 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Similarity from Natural Language and Ontology Analysis
Apr 18, 2017
Artificial Intelligence federates numerous scientific fields in the aim of developing machines able to assist human operators performing complex treatments -- most of which demand high cognitive skills (e.g. learning or decision processes). Central to this quest is to give machines the ability to estimate the likeness or similarity between things in the way human beings estimate the similarity between stimuli. In this context, this book focuses on semantic measures: approaches designed for comparing semantic entities such as units of language, e.g. words, sentences, or concepts and instances defined into knowledge bases. The aim of these measures is to assess the similarity or relatedness of such semantic entities by taking into account their semantics, i.e. their meaning -- intuitively, the words tea and coffee, which both refer to stimulating beverage, will be estimated to be more semantically similar than the words toffee (confection) and coffee, despite that the last pair has a higher syntactic similarity. The two state-of-the-art approaches for estimating and quantifying semantic similarities/relatedness of semantic entities are presented in detail: the first one relies on corpora analysis and is based on Natural Language Processing techniques and semantic models while the second is based on more or less formal, computer-readable and workable forms of knowledge such as semantic networks, thesaurus or ontologies. (...) Beyond a simple inventory and categorization of existing measures, the aim of this monograph is to convey novices as well as researchers of these domains towards a better understanding of semantic similarity estimation and more generally semantic measures.
Semantic Measures for the Comparison of Units of Language, Concepts or Instances from Text and Knowledge Base Analysis
Oct 24, 2016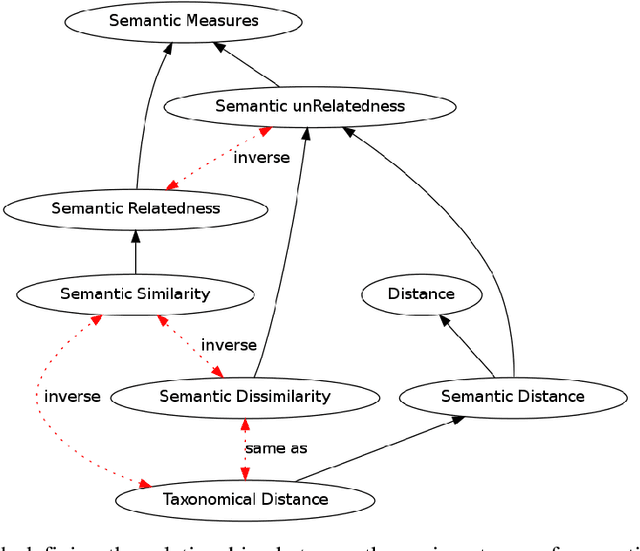
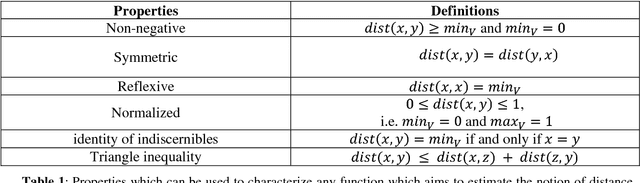

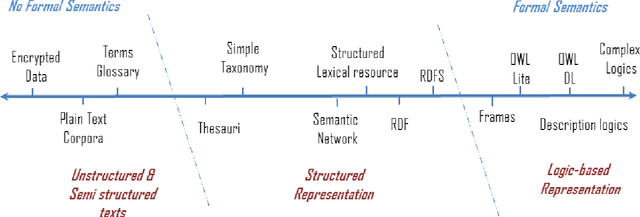
Semantic measures are widely used today to estimate the strength of the semantic relationship between elements of various types: units of language (e.g., words, sentences, documents), concepts or even instances semantically characterized (e.g., diseases, genes, geographical locations). Semantic measures play an important role to compare such elements according to semantic proxies: texts and knowledge representations, which support their meaning or describe their nature. Semantic measures are therefore essential for designing intelligent agents which will for example take advantage of semantic analysis to mimic human ability to compare abstract or concrete objects. This paper proposes a comprehensive survey of the broad notion of semantic measure for the comparison of units of language, concepts or instances based on semantic proxy analyses. Semantic measures generalize the well-known notions of semantic similarity, semantic relatedness and semantic distance, which have been extensively studied by various communities over the last decades (e.g., Cognitive Sciences, Linguistics, and Artificial Intelligence to mention a few).