 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-step registration method boosts sensitivity in longitudinal fixel-based analyses
Nov 15, 2024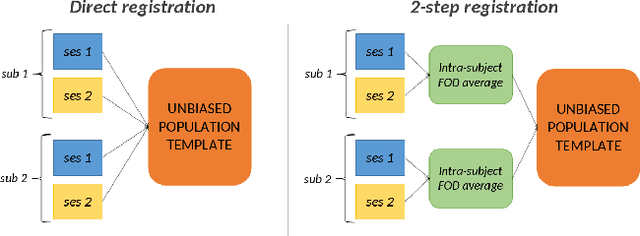
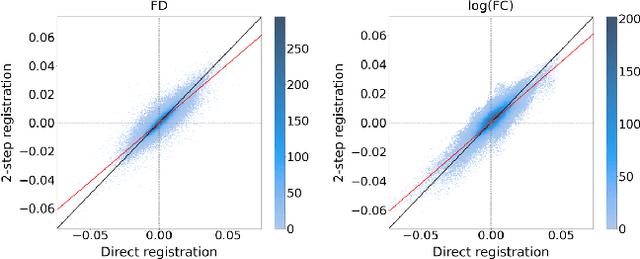

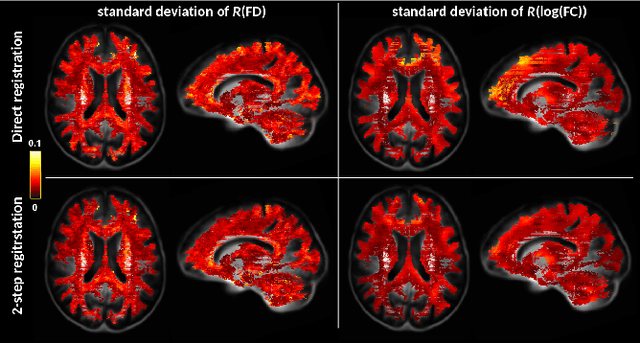
Longitudinal analyses are increasingly used in clinical studies as they allow the study of subtle changes over time within the same subjects. In most of these studies, it is necessary to align all the images studied to a common reference by registering them to a template. In the study of white matter using the recently developed fixel-based analysis (FBA) method, this registration is important, in particular because the fiber bundle cross-section metric is a direct measure of this registration. In the vast majority of longitudinal FBA studies described in the literature, sessions acquired for a same subject are directly independently registered to the template. However, it has been shown in T1-based morphometry that a 2-step registration through an intra-subject average can be advantageous in longitudinal analyses. In this work, we propose an implementation of this 2-step registration method in a typical longitudinal FBA aimed at investigating the evolution of white matter changes in Alzheimer's disease (AD). We compared at the fixel level the mean absolute effect and standard deviation yielded by this registration method and by a direct registration, as well as the results obtained with each registration method for the study of AD in both fixelwise and tract-based analyses. We found that the 2-step method reduced the variability of the measurements and thus enhanced statistical power in both types of analyses.
Transformer with Controlled Attention for Synchronous Motion Captioning
Sep 13, 2024In this paper, we address a challenging task, synchronous motion captioning, that aim to generate a language description synchronized with human motion sequences. This task pertains to numerous applications, such as aligned sign language transcription, unsupervised action segmentation and temporal grounding. Our method introduces mechanisms to control self- and cross-attention distributions of the Transformer, allowing interpretability and time-aligned text generation. We achieve this through masking strategies and structuring losses that push the model to maximize attention only on the most important frames contributing to the generation of a motion word. These constraints aim to prevent undesired mixing of information in attention maps and to provide a monotonic attention distribution across tokens. Thus, the cross attentions of tokens are used for progressive text generation in synchronization with human motion sequences. We demonstrate the superior performance of our approach through evaluation on the two available benchmark datasets, KIT-ML and HumanML3D. As visual evaluation is essential for this task, we provide a comprehensive set of animated visual illustrations in the code repository: https://github.com/rd20karim/Synch-Transformer.
Motion2Language, Unsupervised learning of synchronized semantic motion segmentation
Oct 16, 2023In this paper, we investigate building a sequence to sequence architecture for motion to language translation and synchronization. The aim is to translate motion capture inputs into English natural-language descriptions, such that the descriptions are generated synchronously with the actions performed, enabling semantic segmentation as a byproduct, but without requiring synchronized training data. We propose a new recurrent formulation of local attention that is suited for synchronous/live text generation, as well as an improved motion encoder architecture better suited to smaller data and for synchronous generation. We evaluate both contributions in individual experiments, using the standard BLEU4 metric, as well as a simple semantic equivalence measure, on the KIT motion language dataset. In a follow-up experiment, we assess the quality of the synchronization of generated text in our proposed approaches through multiple evaluation metrics. We find that both contributions to the attention mechanism and the encoder architecture additively improve the quality of generated text (BLEU and semantic equivalence), but also of synchronization. Our code will be made available at \url{https://github.com/rd20karim/M2T-Segmentation/tree/main}
Guided Attention for Interpretable Motion Captioning
Oct 11, 2023



While much effort has been invested in generating human motion from text, relatively few studies have been dedicated to the reverse direction, that is, generating text from motion. Much of the research focuses on maximizing generation quality without any regard for the interpretability of the architectures, particularly regarding the influence of particular body parts in the generation and the temporal synchronization of words with specific movements and actions. This study explores the combination of movement encoders with spatio-temporal attention models and proposes strategies to guide the attention during training to highlight perceptually pertinent areas of the skeleton in time. We show that adding guided attention with adaptive gate leads to interpretable captioning while improving performance compared to higher parameter-count non-interpretable SOTA systems. On the KIT MLD dataset, we obtain a BLEU@4 of 24.4% (SOTA+6%), a ROUGE-L of 58.30% (SOTA +14.1%), a CIDEr of 112.10 (SOTA +32.6) and a Bertscore of 41.20% (SOTA +18.20%). On HumanML3D, we obtain a BLEU@4 of 25.00 (SOTA +2.7%), a ROUGE-L score of 55.4% (SOTA +6.1%), a CIDEr of 61.6 (SOTA -10.9%), a Bertscore of 40.3% (SOTA +2.5%). Our code implementation and reproduction details will be soon available at https://github.com/rd20karim/M2T-Interpretable/tree/main.