summary for each cluster and (iv) rank the user review clusters. To evaluate the performance of Mini-BAR, we created a dataset containing 6,000 English and 6,000 French annotated user reviews and conducted extensive experiments. Preliminary results demonstrate the effectiveness and efficiency of Mini-BAR in requirement engineering by analyzing bilingual app reviews. (Replication package containing the code, dataset, and experiment setups on https://github.com/Jl-wei/mini-bar )
Boosting GUI Prototyping with Diffusion Models
Jun 09, 2023GUI (graphical user interface) prototyping is a widely-used technique in requirements engineering for gathering and refining requirements, reducing development risks and increasing stakeholder engagement. However, GUI prototyping can be a time-consuming and costly process. In recent years, deep learning models such as Stable Diffusion have emerged as a powerful text-to-image tool capable of generating detailed images based on text prompts. In this paper, we propose UI-Diffuser, an approach that leverages Stable Diffusion to generate mobile UIs through simple textual descriptions and UI components. Preliminary results show that UI-Diffuser provides an efficient and cost-effective way to generate mobile GUI designs while reducing the need for extensive prototyping efforts. This approach has the potential to significantly improve the speed and efficiency of GUI prototyping in requirements engineering.
Mental arithmetic task classification with convolutional neural network based on spectral-temporal features from EEG
Sep 26, 2022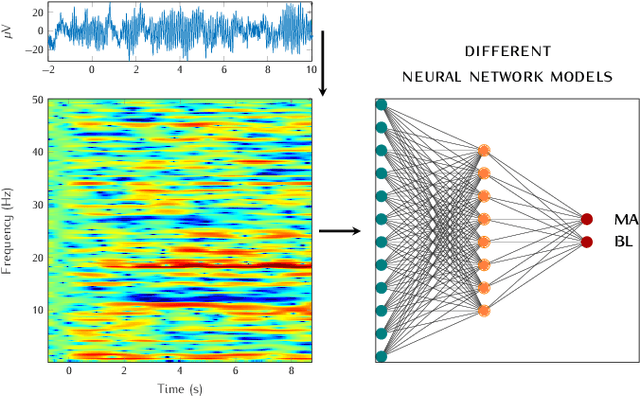
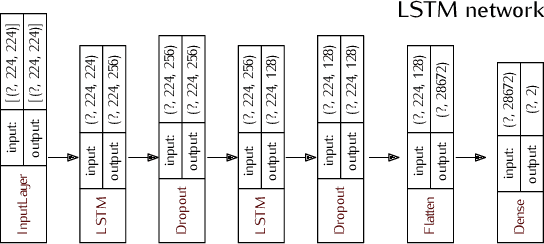
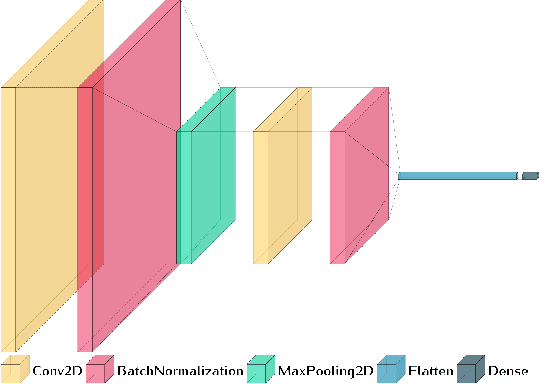
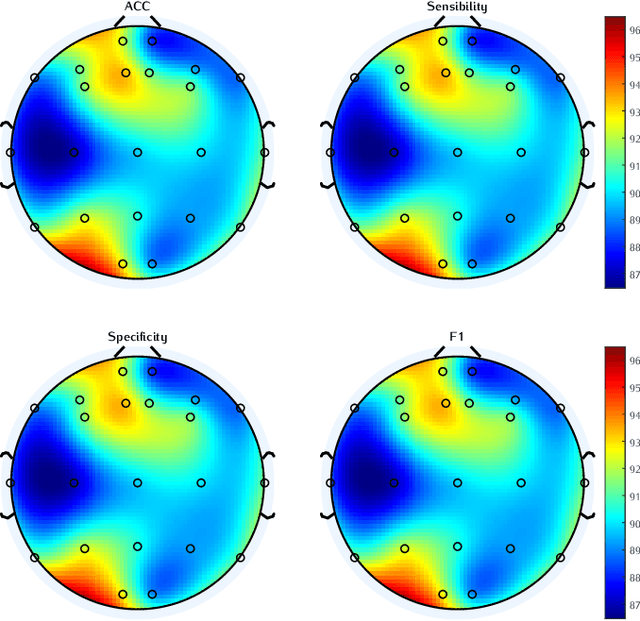
In recent years, neuroscientists have been interested to the development of brain-computer interface (BCI) devices. Patients with motor disorders may benefit from BCIs as a means of communication and for the restoration of motor functions. Electroencephalography (EEG) is one of most used for evaluating the neuronal activity. In many computer vision applications, deep neural networks (DNN) show significant advantages. Towards to ultimate usage of DNN, we present here a shallow neural network that uses mainly two convolutional neural network (CNN) layers, with relatively few parameters and fast to learn spectral-temporal features from EEG. We compared this models to three other neural network models with different depths applied to a mental arithmetic task using eye-closed state adapted for patients suffering from motor disorders and a decline in visual functions. Experimental results showed that the shallow CNN model outperformed all the other models and achieved the highest classification accuracy of 90.68%. It's also more robust to deal with cross-subject classification issues: only 3% standard deviation of accuracy instead of 15.6% from conventional method.
Towards a Data-Driven Requirements Engineering Approach: Automatic Analysis of User Reviews
Jun 29, 2022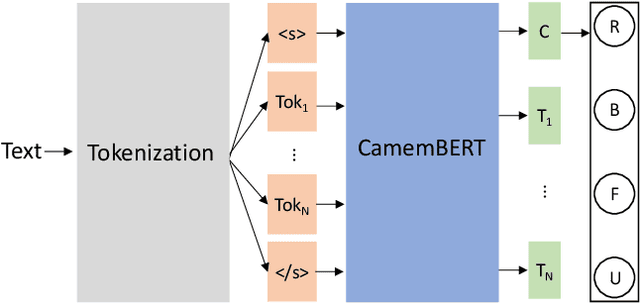

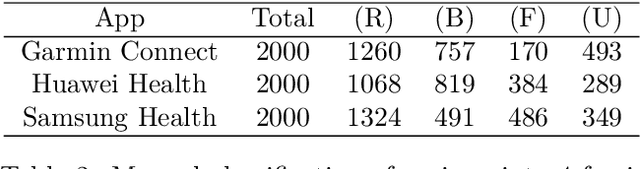

We are concerned by Data Driven Requirements Engineering, and in particular the consideration of user's reviews. These online reviews are a rich source of information for extracting new needs and improvement requests. In this work, we provide an automated analysis using CamemBERT, which is a state-of-the-art language model in French. We created a multi-label classification dataset of 6000 user reviews from three applications in the Health & Fitness field. The results are encouraging and suggest that it's possible to identify automatically the reviews concerning requests for new features. Dataset is available at: https://github.com/Jl-wei/APIA2022-French-user-reviews-classification-dataset.