Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Patent Mining and Relevance Classification using Transformers
May 09, 2021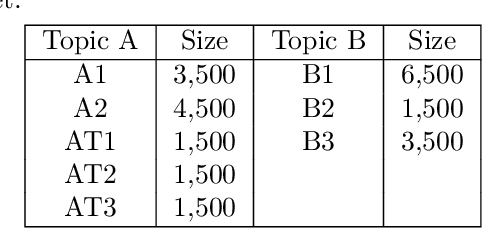

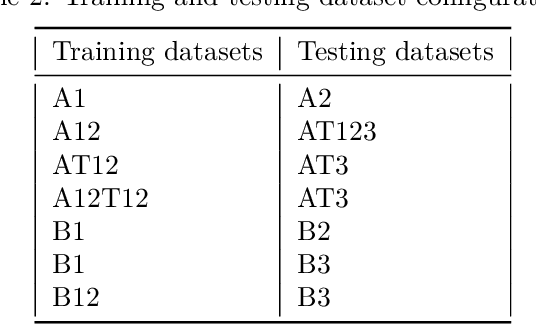
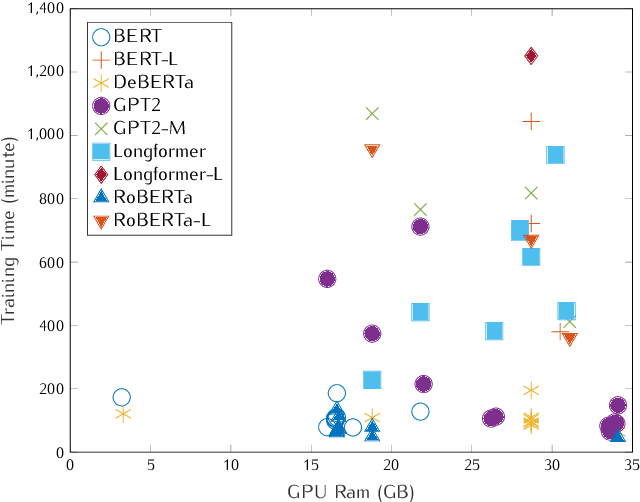
Patent analysis and mining are time-consuming and costly processes for companies, but nevertheless essential if they are willing to remain competitive. To face the overload induced by numerous patents, the idea is to automatically filter them, bringing only few to read to experts. This paper reports a successful application of fine-tuning and retraining on pre-trained deep Natural Language Processing models on patent classification. The solution that we propose combines several state-of-the-art treatments to achieve our goal - decrease the workload while preserving recall and precision metrics.
* 6th National Conference on Practical Applications of Artificial
Intelligence, 2021, Bordeaux, France
Via